When we graduated OpenShift Virtualization from Tech Preview to a Generally Available feature with OpenShift 4.5, we had a good idea how development teams would use virtual machines in Kubernetes to accelerate their transformation; leveraging traditional workloads like enterprise databases and middleware alongside container based applications.
Working with our customers in aerospace, automotive, and financial services, we discovered an enthusiasm to use virtual machines in a more natural cloud-native way. By using a single, scalable platform, development teams can continually deliver innovative solutions, keeping their organizations agile as they compete for customers.
As we focus on developing and deploying hybrid applications in OpenShift, here are a few of the highlights of OpenShift Virtualization 2.6 with OpenShift 4.7, which arrives in early March.
Easy to learn with Quickstarts
A developer or administrator coming from a traditional development environment may be astonished by the different concepts and capabilities of OpenShift. We made it easier to grok new concepts and features using Quickstart templates. These step you through the process, like creating a virtual machine, right within the context of the web console.
It’s also easy to write Quickstarts for your own application, making it easier for your administrators and users to find and learn about new capabilities you’ve delivered.
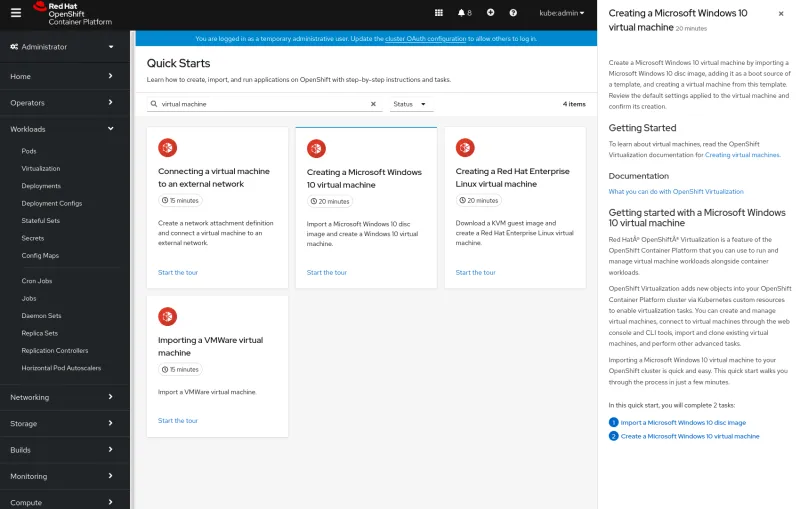
Frictionless creation of virtual machines
One of the design goals for OpenShift Virtualization is to have not only administrators, but also non-privileged developers be able to create and use VMs as easily as pods and containers. Using VM templates for standard Microsoft Windows and Linux platforms, developers can easily integrate VMs into their applications without needing to know details of how it’s built. Developers can focus on development, instead of VM configuration and management.
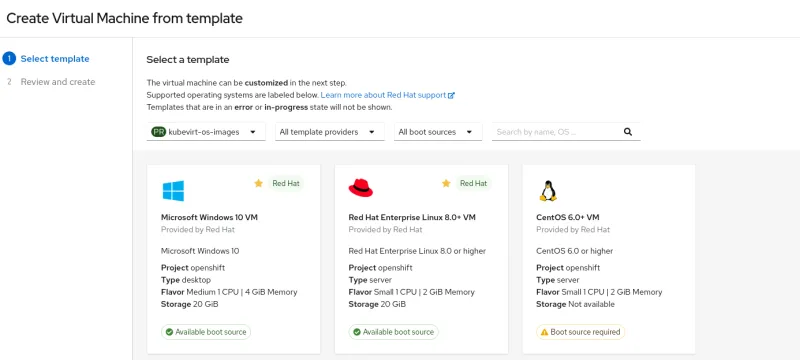
Using templates, creating a VM is as simple as picking the operating system, while using intelligent defaults for the workload profile and flavor.
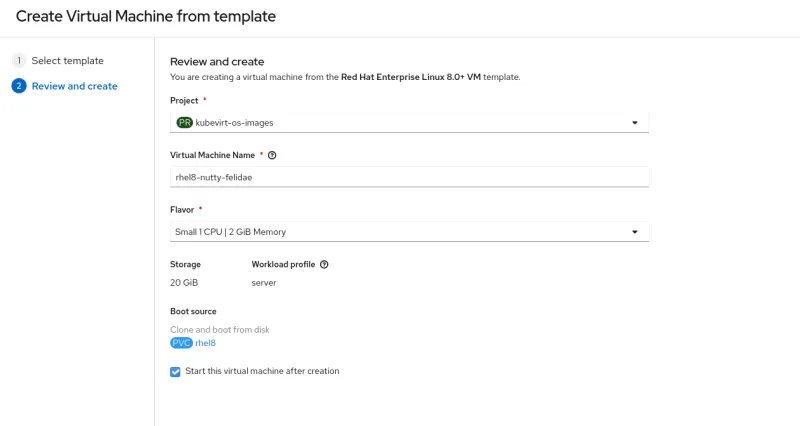
Easy to deploy
The best way to describe VMs in OpenShift is “KVM in pods”. Since we are using the same hypervisor technology across the Red Hat portfolio, we can leverage features from our other platforms like Red Hat Virtualization and Red Hat OpenStack Platform.
When deploying VMs at scale, with different deployment methods, it’s important to secure your environment and prevent rogue images from running on your systems. Current operating systems support the modern replacement for legacy BIOS, the Unified Extensible Firmware Interface (UEFI). Using the UEFI Secure Boot capability ensures that only signed valid operating system images can be booted within your IT environment.
While using VMs in a Kubernetes-native way, some things can be a little tricky. When provisioning storage using Persistent Volumes (PV), it’s important that they are created properly, regardless of where they are running in the cluster. One improvement we’ve made is to automatically account for filesystem overhead inside the PV, and orchestrate the creation of PVs on local storage, so that VMs run in the most efficient way without being exposed to human errors.
If you have an existing inventory of workloads you’d like to run on OpenShift, Migration Toolkit for Virtualization (MTV) simplifies the migration of virtual machines at scale. By doing so, developers have the ability to more easily access services running in virtual machines, while developing new cloud-native applications. MTV is based on the upstream Konveyor Forklift project, and is now available in Tech Preview.
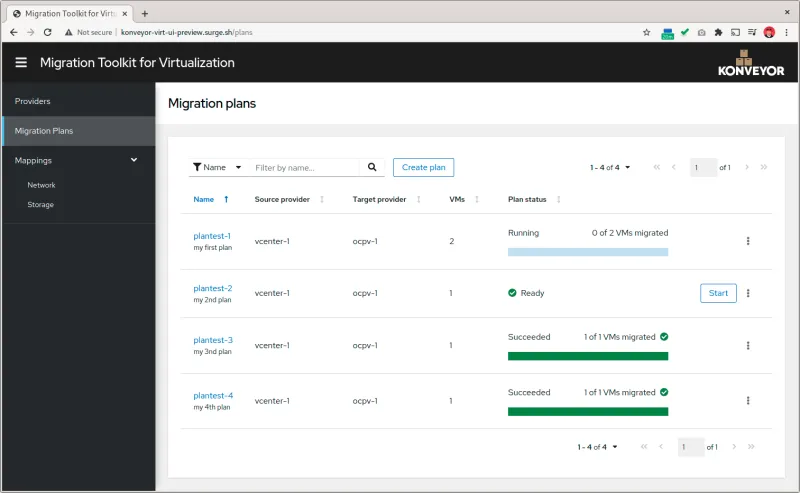
One of the capabilities introduced back in OpenShift 4.6 is making workloads highly available by automatically restarting them on a different node in the cluster in the event of a node failure. The native Kubernetes mechanisms could take up to 5 minutes to detect and recover this situation. By deploying installer-provisioned clusters on bare metal and using machine health checks, virtual workloads can automatically restart within 60 seconds of a node failure.
All versions of OpenShift are validated in the Microsoft Windows Server Virtualization Validation Program (SVVP), which ensure you’re fully supported for workloads running Windows Server 2012 R2, Windows Server 2016, Windows Server 2019, and Windows 10.
Easy to optimize
As we demonstrate the equivalent performance of VMs on OpenShift for business critical workloads like enterprise databases, we’ve heard even more interesting cases of customers deploying robust applications in VMs on OpenShift. One technique to get optimal I/O performance is to use pre-allocated virtual disks. This is critical for high throughput and performance sensitive databases like MS SQL Server, MySQL, and PostgreSQL.
As you deploy a broader range of applications at scale, it’s important to know the extra resource required to run VMs across your OpenShift cluster. We’ve created sizing guidance that details the CPU, memory, and storage requirements.
Summary
OpenShift 4.7 with OpenShift Virtualization greatly simplifies the common workflows used by operations and development teams today. Using OpenShift Virtualization, it’s easy to leverage the critical business logic and valuable data locked in VMs, as well as use virtual machines in Kubernetes in a very cloud-native way. OpenShift Virtualization is included at no additional cost with OpenShift Container Platform and OpenShift Kubernetes Engine.
Red Hat is a leading contributor to KubeVirt, the upstream CNCF project that users and vendors are adopting to integrate virtual machines in Kubernetes. To learn more about what’s been added in this OpenShift Virtualization release, please see the OpenShift Virtualization Release Notes for details.
Find out more
OpenShift Virtualization demos on demo.openshift.com
OpenShift TV library of recorded OpenShift videos and streams
Upstream Project and community
KubeVirt Summit from February 2021
About the author

Peter is a product manager in Cloud Platforms, focused on virtualization. He has been in high tech for storage, virtualization, databases, and hyperconverged solutions for longer than he cares to admit.
More like this
Looking ahead to 2026: Red Hat’s view across the hybrid cloud
Red Hat to acquire Chatterbox Labs: Frequently Asked Questions
Crack the Cloud_Open | Command Line Heroes
Edge computing covered and diced | Technically Speaking
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds