
Single Root I/O Virtualization (SR-IOV) is a technology that allows the isolation of PCI Express (PCIe) resources for better network performance. In this article, we explore a recent study by the Red Hat OpenStack Performance and Scale team, which demonstrated the capabilities of SR-IOV using 100GbE NVIDIA ConnectX-6 adapters within a Red Hat OpenShift on Red Hat OpenStack (ShiftonStack) setup.
Unlocking peak performance
The study focused on integrating OpenShift 4.15.15 with OpenStack 17.1.2 to improve network performance for both Containerized Network Functions (CNFs) and Virtualized Network Functions (VNFs). The study aimed to achieve the following objectives, which are critical for optimizing network performance in modern datacenters:
- Throughput unleashed: Quantify the 100GbE network's throughput using SR-IOV, measured in millions of packets per second (Mpps) and gigabits per second (Gbps)
- Latency analysis: Conduct precise roundtrip latency measurements to enable microsecond-level accuracy. The results indicated a significant reduction in latency, highlighting the efficiency of SR-IOV in handling high-speed network traffic
- Performance stability: Maintain stable network performance across various frame sizes and high traffic loads
- CNFs vs. VNFs: Analyze the performance disparity between CNFs and VNFs when leveraging SR-IOV PCI passthrough
Disclaimer: This article's performance results and efficiency metrics are based on controlled tests and should serve only as guidelines. Performance may vary due to hardware, network conditions and workload characteristics. These results do not constitute a Service Level Agreement (SLA). Always perform thorough testing in your environment to validate the suitability and performance of SR-IOV with Red Hat OpenShift on OpenStack for your specific use cases. |
Test methodology
Topology: The following diagram shows the Dpdk-TestPMD (CNF) loopback setup for the Sriov Shiftonstack network performance test:
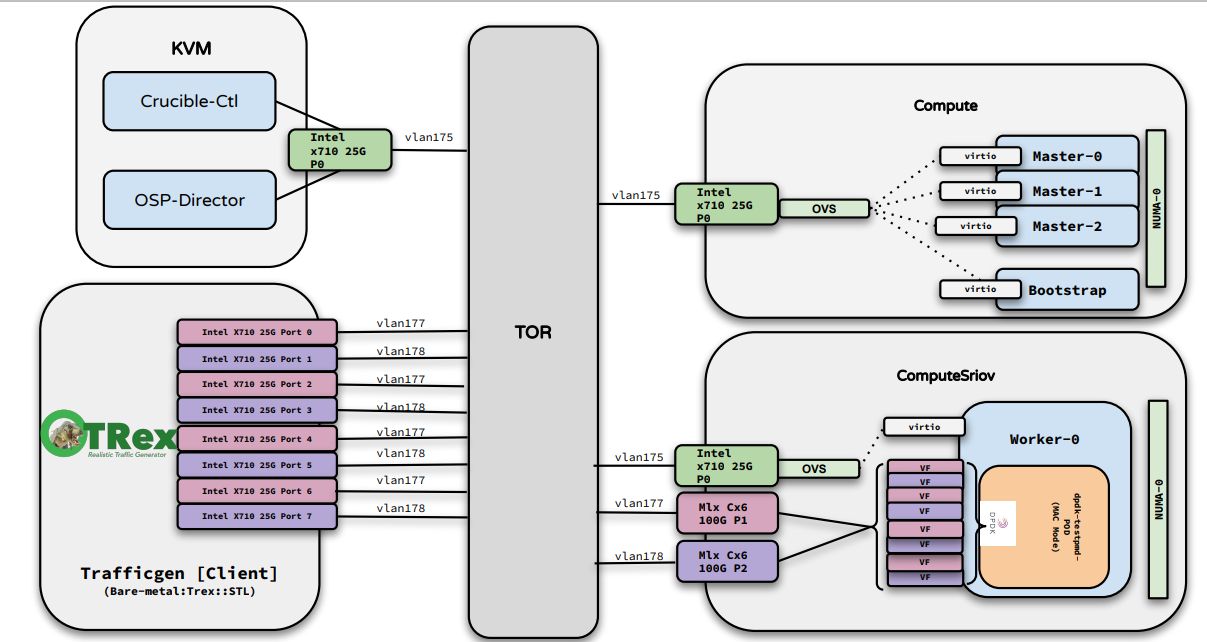
Diagram: ShiftonStack DPDK loopback network test setup
Network setup: The study employed the Crucible traffic generator benchmark using bench-trafficgen (Trex v2.7) tools. These tools are essential for simulating real-world network conditions, allowing for accurate measurement of network performance under various scenarios
Hardware configuration: Tests were conducted on the Intel IceLake compute node with Dell PowerEdge R650 server, optimized with specific BIOS and kernel parameters as per NFVi recommendations
Traffic profiles: Bidirectional traffic flows, with multiple frame sizes and latency-focused measurements, enabled a comprehensive analysis of network performance using 1K flow/sec
Configuration details
For a fair comparison, the tests were conducted using identical configurations.
Optimizing BIOS settings for SR-IOV Compute node:
Processor Settings:
Logical Processor: Enabled
CPU Interconnect Speed: Maximum data rate
Virtualization Technology: Enabled
Kernel DMS Protection: Disabled
Directory Mode: Enabled
Adjacent Cache Line Prefetch: Enabled
Hardware Prefetcher: Enabled
DCU Streamer Prefetcher: Enabled
DCU IP Prefetcher: Enabled
Sub NUMA Cluster: Disabled
MADT Core Enumeration: Round Robin
UPI Prefetch: Enabled
XPT Prefetch: Enabled
LLC Prefetch: Enabled
Dead Line LLC Alloc: Enabled
Directory AtoS: Disabled
Logical Processor Idling: Disabled
AVX P1: Normal
Intel SST-BF: Disabled
SST-Performance Profile: Operating Point 1 | P1: 2.1 GHz, TDP:195w, Core Count:36
Intel SST-CP: Disabled
x2APIC Mode: Enabled
AVX ICCP Pre-Grant License: Disabled
Dell Controlled Turbo:
Dell Controlled Turbo Setting: Disabled
Dell AVX Scaling Technology: 0
Optimizer Mode: Disabled
Number of Cores Per Processor: All
Processor Core Speed: 2.10 GHz
Processor Bus Speed: 11.2 GT/s
Local Machine Check Exception: Disabled
Family-Model-Stepping: 6-6A-6
Brand: Intel(R) Xeon(R) Platinum 8352V CPU @ 2.10GHz
Level 2 Cache: 36x1280 KB
Level 3 Cache: 54 MB
Number of Cores: 36
Maximum Memory Capacity: 6 TB
Microcode: 0xD000363
System Profile Settings:
System Profile: Custom
CPU Power Management: Maximum Performance
Memory Frequency: Maximum Performance
Turbo Boost: Disabled
C1E: Disabled
C States: Disabled
Memory Patrol Scrub: Standard
Memory Refresh Rate: 1x
Uncore Frequency: Maximum
Energy Efficient Policy: Performance
Monitor/Mwait: Enabled
Workload Profile: Not Configured
CPU Interconnect Bus Link Power Management: Disabled
PCI ASPM L1 Link Power Management: Disabled The study concluded that configuring SR-IOV compute nodes with NFV-recommended kernel boot parameters enables identical hardware synchronization between virtual machines (VMs), leading to more consistent and higher-performance network operations. These findings underscore the potential of SR-IOV in enhancing network efficiency in Red Hat OpenShift on OpenStack environments.
SR-IOV Compute Node:: Kernel Boot Parameter:
BOOT_IMAGE=(hd0,gpt3)/vmlinuz-5.14.0-284.25.1.el9_2.x86_64 root=LABEL=img-rootfs ro console=ttyS0 console=ttyS0,115200n81 no_timer_check crashkernel=1G-4G:192M,4G-64G:256M,64G-:512M default_hugepagesz=1GB hugepagesz=1G hugepages=200 iommu=pt intel_iommu=on tsc=nowatchdog isolcpus=10-71 console=ttyS0,115200 no_timer_check memtest=0 boot=LABEL=mkfs_boot skew_tick=1 nohz=on nohz_full=10-71 rcu_nocbs=10-71 tuned.non_isolcpus=000003ff intel_pstate=disable nosoftlockupSR-IOV Compute Node :: Tuned :: cpu-partitioning
# grep ^[^#] /etc/tuned/cpu-partitioning-variables.conf
isolated_cores=10-71
# tuned-adm active
Current active profile: cpu-partitioningThe Regular SRIOV- VM and the OpenShift Worker SRIOV-VM have been launched on the OpenStack cloud using the same Nova flavor.
$ openstack flavor show --fit-width sos-worker -f json
{
"OS-FLV-DISABLED:disabled": false,
"OS-FLV-EXT-DATA:ephemeral": 0,
"access_project_ids": null,
"description": null,
"disk": 100,
"id": "1111b8bc-1546-437e-b3a1-eef70d96988c",
"name": "sos-worker",
"os-flavor-access:is_public": true,
"properties": {
"hw:numa_nodes": "1",
"hw:cpu_policy": "dedicated",
"hw:mem_page_size": "1GB",
"hw:emulator_threads_policy": "isolate",
"hw:isolated_metadata": "true",
"intel11": "true"
},
"ram": 47104,
"rxtx_factor": 1.0,
"swap": "",
"vcpus": 26
}
To enable optimal network performance, the Performance Profile Creator (PPC) node tuning operator was applied to the OpenShift SR-IOV Worker VM, aiming to enhance network efficiency.
apiVersion: performance.openshift.io/v2
kind: PerformanceProfile
metadata:
name: cnf-performanceprofile
spec:
additionalKernelArgs:
- nmi_watchdog=0
- audit=0
- mce=off
- processor.max_cstate=1
- idle=poll
- intel_idle.max_cstate=0
- intel_iommu=on
- iommu=pt
- vfio.enable_unsafe_noiommu_mode=Y
cpu:
isolated: "10-25"
reserved: "0-9"
hugepages:
defaultHugepagesSize: "1G"
pages:
- count: 20
node: 0
size: 1G
nodeSelector:
node-role.kubernetes.io/worker: ''
realTimeKernel:
enabled: false
globallyDisableIrqLoadBalancing: trueIn our configuration, both SR-IOV Worker VMs and standard SR-IOV VMs are equipped with an identical setup of 8 virtual functions (VFs). These VFs are crucial in achieving high-speed performance by offering 8 peering ports for the Trafficgen client. They are systematically distributed and connected across two separate Neutron SR-IOV OpenStack provider networks. Below is an example of how Neutron ports are configured for ports associated with a SR-IOV Worker VM:
"ports": [
{
"fixedIPs": [
{
"subnetID": "a696af92-0617-40c8-9c46-02d8551d4d18"
}
],
"nameSuffix": "provider1p1",
"networkID": "e416052b-82e4-4903-830e-7d32f1d116ff",
"portSecurity": false,
"tags": [
"sriov"
],
"trunk": false,
"vnicType": "direct"
},
<..trim..> = 6 x VFs
{
"fixedIPs": [
{
"subnetID": "f9732f21-6d43-4224-b294-93d29a804ab9"
}
],
"nameSuffix": "provider2p4",
"networkID": "4fd2f250-f2e3-4767-87dd-07769026c926",
"portSecurity": false,
"tags": [
"sriov"
],
"trunk": false,
"vnicType": "direct"
}
],The OpenShift SR-IOV Network Operator has been successfully installed on a virtual OpenShift cluster. Additionally, the necessary SriovNetworkNodePolicy has been configured. These policy configurations map to two distinct OpenStack SR-IOV Neutron provider network IDs, each associated with a specific resource name and label.
{
"apiVersion": "v1",
"items": [
{
"apiVersion": "sriovnetwork.openshift.io/v1",
"kind": "SriovNetworkNodePolicy",
"metadata": {
"creationTimestamp": "2024-06-11T04:02:47Z",
"generation": 1,
"name": "provider1",
"namespace": "openshift-sriov-network-operator",
"resourceVersion": "225419",
"uid": "20b43b14-5b8c-4b2e-b54d-09117a37ca3a"
},
"spec": {
"deviceType": "netdevice",
"isRdma": true,
"nicSelector": {
"netFilter": "openstack/NetworkID:e416052b-82e4-4903-830e-7d32f1d116ff"
},
"nodeSelector": {
"feature.node.kubernetes.io/network-sriov.capable": "true"
},
"numVfs": 1,
"priority": 99,
"resourceName": "mlx_provider1"
}
},
{
"apiVersion": "sriovnetwork.openshift.io/v1",
"kind": "SriovNetworkNodePolicy",
"metadata": {
"creationTimestamp": "2024-06-11T04:02:47Z",
"generation": 1,
"name": "provider2",
"namespace": "openshift-sriov-network-operator",
"resourceVersion": "225420",
"uid": "b46288f4-2fad-43f6-a81c-bf93fdd09b78"
},
"spec": {
"deviceType": "netdevice",
"isRdma": true,
"nicSelector": {
"netFilter": "openstack/NetworkID:4fd2f250-f2e3-4767-87dd-07769026c926"
},
"nodeSelector": {
"feature.node.kubernetes.io/network-sriov.capable": "true"
},
"numVfs": 1,
"priority": 99,
"resourceName": "mlx_provider2"
}
}
],
"kind": "List",
"metadata": {
"resourceVersion": ""
}
}
The Dpdk-TestPMD CNF has been successfully deployed with adequate resources in the crucible-rickshaw namespace. This deployment is managed by the Crucible automation tool, utilizing a Kubernetes endpoint. Below are the highlighted configuration parameters of the spawned CNF.
{
"apiVersion": "v1",
"kind": "Pod",
"metadata": {
"annotations": {
"cpu-quota.crio.io": "disable",
"irq-load-balancing.crio.io": "disable",
"k8s.v1.cni.cncf.io/networks": "vlan177-provider1-p1, vlan178-provider2-p1, vlan177-provider1-p2, vlan178-provider2-p2, vlan177-provider1-p3, vlan178-provider2-p3, vlan177-provider1-p4, vlan178-provider2-p4",
"openshift.io/scc": "privileged"
},
"creationTimestamp": "2024-06-11T04:05:46Z",
"name": "rickshaw-server-1",
"namespace": "crucible-rickshaw",
"resourceVersion": "226540",
"uid": "35e74083-823d-415b-936e-0d7014a7a473"
},
"spec": {
"containers": [
{
"env": [
<..trim..>
},
{
"name": "cpu_partitioning",
"value": "1"
},
{
"name": "CONTAINER_NAME",
"value": "server-1"
}
],
"image": "quay.io/crucible/client-server:59d008e9c0f4e1298f7f03ce122d8512_x86_64",
"imagePullPolicy": "Always",
"name": "server-1",
"resources": {
"limits": {
"cpu": "10",
"hugepages-1Gi": "8Gi",
"memory": "10000Mi",
"openshift.io/mlx_provider1": "4",
"openshift.io/mlx_provider2": "4"
},
"requests": {
"cpu": "10",
"hugepages-1Gi": "8Gi",
"memory": "10000Mi",
"openshift.io/mlx_provider1": "4",
"openshift.io/mlx_provider2": "4"
}
},
"securityContext": {
"capabilities": {
"add": [
"IPC_LOCK",
"SYS_RESOURCE",
"NET_RAW",
"NET_ADMIN",
"SYS_ADMIN"
]
}
},
"terminationMessagePath": "/dev/termination-log",
"terminationMessagePolicy": "File",
"volumeMounts": [
{
"mountPath": "/lib/firmware",
"name": "hostfs-firmware"
},
{
"mountPath": "/dev/hugepages",
"name": "hugepage"
},
{
"mountPath": "/var/run/secrets/kubernetes.io/serviceaccount",
"name": "kube-api-access-zqfpq",
"readOnly": true
},
{
"mountPath": "/etc/podnetinfo",
"name": "podnetinfo",
"readOnly": true
}
]
}
],
"dnsPolicy": "ClusterFirst",
"enableServiceLinks": true,
"hostNetwork": true,
"imagePullSecrets": [
{
"name": "default-dockercfg-cb95b"
}
],
<..trim..>
"volumes": [
{
"hostPath": {
"path": "/lib/firmware",
"type": "Directory"
},
"name": "hostfs-firmware"
},
{
"emptyDir": {
"medium": "HugePages"
},
"name": "hugepage"
},
<..trim..>
{
"downwardAPI": {
"defaultMode": 420,
"items": [
{
"fieldRef": {
"apiVersion": "v1",
"fieldPath": "metadata.annotations"
},
"path": "annotations"
},
{
"path": "hugepages_1G_request_server-1",
"resourceFieldRef": {
"containerName": "server-1",
"divisor": "1Mi",
"resource": "requests.hugepages-1Gi"
}
},
{
"path": "hugepages_1G_limit_server-1",
"resourceFieldRef": {
"containerName": "server-1",
"divisor": "1Mi",
"resource": "limits.hugepages-1Gi"
}
}
]
},
"name": "podnetinfo"
}
]
},
"status": {
"conditions": [
<..trim..>
}
}
For consistency, both the Worker-VM and Regular-SRIOV-VM should have identical kernel versions and configured kernel boot parameters.
BOOT_IMAGE=(hd0,gpt3)/vmlinuz-5.14.0-284.67.1.el9_2.x86_64 root=UUID=b9819149-d15b-42cf-9199-3628c6b51bac console=tty0 console=ttyS0,115200n8 no_timer_check net.ifnames=0 crashkernel=1G-4G:192M,4G-64G:256M,64G-:512M skew_tick=1 nohz=on isolcpus=10-25 nohz_full=10-25 rcu_nocbs=10-25 tuned.non_isolcpus=000003ff intel_pstate=disable nosoftlockup default_hugepagesz=1GB hugepagesz=1G hugepages=20 iommu=pt intel_iommu=on isolcpus=10-25 ipv6.disable=1 vfio.enable_unsafe_noiommu_mode=Y nmi_watchdog=0 audit=0 mce=off processor.max_cstate=1 idle=poll intel_idle.max_cstate=0 tsc=reliable rcupdate.rcu_normal_after_boot=1 systemd.cpu_affinity=0,1,2,3,4,5,6,7,8,9 isolcpus=managed_irq,10-25 rcutree.kthread_prio=11 systemd.unified_cgroup_hierarchy=0 systemd.legacy_systemd_cgroup_controller=1CPU and Memory mapping of both Worker VM and regular VM are aligned to NUMA 0 with an identical pinning configuration in the OpenStack SR-IOV compute node.
<..trim..>
<memory unit='KiB'>48234496</memory>
<currentMemory unit='KiB'>48234496</currentMemory>
<memoryBacking>
<hugepages>
<page size='1048576' unit='KiB' nodeset='0'/>
</hugepages>
</memoryBacking>
<vcpu placement='static'>26</vcpu>
<cputune>
<vcpupin vcpu='0' cpuset='60'/>
<vcpupin vcpu='1' cpuset='66'/>
<vcpupin vcpu='2' cpuset='14'/>
<vcpupin vcpu='3' cpuset='20'/>
<vcpupin vcpu='4' cpuset='26'/>
<vcpupin vcpu='5' cpuset='32'/>
<vcpupin vcpu='6' cpuset='38'/>
<vcpupin vcpu='7' cpuset='44'/>
<vcpupin vcpu='8' cpuset='50'/>
<vcpupin vcpu='9' cpuset='56'/>
<vcpupin vcpu='10' cpuset='62'/>
<vcpupin vcpu='11' cpuset='68'/>
<vcpupin vcpu='12' cpuset='10'/>
<vcpupin vcpu='13' cpuset='16'/>
<vcpupin vcpu='14' cpuset='22'/>
<vcpupin vcpu='15' cpuset='28'/>
<vcpupin vcpu='16' cpuset='34'/>
<vcpupin vcpu='17' cpuset='40'/>
<vcpupin vcpu='18' cpuset='46'/>
<vcpupin vcpu='19' cpuset='52'/>
<vcpupin vcpu='20' cpuset='58'/>
<vcpupin vcpu='21' cpuset='64'/>
<vcpupin vcpu='22' cpuset='70'/>
<vcpupin vcpu='23' cpuset='12'/>
<vcpupin vcpu='24' cpuset='18'/>
<vcpupin vcpu='25' cpuset='24'/>
<emulatorpin cpuset='30'/>
</cputune>
<numatune>
<memory mode='strict' nodeset='0'/>
<memnode cellid='0' mode='strict' nodeset='0'/>
</numatune>
<..trim..>
<sysinfo type='smbios'>
<system>
<entry name='manufacturer'>Red Hat</entry>
<entry name='product'>OpenStack Compute</entry>
<entry name='version'>23.2.3-17.1.20231018130822.el9ost</entry>
<entry name='serial'>e92514dc-d6f5-4582-aff3-77ed78c53c12</entry>
<entry name='uuid'>e92514dc-d6f5-4582-aff3-77ed78c53c12</entry>
<entry name='family'>Virtual Machine</entry>
</system>
</sysinfo>
<..trim..>Network test process
Based on the Crucible bench-trafficgen reference guidelines, the performance test was conducted using the following Trex client traffic profile and Dpdk-TestPMD server configuration parameters.
Sample traffic profile for performance testing:
- Active Devices: 8 x 25GbE Intel X710 (Total: 200GbE)
- Flow Modification Parameters: Source IP, Destination IP
- Number of Flows: 1024
- Overall Traffic Rate: 100%
- Binary Search Algorithm: Enabled
- Latency Measurement: Enabled
- Validation Runtime: 120 seconds
- Maximum Packet Loss: 0.002
- Frame Sizes (Bytes): 64, 128, 256, 512, 1024, 2048, 4096, 8192, 9000
- Protocol: UDP
- Traffic Direction: Bidirectional
The following command configures a sample server using Dpdk-TestPMD:
$ /usr/bin/dpdk-testpmd --lcores 0@0,1@10,2@11,3@12,4@13,5@14,6@15,7@16,8@17 \
--file-prefix server-1 --socket-mem 8192 --huge-dir /dev/hugepages \
--allow 0000:05:00.0 --allow 0000:06:00.0 --allow 0000:07:00.0 --allow 0000:08:00.0 \
--allow 0000:09:00.0 --allow 0000:0a:00.0 --allow 0000:0b:00.0 --allow 0000:0c:00.0 \
-v -- --nb-ports 8 --nb-cores 8 --auto-start --stats-period=5 \
--rxq 1 --txq 1 --rxd 4096 --txd 4096 --max-pkt-len=9216 \
--record-core-cycles --record-burst-stats --rss-udp --burst=64 --mbuf-size=16384 \
--eth-peer 0,aa:aa:aa:aa:aa:ac --eth-peer 1,aa:aa:aa:aa:aa:ad \
--eth-peer 2,bb:bb:bb:bb:bb:c0 --eth-peer 3,bb:bb:bb:bb:bb:c1 \
--eth-peer 4,cc:cc:cc:cc:cc:0c --eth-peer 5,cc:cc:cc:cc:cc:0d \
--eth-peer 6,dd:dd:dd:dd:dd:50 --eth-peer 7,dd:dd:dd:dd:dd:51 \
--forward-mode macHere's an improved version of the sample Crucible command for running CNF (Containerized Network Function) performance tests:
$ crucible run trafficgen --mv-params mv-params.json \
--num-samples 3 --max-sample-failures 3 --tags PerfTest:CNF --test-order r \
--endpoint remotehost,host:$TrexHost,user:root,client:1,userenv:alma8,cpu-partitioning:client-1:1,disable-tools:1 \
--endpoint remotehost,host:$SriovCompute,user:root,profiler:1,userenv:alma8 \
--endpoint k8s,host:$OcpCluster,user:stack,server:1,userenv:alma8,cpu-partitioning:server-1:1,hugepage:1,resources:server-1:resources.json,annotations:server-1:annotations.json,securityContext:server-1:securityContext.json,hostNetwork:1Sample Crucible command for running VNF performance tests:
$ crucible run trafficgen --mv-params mv-params.json \
--num-samples 3 --max-sample-failures 3 --tags PerfTest:VNF --test-order r \
--endpoint remotehost,host:$TrexHost,user:root,client:1,userenv:alma8,cpu-partitioning:client-1:1,disable-tools:1 \
--endpoint remotehost,host:$SriovCompute,user:root,profiler:1,userenv:alma8 \
--endpoint remotehost,host:$SriovVM,user:root,server:1,userenv:alma8,cpu-partitioning:server-1:1Key findings: A performance powerhouse
The study yielded remarkable results:
Surging throughput
When evaluating the throughput between CNF and VNF, the results are determined based on packet-per-second rates. These rates are derived from the median of sample values obtained during testing. The performance benchmarks, established using a binary-search algorithm, confirm the accuracy of these results.
The data plotted represents the median values from three distinct test samples, each with a normal standard deviation. This indicates consistent performance across all Device Under Test scenarios. Consequently, the throughput performance of both CNF and VNF is nearly identical, demonstrating that both network functions can achieve similar levels of efficiency and reliability in terms of packet processing rates.
Following an extensive analysis of SR-IOV performance with both CNF and VNF, we have observed that both consistently deliver superior throughput performance at L1 and L2 Gbps across various traffic workloads.
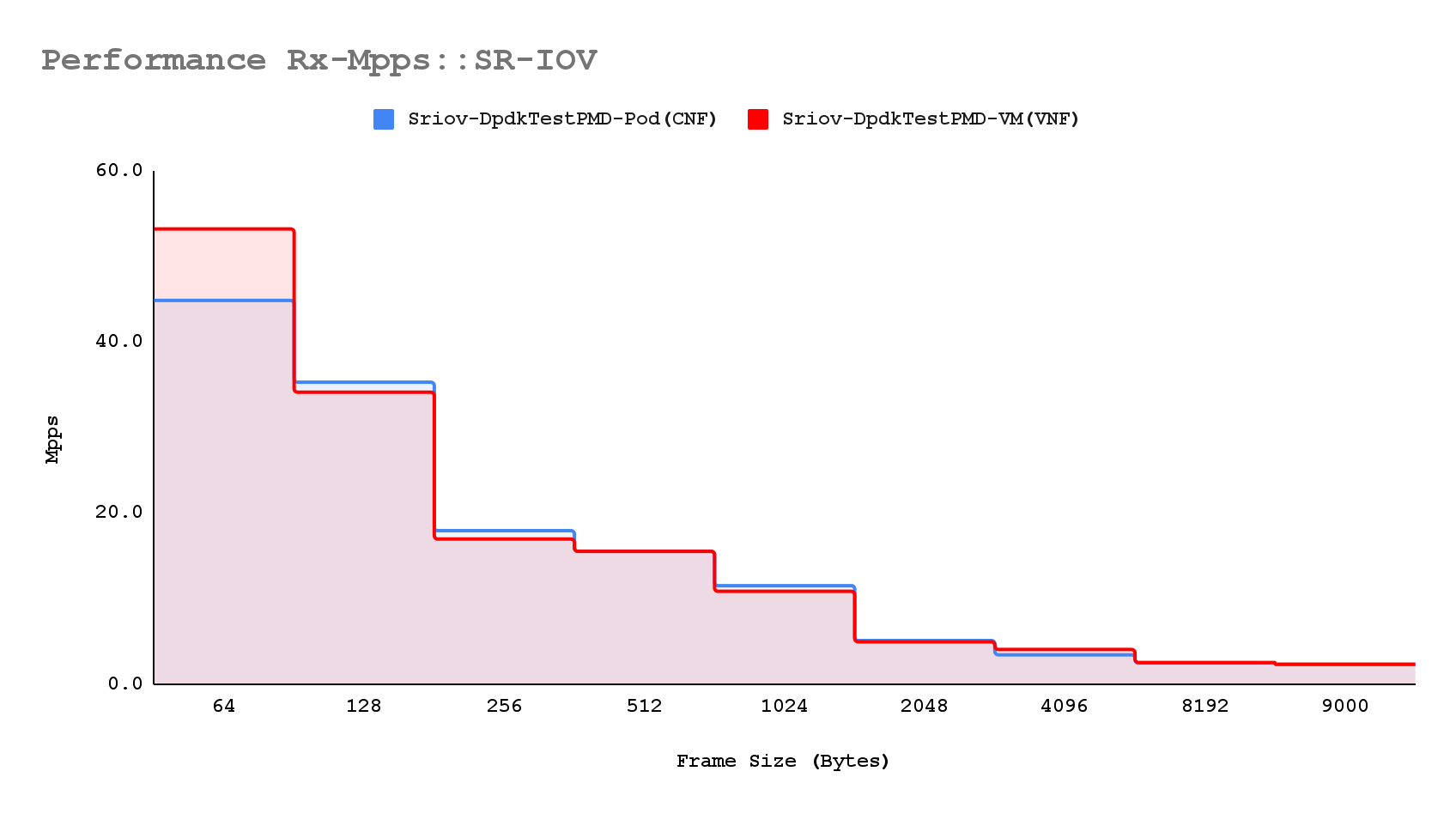
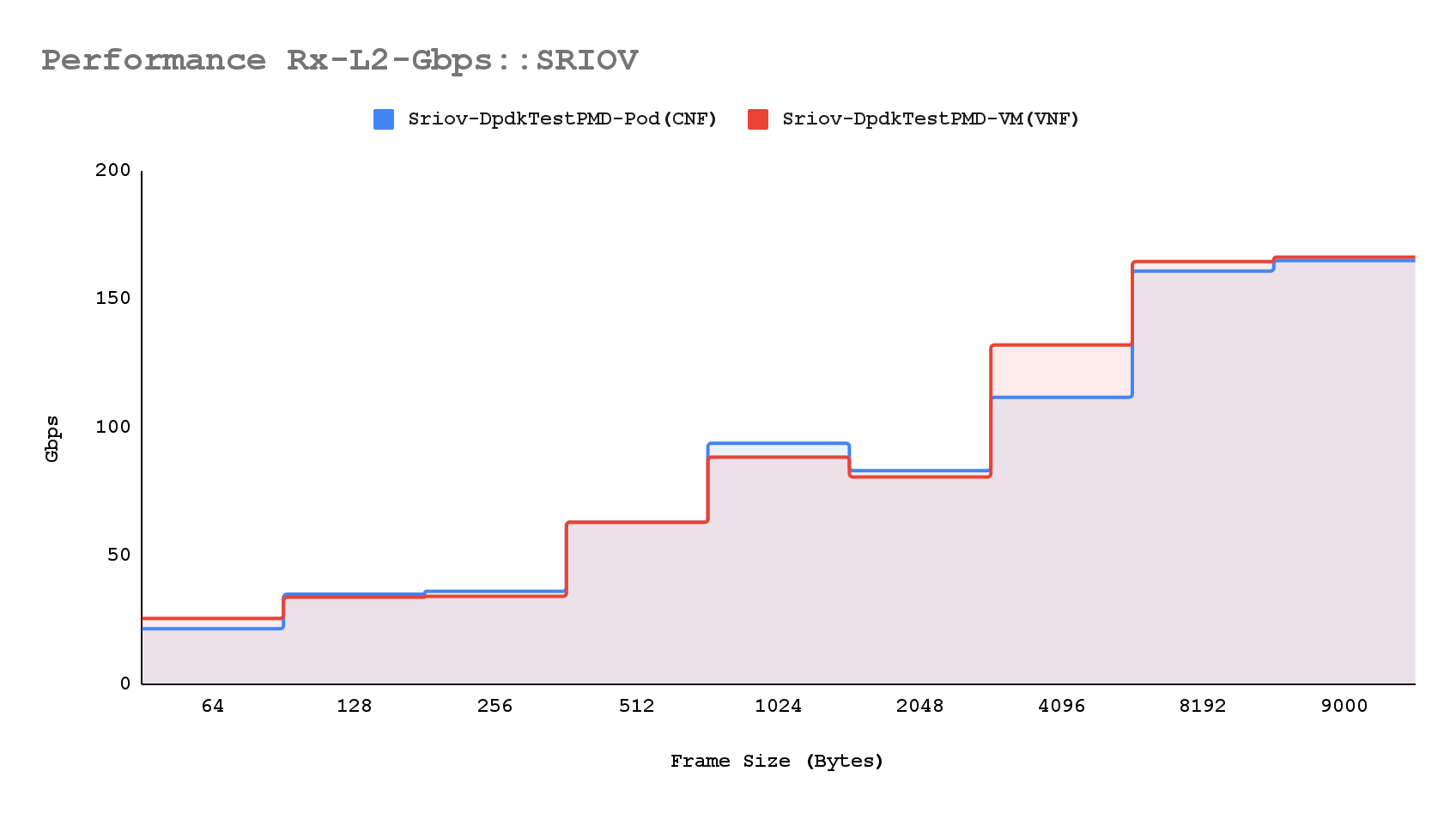
Chart: Trafficgen rx-mpps & rx-l2gbps throughput distribution (bi-dir. traffic)
Microsecond-level latency
Conducting a specific latency measurement test, where non-latency packets were minimized to a rate of 0.0001%, both CNF and VNF latency performance showed dramatic improvement. Notably, the maximum round-trip latency performance for VNF surpassed expectations, and the mean round-trip latency for both CNF and VNF remained consistent across various frame sizes.
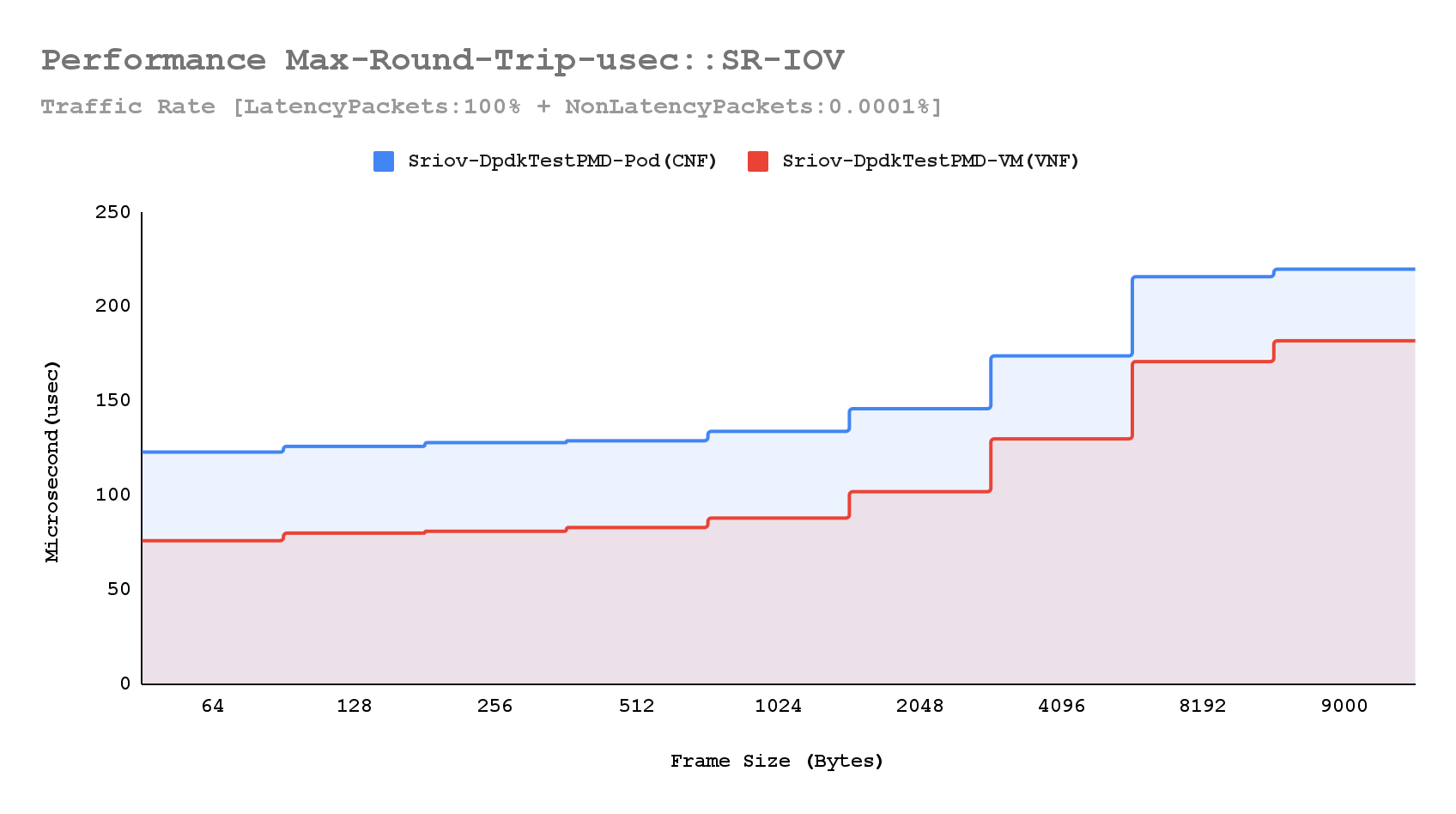
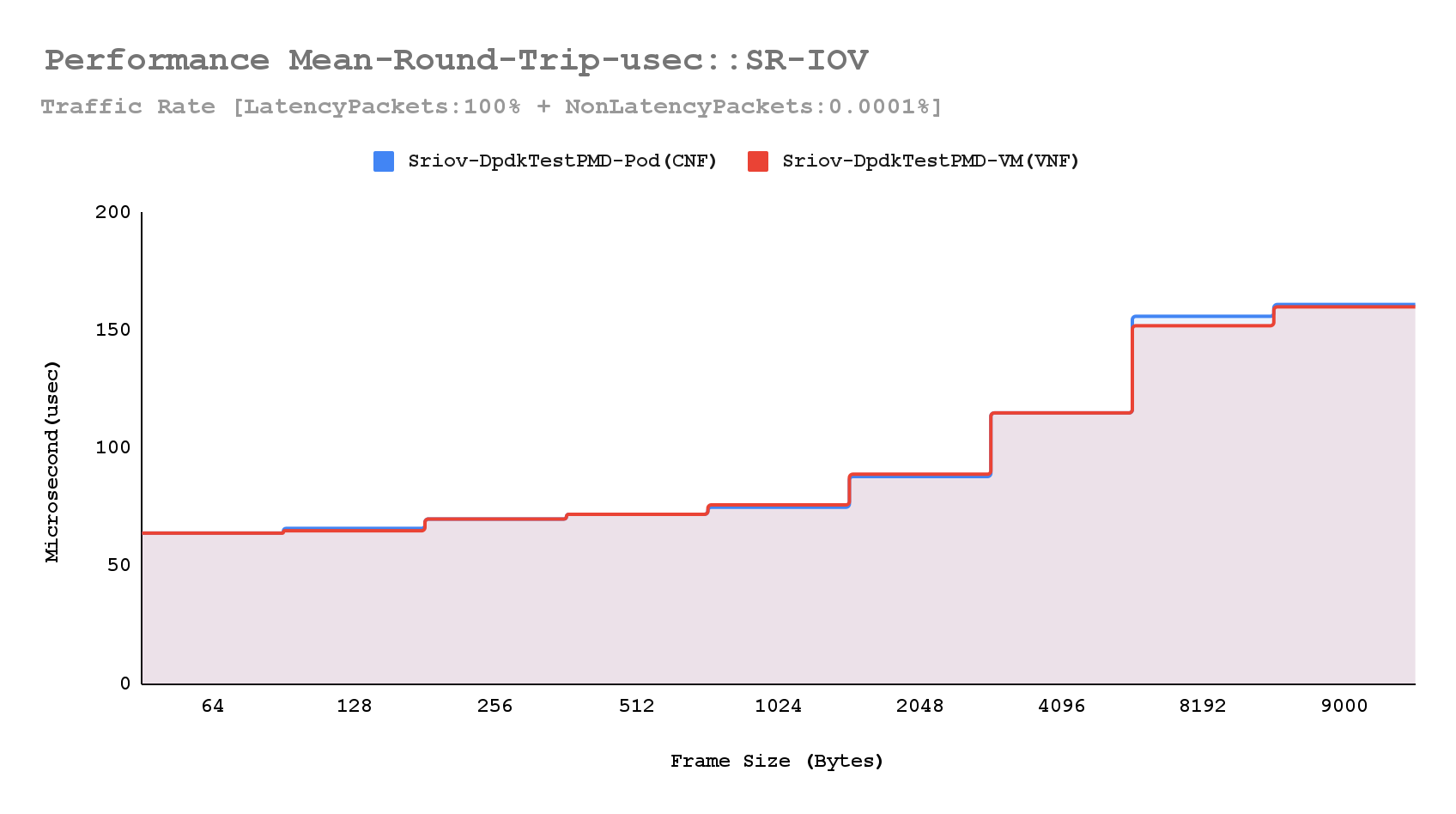
Chart: Mean and max roundtrip latency distribution (bi-dir. traffic)
Unwavering stability of interrupts handling in compute node
During the analysis of interrupt handling for pinned isolated VM cores in the compute node, we observed that the counters for all frame sizes remained consistent in both CNF and VNF scenarios. However, interrupt handling in CNF scenarios was slightly higher than in VNF scenarios. This increase is attributed to additional interrupts reported in the OpenShift management network interface for the Worker VM. These additional interrupts can be disregarded as they do not affect data-plane performance.

Chart: Sriov compute node interrupts handling
CPU efficiency of SR-IOV VMs on compute nodes
Analysis using `mpstat` reveals a consistent performance across CPU cores on our compute nodes. These cores are specifically isolated from the kernel and dedicated solely to SR-IOV VMs. This configuration effectively supports a diverse workload, encompassing both CNFs and VNFs. This optimized setup enhances performance and resource utilization.

Chart: Isolated CPU core performance on SR-IOV compute node for VMs
Analyzing page-faults in compute node
Understanding and monitoring page-faults per second is essential for optimizing system performance and resource allocation efficiency within the SR-IOV compute node. This metric, observed through tools like `sar-mem`, provides critical insights into memory utilization effectiveness. By analyzing page-faults per second on SR-IOV compute nodes, consistent performance patterns can be identified, enabling targeted enhancements for compute node efficiency.

Chart: Memory Page Faults in Sriov Compute node
Empowering CNFs and VNFs
Both CNF and VNF deployments exhibited significant performance improvements with SR-IOV PCI passthrough, highlighting its role in enhancing network efficiency. The study demonstrated that SR-IOV significantly boosts the performance of both deployment types, making it an indispensable asset for modern network infrastructures.
Wrap up
We believe this research underscores the transformative impact of integrating SR-IOV in high-speed network environments. The demonstrably improved throughput, latency and overall performance stability provide a compelling foundation for organizations aiming to improve their network capabilities. This study not only validates the efficacy of SR-IOV but also offers practical insights for optimizing network performance within Red Hat OpenStack 17.1.2 cloud deployments.
About the author
Pradipta Sahoo is a senior software engineer at Red Hat working on cloud performance and scale.
More like this
Why Operational Resilience and Digital Sovereignty Top the CIO Agenda
How Red Hat solves the toughest challenges in agentless infrastructure scanning
Untangling Networks | Compiler
Infrastructure At The Edge | Compiler
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds