Overview
Not every application or environment is designed for the demands of lightweight, highly distributed workloads. Edge computing is computing that takes place at or near users or data sources - outside of the traditional, centralized data center/cloud. This exists across a spectrum of infrastructure architectures. On one end, you have inexpensive, portable devices on the very edge of the network with limited computational resources (for example, mobile edge computing devices such as smartphones and handheld tablets); IDC calls this "light edge". At the other end, the "heavy edge," is something such as a datacenter/remote office configuration, where there are large servers and high numbers of users (and data transactions).
Regardless of where on the spectrum your infrastructure falls, there are some common needs and expectations. At its core, users and devices need to be able to carry out transactions in real time to be able to meet customer expectations and performance service level agreements (SLAs). What that means is effective applications in those environments have to be able to hit very specific performance benchmarks. Such applications are called latency-sensitive applications.
Defining some terms
Before getting into what latency-sensitive applications are, let’s define the basic terms:
- Latency is the time from when an event occurs to when that event is handled by a system; the easiest way of looking at it is the time it takes to go from point A to point B.
- Bandwidth (or network bandwidth) is the amount of data that can be transported in a given period of time; this is usually megabits or gigabits per second. The actual amount of data transported in a given time is called throughput. High bandwidth (or high throughput) and low latency can sometimes be considered a tradeoff. It is difficult to achieve both simultaneously.
- Packets are the data elements being transported.
- Jitter is variability in latency, usually when the consistency of the network communication is dropped or intermittently slow.
- Real time means that an operation is performed within a specific, defined amount of time (usually measured in milli or microseconds). Real time is often misunderstood to mean "real fast"; real time is more about determinism, which means the operation is guaranteed within a given set of time constraints regardless of other operations or load. With real time processing, each transaction is discrete, unlike batch processing, which collects multiple transactions together.
- Edge nodes generally refer to any device or server where edge computing can take place.
Red Hat resources
So, what is a latency-sensitive application?
Latency is a time-based metric that measures the actual response time of a system compared to the intended response time. This commonly evaluates the network, hardware, firmware, and operating system's performance, both individually and altogether for the entire system. For latency-sensitive applications, low latency is good because it means that the delay between when an operation is initiated and the resulting response is short. Higher latency is bad, both because it is slower and, depending on the type of data, could mean that packets are being dropped or lost. Latency should also be stable—too much jitter makes the network unreliable, even if the average latency looks good.
An example of an edge-based, latency-sensitive application is an AI-driven autonomous vehicle. The computer on board only has milliseconds to recognize whether a pedestrian or other object is in the road and process a course correction. All of the data processing and the artificial intelligence has to be contained within the vehicle, along with live telemetry going back to a gateway or data center. This is a critical application; a slow response while processing a credit card transaction or video conference can be frustrating for end users, but a failure with autonomous driving can be life-changing. The Institute of Electrical and Electronic Engineers (IEEE) outlines the dependency of many modern technologies on latency-sensitive applications.
People generally look at latency as a factor of speed, but it’s more accurate to think of latency as an aspect of total system performance. Latency is observed in the time between when an event initiates and when it is completed. And those time limits can be flexible, depending on the application. The autonomous vehicle is an example of a hard limit; the processing has to be instantaneous or there could be critical system failures.
Some workloads don’t require low latency. In other words, the time between initiation and response for an operation can be acceptably high. These workloads are asynchronous, meaning that the time between initiation and completion aren’t observable or relevant to users. High latency is acceptable with services like email, for example, because the time required to receive an email after it is sent is not easily observed by the end user.
In complex environments—whether it is a single system or multiple interacting systems—the effects of latency are cumulative. Whether operations need to be completed sequentially or in parallel, the effectiveness of the overall system may be affected by the total latency of the key operations. In this case, speed may not be the primary factor: consistency may be the key metric. This is called deterministic latency, meaning the expected latency for a given operation (or the total latency for all operations) is predictable and consistent. This can be critical where multiple devices need to be synchronized, such as phased array radar, telecommunications equipment, or manufacturing equipment.
TLDR; A latency-sensitive application is, functionally, a real-time application. This can be any application where high or variable latency is going to negatively affect the application performance, so operations need to occur within a deterministic window, often measured in microseconds. These are also called low latency applications.
There may be benefits to characterizing applications as latency-sensitive applications, where latency affects the performance but the application is still working, and latency-critical applications, where latency past a certain point will cause a failure.
Latency, virtualization, and cloud services
Latency is often described in terms of network performance, but latency-sensitive applications highlight that the network quality frequently isn’t the only cause of latency. Factors that affect processing time also affect latency.
With virtualization and virtual machines, different virtual processes compete with each other for CPU resources and shared resources like memory and storage. Even system settings like power management and transaction handling can affect how different processes access resources.
Similar challenges can occur with cloud computing environments. The more layers of abstraction there are in the hardware environment, the more difficult it can be to allocate processing and shared resources in a way that optimizes processing time and minimizes latency for core applications. Cloud providers such as Amazon Web Services (AWS) may offer deployments and optimizations for latency-sensitive and latency-critical applications.
When dealing with a latency-sensitive application, the overall operating environment and underlying hardware is as important as the network infrastructure and configuration for creating reliability.
The role of latency-sensitive applications in edge computing
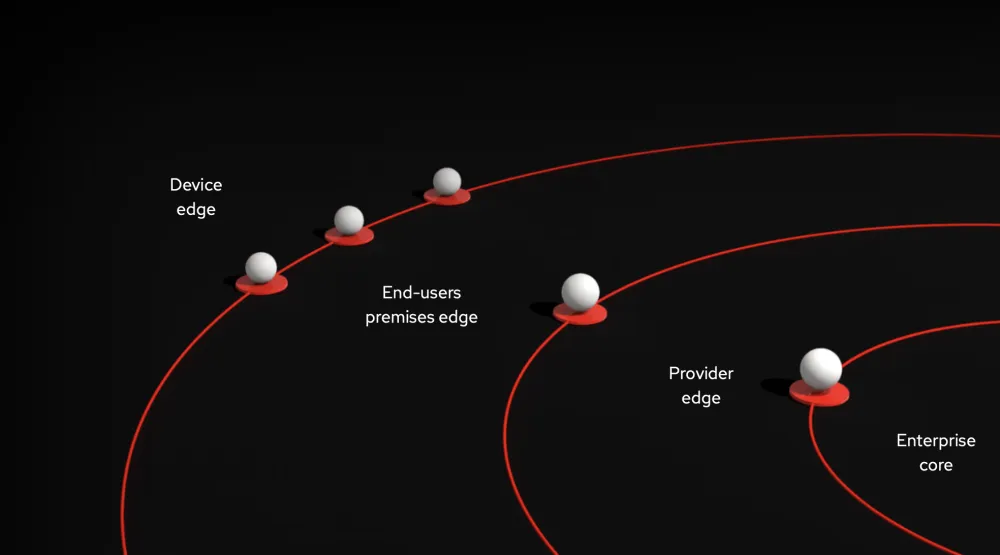
An edge architecture is often described as a kind of onion, with concentric circles of hardware layers that move further away from the central datacenter. Each layer has its own architecture and considerations, and different solutions are required for these different use cases.
The outer rings of an edge architecture are the ones closest to data-generating interactions, such as customers/users or managed devices. These edges need to be highly responsive to changing conditions and new data; therefore the ones most likely to deploy latency-sensitive or real-time applications. These are also the layers furthest from shared data stores and more likely to have lightweight, small-scale hardware like tablets or internet of things (IoT) devices.
In this context, IT leaders can develop effective processes and policies to make sure that their latency-sensitive applications and overall edge computing environments remain performant. They should:
- Have clear, centralized development and deployment pipelines.
- Have consistent update and management policies for both software and hardware.
- Integrate performance testing into all pipelines.
- Automate wherever possible.
- Define standard operating environments for consistency across the edge.
- Use consistent, open standards and methodology for interoperability.
These best practices are very similar for industrial IoT (IIoT), high performance computing, and other distributed architectures. Edge or IoT are not an end state; they are a means to accomplish a specific goal. Likewise, latency-sensitive applications aren’t beneficial just because faster is better. These applications serve a purpose where fast data processing can create powerful customer experiences or safely and efficiently manage large equipment, react to changing operating conditions, and adapt to new inputs.
How Red Hat tackles latency-sensitive applications
The operating system is just as important in edge and cloud environments as it is in the physical data center and server room. The operating system provides core functionality like resource provisioning and management which are crucial to latency-sensitive applications, as well as other IT requirements like security and networking configuration.
With latency-sensitive applications, the question comes down to how much data needs to be reviewed in the data center or cloud versus whether to offload activity to run locally. This is a balance of data quantity and speed.
If the risks of latency reside in the local processing, then there are specific tools that can help improve system performance. Alternatively, it is possible to design an architecture, with a variety of different tools and technologies, that lessen the effects of latency.
Addressing latency in the architecture
Depending on your approach, you may be more concerned about latency requirements within the network, which means that your edge architecture is critical for your services to run effectively. With network latency, your edge architecture needs to be able to process data locally, at the edge itself, rather than sending raw data to a data center, processing it, and sending a response. Being able to push processing for applications to the edge reduces the dependence on high-latency networks.
Red Hat® Enterprise Linux® for Distributed Computing provides edge optimized features to deploy application workloads across a distributed hybrid cloud architecture, including data center, cloud, and edge, with an open and consistent operating environment. Red Hat Enterprise Linux for Distributed Computing can be installed to edge endpoints and gateways to allow applications to analyze and process data locally while delivering relevant updates and data insights to servers in the cloud or data center. This reduces the dependence on networks with high latency, inconsistent bandwidth, and intermittent connections.
Addressing system latency
Timing is critical for latency-sensitive environments. Even with well-designed architectures, it can still be a wise decision to have a highly performant system at the edge for local processing.
Latency-sensitive applications require a highly tunable operating environment. Red Hat Enterprise Linux for Real Time is a special package made to implement changes in algorithms and subsystems designed specifically for latency-sensitive environments, where the need for predictability and speed are beyond the scope of normal performance tuning.
Red Hat Enterprise Linux for Real Time includes low-level utilities that support key configurations for better real-time performance:
- Optimize hardware and memory configurations, as well as applications written with concurrent programming techniques.
- Control the execution of multithreaded, multiprocess applications.
- Check the suitability of a hardware system.
- Define caching behavior.
Rely on a larger ecosystem
This is where the Red Hat ecosystem is especially powerful. There are certified hardware configurations and vendors for Red Hat Enterprise Linux for Real Time and Red Hat Enterprise Linux for Distributed Computing which can give you confidence that your edge applications will run to your specifications.
Additionally, Red Hat Enterprise Linux integrates with Red Hat® OpenShift® for Kubernetes container orchestration and deployment, Red Hat® Ansible® Automation Platform for automation, and Red Hat Middleware for process and decision management, data streams, integration, and other tools.
Edge is a strategy to deliver insights and experiences at the moment they’re needed. Red Hat Enterprise Linux for Real Time, Red Hat Enterprise Linux for Distributed Computing, and the rest of the Red Hat portfolio can be a powerful foundation to help deliver that strategy.
The official Red Hat blog
Get the latest information about our ecosystem of customers, partners, and communities.