
This post updates the previous version based on OpenShift 3.6 with relevant changes for OpenShift 3.9, namely the introduction of Device Plugins. Device Plugin support is now marked as Tech Preview in OpenShift 3.9.
Introduction
The inclusion of Machine Learning and Artificial intelligence components has quickly become the hallmark of many next generation applications. Being able to quickly learn from vast amounts of data is critical to industries such as ecommerce, life sciences, financial services and marketing. Within the last several years, Graphics Processing Units (GPUs) have become key to optimizing the process of learning from data. Because of the wide applicability of ML/AI, (and the impressive performance of GPUs), combining the developer-centric “source to image” workflow espoused by OpenShift with GPU hardware can increase developer productivity by allowing for fast and safe access to GPU hardware.
Providing access to GPU hardware is just the first step - once enabled, a cluster provides development teams with the ability to run machine learning frameworks, such as Caffe, TensorFlow, Torch, MXNet, Theano, and even raw access to CUDA. With these frameworks, developers can bring next generation data-centric feature sets to their applications, and revolutionize customer experience.
This blog post will show how to use GPUs with Device Plugin in OpenShift 3.9. I start with a description of the environment, how to setup the host including installing the essential NVIDIA drivers and NVIDIA docker container runtime. Next, in part 2, I show how to install and enable the GPU Device plugin on OpenShift (running OCP 3.9) cluster. Finally, in part 3, I show how to take advantage of GPUs with training using Caffe2.
Environment Overview
- Red Hat Enterprise Linux 7.4, Caffe2 container image
- OpenShift Container Platform 3.9 Cluster running on AWS
- Master node: m4.xlarge
- Infra node: m4.xlarge
- Compute node 1: m4.xlarge
- Compute node 2: g3.8xlarge (Two NVIDIA Tesla M60 GPUs)
Host Preparation
NVIDIA drivers must be installed on the host as a prerequisite for using GPUs with OpenShift. Let’s prepare the host by installing NVIDIA drivers and NVIDIA container enablement. The following procedures will make containerized GPU workloads possible in OpenShift, leveraging the new Device Plugin feature in OpenShift 3.9.
Part 1: NVIDIA Driver Installation
NVIDIA drivers are compiled from source. The build process requires the kernel-devel package be installed. Ensure that the version of kernel-devel installed matches the running kernel version.
# yum install kernel-devel-`uname -r`
The xorg-x11-drv-nvidia package needs requires the DKMS package. DKMS is not supported or packaged for RHEL. Work is underway to remove the NVIDIA driver requirement on DKMS for Red Hat distributions. DKMS can be installed from the EPEL repository.
First, install the epel repository:
# rpm -ivh https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm
The newest NVIDIA drivers are located in the following repository:
# rpm -ivh https://developer.download.nvidia.com/compute/cuda/repos/rhel7/x86_64/cuda-repo-rhel7-9.1.85-1.x86_64.rpm
Auxiliary tools and mandatory libraries are contained in the following two packages. Let’s install them to have all necessary utilities. This will also pull nvidia-kmod package, which includes the NVIDIA kernel modules.
# yum -y install xorg-x11-drv-nvidia xorg-x11-drv-nvidia-devel
Remove the nouveau kernel module, otherwise the nvidia kernel module will not load. The installation of the NVIDIA driver package will blacklist the driver in the kernel command line (nouveau.modeset=0 rd.driver.blacklist=nouveau video=vesa:off ), subsequent reboots will prevent the loading of the nouveau driver.
# modprobe -r nouveau
Load the NVIDIA and the unified memory kernel modules.
# nvidia-modprobe && nvidia-modprobe -u
Let’s check if the installation and the drivers are working. Extracting the name of the GPU can later be used to label the node in the OpenShift context.
# nvidia-smi --query-gpu=gpu_name --format=csv,noheader --id=0 | sed -e 's/ /-/g'
Tesla-M60
Adding the nvidia-container-runtime-hook
The version of docker shipped by Red Hat includes support for OCI runtime hooks. Because of this, we only need to install the nvidia-container-runtime-hook package and create a hook file. On other distributions of docker, additional steps may be necessary. See NVIDIA’s documentation for more information.
After verifying that the bare-metal NVIDIA drivers are working, the next step is to enable containerized GPU workloads. Install the libnvidia-container and nvidia-container-runtime repository.
# curl -s -L https://nvidia.github.io/nvidia-container-runtime/centos7/x86_64/nvidia-container-runtime.repo | tee /etc/yum.repos.d/nvidia-container-runtime.repo
The next step will install an OCI prestart hook, which is responsible for making all the needed NVIDIA libraries, and binaries available in the GPU container. Environment variables in the container Dockerfile must be present for the hook to take effect.
NVIDIA_DRIVER_CAPABILITES=compute,utility
# yum -y install nvidia-container-runtime-hook
The next step is to make docker aware of the hook, the following bash script will accomplish this.
# cat <<’EOF’ >> /usr/libexec/oci/hooks.d/oci-nvidia-hook
#!/bin/bash
/usr/bin/nvidia-container-runtime-hook $1
EOF
Do not forget to make the hook executable
chmod +x /usr/libexec/oci/hooks.d/oci-nvidia-hook
To use the hook with CRI-O, create the following JSON file:
# cat <<’EOF’ >> /usr/share/containers/oci/hooks.d/oci-nvidia-hook.json
{
"hook": "/usr/bin/nvidia-container-runtime-hook",
"stage": [ "prestart" ]
}
EOF
The last step is to label the installed NVIDIA files with the correct SELinux label. Without this step, you will get a “Permission Denied” error if used inside a container.
# chcon -t container_file_t /dev/nvidia*
Everything is now set up for running a GPU enabled container. If a custom GPU container is built, make sure to include the following environmental variables in the Dockerfile or in the pod yaml description (See later examples how to use a pod with these environment variables):
# nvidia-container-runtime-hook triggers
ENV NVIDIA_VISIBLE_DEVICES all
ENV NVIDIA_DRIVER_CAPABILITIES compute,utility
ENV NVIDIA_REQUIRE_CUDA "cuda>=8.0" # depending on the driver
To test GPU availability and correct operation of driver and container enablement, try running a cuda-vector-add container:
# docker run -it --rm docker.io/mirrorgooglecontainers/cuda-vector-add:v0.1
[Vector addition of 50000 elements]
Copy input data from the host memory to the CUDA device
CUDA kernel launch with 196 blocks of 256 threads
Copy output data from the CUDA device to the host memory
Test PASSED
Done
If the test passes, then the drivers, hooks and the container runtime are functioning correctly.
Part 2: Openshift 3.9 with GPU Device Plugin
While Kubernetes features are still in Alpha, they are disabled by default and placed behind a Feature Gate. This means they must be explicitly enabled on each node. When the Device Plugin feature graduates to Beta, it is enabled by default and the feature gate step is no longer necessary.
After successful installation of OpenShift 3.9, the first step is to add the Device Plugin Feature Gate to the /etc/origin/node/node-config.yaml on every node that has a GPU.
kind: NodeConfig
kubeletArguments:
feature-gates:
- DevicePlugins=true
Restart the atomic-openshift-node service so that the changes become active:
# systemctl restart atomic-openshift-node
Next, create a new project:
# oc new-project nvidia
The project is necessary for the creation of additional service accounts that will have different security context constraints depending on the pods scheduled. The nvidia-deviceplugin service account will have different responsibilities and capabilities compared to the standard one. This means we must also create an additional security context constraint.
# oc create serviceaccount nvidia-deviceplugin
The following snippet shows the new security context constraint (SCC), which will be associated with the nvidia-deviceplugin service account. The Device Plugin creates sockets and mounts host volumes. For security reasons, these two capabilities are disabled by default in OpenShift, so we chose to create a custom SCC, and use that when starting the pod.
# nvida-deviceplugin-scc.yaml
allowHostDirVolumePlugin: true
allowHostIPC: true
allowHostNetwork: true
allowHostPID: true
allowHostPorts: true
allowPrivilegedContainer: true
allowedCapabilities:
- '*'
allowedFlexVolumes: null
apiVersion: v1
defaultAddCapabilities:
- '*'
fsGroup:
type: RunAsAny
groups:
- system:cluster-admins
- system:nodes
- system:masters
kind: SecurityContextConstraints
metadata:
annotations:
kubernetes.io/description: anyuid provides all features of the restricted SCC
but allows users to run with any UID and any GID.
creationTimestamp: null
name: nvidia-deviceplugin
priority: 10
readOnlyRootFilesystem: false
requiredDropCapabilities:
runAsUser:
type: RunAsAny
seLinuxContext:
type: RunAsAny
seccompProfiles:
- '*'
supplementalGroups:
type: RunAsAny
users:
- system:serviceaccount:nvidia:nvidia-deviceplugin
volumes:
- '*'
Now create the new SCC and make it available to OpenShift:
# oc create -f nvidia-deviceplugin-scc.yaml
Verify the new installed SCC:
# oc get scc | grep nvidia
nvidia-deviceplugin true [*] RunAsAny RunAsAny RunAsAny RunAsAny 10 false [*]
To schedule the Device Plugin on the correct GPU node, label the node as follows:
# oc label node <node-with-gpu> openshift.com/gpu-accelerator=true
node "<node-with-gpu>" labeled
This label will be used in the next step.
Deploy the NVIDIA Device Plugin Daemonset
The next step is to deploy the NVIDIA Device Plugin. Note that the NVIDIA Device Plugin (and more generally, any hardware manufacturer’s plugin) is not shipped or supported by Red Hat.
Below is an example daemonset which will use the label we created in the last step so that the plugin pods will only run where GPU hardware is available. Here is a sample pod description that uses the NVIDIA Device Plugin and leverages the service account we just created along with a node selector.
# nvidia-device-plugin.yml
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
name: nvidia-device-plugin-daemonset
namespace: nvidia
spec:
template:
metadata:
labels:
name: nvidia-device-plugin-ds
spec:
priorityClassName: system-node-critical
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: openshift.com/gpu-accelerator
operator: Exists
serviceAccount: nvidia-deviceplugin
serivceAccountName: nvidia-deviceplugin
hostNetwork: true
hostPID: true
containers:
- image: nvidia/k8s-device-plugin:1.9
name: nvidia-device-plugin-ctr
securityContext:
privileged: true
volumeMounts:
- name: device-plugin
mountPath: /var/lib/kubelet/device-plugins
volumes:
- name: device-plugin
hostPath:
path: /var/lib/kubelet/device-plugins
Now create the NVIDIA Device Plugin:
# oc create -f nvidia-device-plugin.yml
Lets verify the correct execution of the Device Plugin.
# oc get pods
NAME READY STATUS RESTARTS AGE
nvidia-device-plugin-daemonset-s9ngg 1/1 Running 0 1m
Once the pod is running, let’s have a look at the logs:
# oc logs nvidia-device-plugin-daemonset-s9ngg
2018/01/23 10:39:30 Loading NVML
2018/01/23 10:39:30 Fetching devices.
2018/01/23 10:39:30 Starting FS watcher.
2018/01/23 10:39:30 Starting OS watcher.
2018/01/23 10:39:30 Starting to serve on /var/lib/kubelet/device-plugins/nvidia.sock
2018/01/23 10:39:30 Registered device plugin with Kubelet
At this point the node itself will advertise the nvidia.com/gpu extended resource in it’s capacity:
<span># oc describe node ip-172-31-15-xxx.us-west-2.compute.internal|egrep ‘Capacity|Allocatable|gpu’</span>
Capacity:
nvidia.com/gpu: 2
Allocatable:
nvidia.com/gpu: 2
Nodes that do not have GPUs installed will not advertise GPU capacity.
Deploy a pod that requests a GPU
Let’s run a GPU-enabled container on the cluster -- we can use the cuda-vector-add image that was used in the Host Preparation step. Here is a pod description for running the cuda-vector-add image in OpenShift. Note the last line requests one NVIDIA GPU from OpenShift. The OpenShift scheduler will see this GPU request and schedule the pod to a node that has a free GPU. Once the pod create request arrives at a node, the Kubelet will coordinate with the Device Plugin to start the pod with a GPU resource.
