
As the number of production deployments of Identity Management (IdM) grows and as many more pilots and proof of concepts come into being, it becomes (more and more) important to talk about best practices. Every production deployment needs to deal with things like failover, scalability, and performance. In turn, there are a few practical questions that need to be answered, namely:
- How many replicas do I need?
- How should these replicas be distributed between my datacenters?
- How should these replicas be connected to each other?
The answer to these questions depends on
the specifics of your environment. But before we dive into how to determine the answers to these questions it is important to realise that replicas (for example) N and M can have one replication agreement to replicate main identity data and another replication agreement to replicate certificate information. These two replication channels are completely independent. The reason for this is that the Certificate Authority (CA) component of IdM is optional. If you do not use it then you do not have any certificates to replicate and thus you can skip configuration of the replication topology for your CAs.
IdM is built with a general assumption that the CA component, if used, will be installed on some machines and not on others. However, practice shows that having different images or deployment scripts for different replicas is more overhead as compared to having a single full image and thus having CAs installed on every replica. If you prefer a CA on every replica then you can use the same topology for main and CA related replication agreements. Unfortunately, up until recent times, there was no tool that would allow someone to visualize the layout of your deployment and manage replication agreements in an intuitive fashion. To address this problem the FreeIPA project added a topology management tool that provides a nice graphical view. Take a look at the following demo that was shown at the Identity Management booth at Red Hat Summit (2016).
Another important challenge to consider is that not all replicas are the same - even if they each have the same components installed. The first server that you install becomes the tracker for certificates and keys and is responsible for CRL generation. Only one system in the whole deployment can bear this responsibility. This means that one should:
- Know which server was deployed first.
- If something happens to that server - transition its tracking and CRL generation responsibility to some other server.
- Make sure you know which server is now responsible for these special functions.
In the future we expect the topology user interface to help with this task - but this capability is yet not implemented.
Having covered some of the "groundwork" in terms of replication - we can now jump into a simple list of questions that will help you to determine the best parameters for your deployment.
How many datacenters do you have?
Let’s, for example, imagine that you have three datacenters in different geographies Datacenter A, Datacenter B, and Datacenter C.
How many clients do you have in each datacenter and what operating systems (and versions) do they run?
Let’s use the data in the following table for reference:
| Datacenter | Total # of Servers | Red Hat Enterprise Linux 5 | Red Hat Enterprise Linux 6 | Red Hat Enterprise Linux 7 | UNIX | Application(s) |
| A | 10K | 2K | 6K | 1K | 1K | 50 |
| B | 6K | 1K | 3K | 2K | - | - |
| C | 7K | - | 3K | 3K | 1K | 30 |
Clients can also be divided into several buckets by type:
- Caching clients - clients that use SSSD and cache a lot of information so that they do not need to query the server all the time.
- Moderate clients - clients that do not use SSSD or some other caching mechanism and query servers on every authentication (but don't query more information than they actually need).
- Chatty clients - these are the clients that do a lot of queries and don't necessarily cache information or care if they request more information than is needed.
Moderate and chatty clients may have a significant impact on your environment but, until you determine that you have such a client, you can assume that you do not have any. If you determine that some clients or applications are chatty - it might make sense to budget an extra replica or two for your datacenter(s).
The recommended clients to server ratio is about 2-3K clients per server, assuming that users authenticate multiple times over the course of the day but not every minute.
| Datacenter | Total # of Servers | Caching Clients | Moderate Clients | Chatty Clients | Replicas |
| A | 10K | 9K | 1K | 10 | 5 |
| B | 6K | 5K | 1K | 0 | 2 |
| C | 7K | 6K | 1K | 5 | 3 |
For Datacenter A we have about 9K clients that do caching well. That amounts to about 3-4 replicas. Three would be insufficient if there were many users logging in. So we will assume to employ four replicas. One extra replica should be able to serve the rest of the clients and a number of chatty applications so five looks like a good number.
For Datacenter B two replicas should be enough. If you see issues with that amount you can add another replica later.
In Datacenter C one would need a couple of replicas for caching clients and at least one for the remaining moderate and chatty clients - a total of three seems like a good number.
The whole deployment amounts to 10 replicas. As of Red Hat Enterprise Linux 7.2 topologies with up to 20 replicas are supported.
So far we have managed to answer the first two questions. The last one - about the topology - can be solved by adhering to the following rules:
- Connect a replica to at least two other replicas.
- Do not connect a replica to more than four other replicas.
Note that these first two recommendations are not hard requirements. Under some conditions it might make sense to have a single replication agreement or to have five. The maximum of four replication agreements was established as a way to prevent the replication overhead to start causing performance issues on the node and degrade its ability to serve clients.
- Connect datacenters with each other so that a datacenter is connected to at least a couple of other datacenters.
- Connect datacenters with at least a pair of replication agreements.
- Have at least two servers per datacenter.
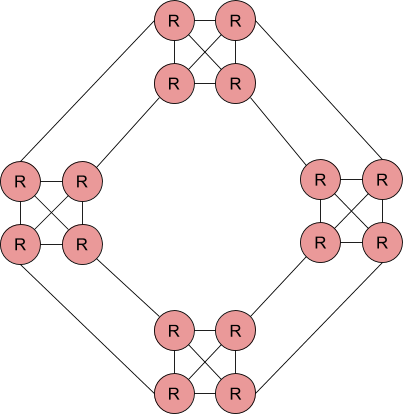
In following these rules it is quite easy to create a topology that resembles the following:

As one can see the topology meets all of the above listed guidelines.
In general, if one has datacenters of a similar size, the topology per datacenter can be the same. In fact, it might make it easier to start with the following diagram and add or remove replicas on an as needed basis.
As always - your comments, experiences, and feedback are welcome.
About the author
More like this
Physical AI: When machines start to think and act in the real world
Why prompt-level guardrails aren't enough: The platform security layers production agents need
Container Roundup | Compiler
Untangling Networks | Compiler
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds