This toolkit is not officially supported by Red Hat Ansible support/engineering and is provided as is. It is intended a starting point for a Red Hat Consulting delivery of Ansible Tower.
Solution Reference Architecture

This diagram represents the reference architecture for a full high availability and disaster recovery solution. This solution can be individually tailored to address a single availability solution. For example, if only disaster recovery is needed the configuration supports exclusion of the HA replica.
High Availability
Ansible Tower clustering provides increased availability by distributing jobs across nodes in a cluster. A failure of a single node results in reduced capacity in the cluster. The database remains a single point of failure in a cluster. If the the database becomes unavailable the cluster will also become unavailable. This configuration provides for a replica database (HA Replica) in the primary cluster datacenter, which can be transitioned to primary. Although not completely automated, this provides for faster recovery in database outage scenarios.
NOTE: In the future this feature is planned to be delivered and supported by a third party.
HA Failover

HA Failback

Disaster Recovery
Ansible Tower clusters are not recommended to span datacenter boundaries due to latency and outage concerns. In the event of a total datacenter failure Ansible Tower would become unavailable. The Ansible Tower disaster recovery approach allows for failover to pre-provisioned resources in a secondary datacenter. The database in the secondary datacenter configured as a warm standby/replica of the database in the primary datacenter. During a failover, Ansible Tower is installed onto the pre-provisioned nodes and pointed to the replica database (promoted to primary)
DR Failover
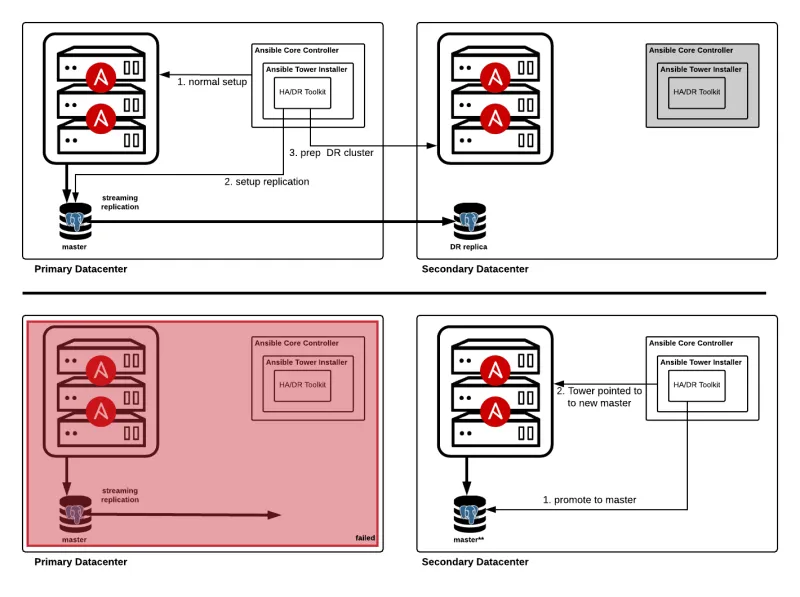
DR Failback

Streaming Replication
PostgreSQL provides built in mechanisms to achieve increased availability. The use of warm standby or replica databases allows for simple and fast failover in recovery scenarios.
Configuration
Assumptions/Prerequisites
- all Ansible Tower machines specified in inventory are pre-provisioned with authentication mechanism known (password, SSH keys)
- Ansible control machine (RHEL 7 or CentOS) available and configured with Ansible 2.7+
- if not running as root and need to use privilege escalation (eg sudo) you need to set it up in the inventory (
ansible_become=true) - If there is no connectivity to the internet the bundle installation media will need to be placed in the
tower_installerdirectory. Please ensure the bundle is available before preceding. - The Ansible Tower installation inventory for each configuration will need to be defined.
- This toolkit and the playbook suite is meant to be run by a one user at a time and one playbook at a time. For example, do not try running multiple instances of the
tower-setup-replication.ymlplaybook from the same playbook_dir. Issues can arise because a dynamic inventory script is used with a tmp file indicating which file to load. This mechanism allows to effectively change the inventory during playbook execution.
Setup
- Clone this repository to the configure Ansible control machine and enter directory
git clone https://github.com/redhat-cop/automate-tower-ha-dr.git
cd automate-tower-ha-dr
- Create a directory for your Tower installation inventories. Create the appropriate
inventory_pm,inventory_haandinventory_drTower installation inventory files in the directory. Examples are provided in theinventory_dr_staticandinventory_ha_drdirectories of this repository.
Some points to note about your Ansible Tower inventory files:
- Each inventory represents a separate configuration for Tower (primary, HA, DR)
- You must define a primary inventory(
inventory_pm) along with one or both of the HA inventory(inventory_ha) and DR inventory(inventory_dr) - There should be no overlap between primary/HA and disaster recovery instance groups, include the default
towerinstance group across inventory files, This goes back to the discussion above that instance groups cannot span datacenters. Isolated instance groups can be repeated if you with to utilize existing isolated nodes. - The
databaseanddatabase_replicagroup membership should be unique across all inventory files. Thedatabasegroup should have only one database and is the database in use the the given configuration. Thedatabase_replicagroups contain the streaming replicas to be configured. - If an external database team is managing the Ansible Tower database and handling the replication and failover, the
database_replicagroup can be excluded and thetower_db_external(explained below) to skip any replication configuration - The example inventory files show various configurations for setting up replication in a failover scenario.
- The HA inventory file, used in HA failover, has streaming replication configured back to the original master and DR database. This is optional but in order to 'failback', replication to the original master must be re-enabled.
- The DR inventory file, used in DR failover, has streaming replication configured back to the original master and leaves replication to the HA database. This is optional but in order to 'failback', replication to the original master must be re-enabled.
Examples
inventory_ha_dr/inventory_pm
[tower]
towervm1 ansible_ssh_host="10.26.10.50"
[database]
towerdb1 ansible_host="10.26.10.20"
[database_replica]
towerdb2 ansible_host="10.26.10.21" pgsqlrep_type=local
towerdb3 ansible_host="10.26.10.22" pgsqlrep_type=remote
[database_all:children]
database
database_replica
[database_all:vars]
pgsqlrep_password=password4
[all:vars]
<<CLIPPED>>
pg_host='10.26.10.20'
<<CLIPPED>>
inventory_ha_dr/inventory_dr
[tower]
towervm2 ansible_host="10.26.10.51"
[database]
towerdb3 ansible_host="10.26.10.22"
[database_replica]
towerdb1 ansible_host="10.26.10.20" pgsqlrep_type=remote
[database_all:children]
database
database_replica
[database_all:vars]
pgsqlrep_password=password4
[all:vars]
<<CLIPPED>>
pg_host='10.26.10.22'
<<CLIPPED>>
inventory_ha_dr/inventory_ha
[tower]
towervm1 ansible_host="10.26.10.50"
[database]
towerdb2 ansible_host="10.26.10.21"
[database_replica]
towerdb1 ansible_host="10.26.10.20" pgsqlrep_type=local
towerdb3 ansible_host="10.26.10.22" pgsqlrep_type=remote
[database_all:children]
database
database_replica
[database_all:vars]
pgsqlrep_password=password4
[all:vars]
<<CLIPPED>>
pg_host='10.26.10.21'
<<CLIPPED>>
- Copy
tower-vars-base.ymltotower-vars.ymlfor customization in your environments
cp tower-vars-base.yml tower-vars.yml
- Modify the
tower-vars.ymlfile for your environment. A description of the most commonly customized values are provided below. This includes definition of the inventory file for each configuration (primary/normal, HA, DR) and referencing their location. This file will be read in by all toolkit playbooks
# version of Ansible Tower to install/working with
tower_version: 3.3.0-1
# determine if the bundle is being used
tower_bundle: true
# indicated whether this will be installed without internet connectivity
tower_disconnected: true
# list of Ansible tower installer inventory files for each configuration
tower_inventory_pm: inventory_ha_dr/inventory_pm
tower_inventory_dr: inventory_ha_dr/inventory_dr
tower_inventory_ha: inventory_ha_dr/inventory_ha
# indicate whether the database is managed by the installer and toolkit or
# provided as a service. If set to true, all replication configuration is skipped
tower_db_external: false
- Run the
tower-setup.ymlplaybook. This playbook will take care of downloading the tower installation media for you installation (if it does not yet exist) and running the tower installer. The version to be downloaded and/or used in the installation is found in thetower-vars.ymlfile.
If you are running in a disconnected environment set the tower_disconnected variable to true and ensure the installer bundle is already downloaded. For example for 3.3.1 ensure tower-installer/ansible-tower-setup-bundle-3.3.1.el7.tar.gz is in place
ansible-playbook tower-setup.yml
If you want skip running Ansible Tower setup and only utilize this playbook to download the correct installer you can override the tower_download_only variable and run the playbook.
ansible-playbook tower-setup.yml -e 'tower_download_only=1'
- Run the
tower-dr-standup.ymlto prepare the failover cluster and configure replication.
ansible-playbook tower-dr-standup.yml
If applicable, you may want to check the status of the replication
ansible-playbook tower-check-replication.yml
At this point the secondary/DR machines are ready for failover and streaming replication enabled
HA Failover
In the event of a database outage in the primary database the following playbook can be run to failover to the HA replica
ansible-playbook tower-ha-failover.yml
Once the primary database has been repaired you must re-enable replication to synchronize data before failing back. Also ensure the database_replica group has the repaired database host if you took it out before doing the HA failover. The easiest way to enable the replication is to re-run the failover playbook.
ansible-playbook tower-ha-failover.yml
This won't have any effect on the running cluster but will re-enable replication. If you wish to be more targeted/explicit you can also run
ansible-playbook -i INV_DIR/inventory_ha tower-setup-replication.yml
HA Failback
to failback to the original configuration
ansible-playbook tower-ha-failover.yml -e 'tower_failback=1'
DR Failover
In the event of a primary datacenter outage, the playbook can be run to failover to the secondary database (including pointing to the DR replica)
ansible-playbook tower-dr-failover.yml
Once the primary datacenter has been repaired you must re-enable replication to synchronize data before failing back. Also ensure the database_replica group has the repaired database host if you took it out before doing the DR failover. The easiest way to enable the replication is to re-run the failover playbook.
ansible-playbook tower-dr-failover.yml
This won't have any effect on the running cluster but will re-enable replication. If you wish to be more targeted/explicit you can also run
ansible-playbook -i INV_DIR/inventory_dr tower-setup-replication.yml
to failback to the original configuration
ansible-playbook tower-dr-failover.yml -e 'tower_failback=1'
Backup and Restore
Ansible Tower Backup and Restore Documentation

Clustering
In addition to the base single node installation, Tower offers clustered configurations to allow users to horizontally scale job capacity (forks) on nodes. It is recommended to deploy tower nodes in odd numbers to prevent issues with underlying RabbitMQ clustering.
Tower clustering minimizes the potential of job execution service outages by distributing jobs across the cluster. For example, if you have an Ansible Tower installation with a three node cluster configuration and the Ansible Tower services on a node become unavailable in the cluster, jobs will continue to be executed on the remaining two nodes. It should be noted, the failed Ansible Tower node needs to remediated to return to a supported configuration containing three or more nodes. See setup considerations
Tower cluster nodes and database should be geographically co-located with low latency (<10 ms) and reliable connectivity. Deployments that span datacenters are not recommended due to transient spikes in latency and/or outages.
Database Availability
Ansible Tower utilizes PostgreSQL for application level data storage. The Tower setup process does not configure streaming replica configuration/hot standby configurations, which can be used for disaster recovery or high availability solutions. Streaming replication can be enabled and configured as a Red Hat Consulting delivered solution. The Tower database can be replicated to high availability instance in the local datacenter and/or to a disaster recovery instance in a remote datacenter. The later being utilized in a disaster recovery scenario. In the case of a failure in only the local database, the high availability instance can be promoted to a primary instance and the Tower cluster updated to utilize the instance. In the case of a full primary datacenter outage, the disaster recovery instance can be promoted to a primary instance a new Tower cluster deployed and pointed to the instance.
Disaster Recovery
As discussed above, Ansible Tower clusters can not span multiple datacenters and the default setup configuration does not support multiple clusters. This toolkit aims to provide a toolkit to bring a secondary cluster online.
Connect with Red Hat Services
Learn more about Red Hat Consulting
Learn more about Red Hat Training
Learn more about Red Hat Certification
Join the Red Hat Learning Community
Subscribe to the Training Newsletter
Follow Red Hat Services on Twitter
Follow Red Hat Open Innovation Labs on Twitter
Like Red Hat Services on Facebook
Watch Red Hat Training videos on YouTube
Follow Red Hat Certified Professionals on LinkedIn
執筆者紹介

チャンネル別に見る

自動化
テクノロジー、チームおよび環境に関する IT 自動化の最新情報

AI (人工知能)
お客様が AI ワークロードをどこでも自由に実行することを可能にするプラットフォームについてのアップデート

オープン・ハイブリッドクラウド
ハイブリッドクラウドで柔軟に未来を築く方法をご確認ください。

セキュリティ
環境やテクノロジー全体に及ぶリスクを軽減する方法に関する最新情報

エッジコンピューティング
エッジでの運用を単純化するプラットフォームのアップデート

インフラストラクチャ
世界有数のエンタープライズ向け Linux プラットフォームの最新情報

アプリケーション
アプリケーションの最も困難な課題に対する Red Hat ソリューションの詳細
仮想化
オンプレミスまたは複数クラウドでのワークロードに対応するエンタープライズ仮想化の将来についてご覧ください