# cuda-vector-add.yaml
apiVersion: v1
kind: Pod
metadata:
name: cuda-vector-add
namespace: nvidia
spec:
restartPolicy: OnFailure
containers:
- name: cuda-vector-add
image: "docker.io/mirrorgooglecontainers/cuda-vector-add:v0.1"
env:
- name: NVIDIA_VISIBLE_DEVICES
value: all
- name: NVIDIA_DRIVER_CAPABILITIES
value: "compute,utility"
- name: NVIDIA_REQUIRE_CUDA
value: "cuda>=8.0"
resources:
limits:
nvidia.com/gpu: 1 # requesting 1 GPU
Create the file and start the pod:
# oc create -f cuda-vector-add.yaml
After a couple of seconds the container finishes and the logs can be examined:
# oc get pods
NAME READY STATUS RESTARTS AGE
cuda-vector-add 0/1 Completed 0 3s
nvidia-device-plugin-daemonset-s9ngg 1/1 Running 0 9m
The pod completed execution. Let’s have a look at the logs for any errors:
# oc logs cuda-vector-add
[Vector addition of 50000 elements]
Copy input data from the host memory to the CUDA device
CUDA kernel launch with 196 blocks of 256 threads
Copy output data from the CUDA device to the host memory
Test PASSED
Done
Part 3: Multi-GPU Training with Caffe2
Now that we have a fully configured OpenShift cluster with GPU support, let’s create a more sophisticated workload on the cluster. For the next step one will use the docker.io/caffe2ai/caffe2 image for Multi-GPU training.
Here is a simple pod description for starting a Jupyter notebook. Note that the pod is requesting two GPUs. Also, for testing and simplicity this pod will also use the host network. Beware that default access to the notebook is only from localhost. For accessing the notebook from external IPs, you must create a new Jupyter config that allows access.
# caffe2.yaml
apiVersion: v1
kind: Pod
metadata:
name: caffe2
namespace: nvidia
spec:
hostNetwork: true
restartPolicy: OnFailure
containers:
- name: caffe2
image: "caffe2ai/caffe2"
command: ["jupyter"]
args: ["notebook", "--allow-root"]
ports:
- containerPort: 8888
securityContext:
privileged: true
resources:
limits:
nvidia.com/gpu: 2 # requesting 2 GPU
Now point a browser to the node and open the following URL:
http://<node-with-gpus>:8888/notebooks/caffe2/caffe2/python/tutorials/Multi-GPU_Training.ipynb
The following view shows the successfully loaded notebook:
After the notebook is up and running, you can follow the tutorial. The result will be a Convolutional Neural Network (ResNet-50) using the ImageNet dataset for recognizing Images. Now let’s start the training, and see how the setup utilizes the GPUs.
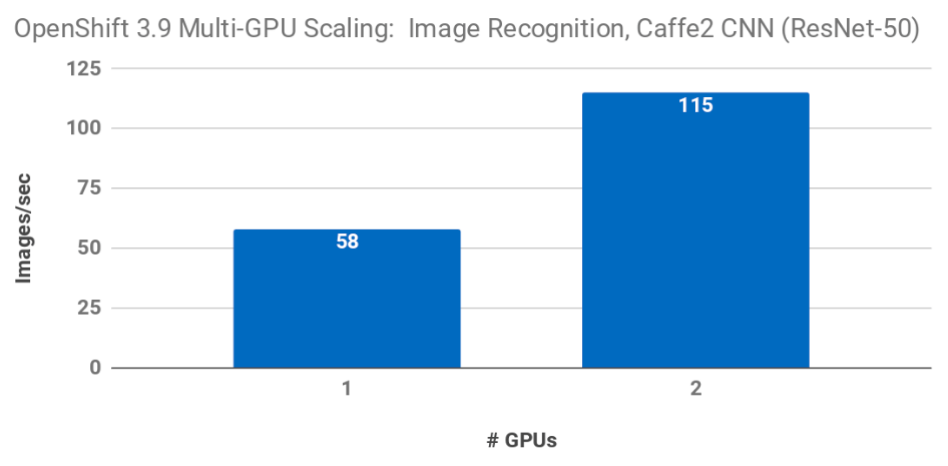
Performance of image recognition scales linearly with the number of GPUs in use:
Here is a excerpt from the tested images with accuracy and if correctly recognized or not:

Conclusion
This blog is meant to get you started with using GPUs on OpenShift 3.9, leveraging the new device plugin feature. Red Hat is working hard with the Kubernetes community through the Resource Management Working Group to bring Device Plugins to Beta (in Kubernetes 1.10) and GA as soon as possible.
We’re also working with other hardware accelerator vendors (such as NVIDIA and others) to streamline the installation process, administrator- and user-experience for popular machine learning and artificial intelligence application design frameworks.
We encourage you to give this procedure a try, and give us feedback by filing issues in OpenShift Origin’s Github repo.
About the author
More like this
Why Red Hat partners are the ultimate telco business asset
Reclaiming infrastructure autonomy: The 180-day mandate for virtualization service providers
Crack the Cloud_Open | Command Line Heroes
Edge computing covered and diced | Technically Speaking
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds