
Apache Kafka は、高い実績と人気を誇るイベントストリーミングプラットフォームで、プロジェクトの報告によると、現時点で Fortune 100 にランクインしている企業の 60% 超で使用されています。Apache Kafka は、2011 年に Apache Software Foundation が開発した、リアルタイムでレコードストリームを公開、サブスクライブ、保存、処理できるオープンソースのソフトウェア・プラットフォームです。
そもそもイベント・ストリーミング・プラットフォームとは何でしょうか。Kafka について、半分も理解できているでしょうか。
Kafka のプロデューサー、コンシューマー、トピック、パーティションなどは、Kafka 初心者にとって理解が難しい概念です。Kafka について何かわからないことがあれば、是非この記事をお読みください。
この記事では、公開/サブスクライブ・メッセージング・パターンから Kafka Connect まで、Apache Kafka を理解するために必要な 10 の基本的な用語と概念について説明します。
1. 公開/サブスクライブ・メッセージング・パターン
Apache Kafka は、公開/サブスクライブベースのメッセージングシステムです。これは何を意味するのでしょうか。
メッセージングパターン とは、送信側と受信側の間で メッセージ (簡単に言えばデータビット) を送信する方法です。メッセージングパターンには ファンアウト や 要求/応答 などいくつかありますが、ここでは公開/サブスクライブ・メッセージング・パターンについて説明します。公開/サブスクライブ・メッセージングでは、送信側 (パブリッシャー) は単一の宛先を使用して複数のコンシューマー (サブスクライバー) にメッセージを送信します。この宛先は トピック としても知られています。

図 1. 公開/サブスクライブ・メッセージングのワークフロー。(出典)
各トピックは複数のサブスクライバーを持つことができ、すべてのサブスクライバーはトピックに公開されるすべてのメッセージを受け取ります。トピックを使用すると、瞬時にプルベースでメッセージをサブスクライバーにデリバリーできます。これは、公開/サブスクライブベースのメッセージングシステム (Apache Kafka など) が、リアルタイムで大量のデータを処理できる理由の 1 つです。
2. イベントストリーミング
イベントストリーミングは、追加機能を備えた公開/サブスクライブ・メッセージング・パターンの実装です。Apache Kafka は イベントストリーミング・プラットフォーム であるため、イベントストリームの公開やサブスクライブだけでなく、イベントの発生時には 保存 および 処理 も可能です。
イベントストリーミングにおける イベント (メッセージやレコードとも呼ばれます) とは、簡単に言えばシステムの状態変化に関する記録です。たとえば支払い処理のユースケースでは、顧客が金融取引を完了することがイベントになります。
イベントストリーム は、パブリッシャーからサブスクライバーに向かう一連のイベントです。支払い処理のユースケースでは、ビジネスで発生する金融取引に関する一連のリアルタイム情報フローがイベントストリームになります。
3. Kafka のクライアントとサーバー
Kafka におけるクライアント、サーバー、TCP (Transmission Control Protocol) の仕組みについて詳細を説明する前に、分散システム としての Kafka について把握すると理解しやすくなります。分散システムは、複数の異なるマシン上にある多数のソフトウェアコンポーネントを連携し、単一ユニットとしての実行を可能にするコンピューティング環境です。
Kafka 分散システムは、複数のデータセンター (またはクラウドインスタンス) および クライアント にまたがる 1 つ以上の サーバー (Kafka ブローカー) の クラスター で構成されています。この分散システムにより、Kafka ブローカーと通信してイベントストリームの読み取り、書き込み、処理を行うアプリケーションを作成できます。
Kafka のサーバーおよびクライアントは、サーバーとクライアントを接続する通信規格である TCP を使用してカスタムバイナリー形式で連携されるため、メッセージの相互交換が可能になります。
4. プロデューサー、コンシューマー、コンシューマーグループ
Kafka クラスターの外側には、Kafka を使用するアプリケーションである プロデューサー と コンシューマー があります。プロデューサー は、データをトピックに配置するアプリケーション (詳細は以下参照) で、コンシューマーはトピックからデータを読み取るアプリケーションです。
コンシューマーが 1 つに限定されている場合、アプリケーションはトピックパーティションからのメッセージストリームを処理しきれない可能性があります。しかし Kafka では、複数のコンシューマーを コンシューマーグループ にプルすることで、複数のコンシューマーによる複数のトピックパーティションからの読み取りが可能になり、メッセージング・スループットが向上します。
コンシューマーグループでは、複数のコンシューマーが同じトピックから読み取りますが、各コンシューマーは専用パーティションから読み取ります。詳細については No. 6 で説明しています。
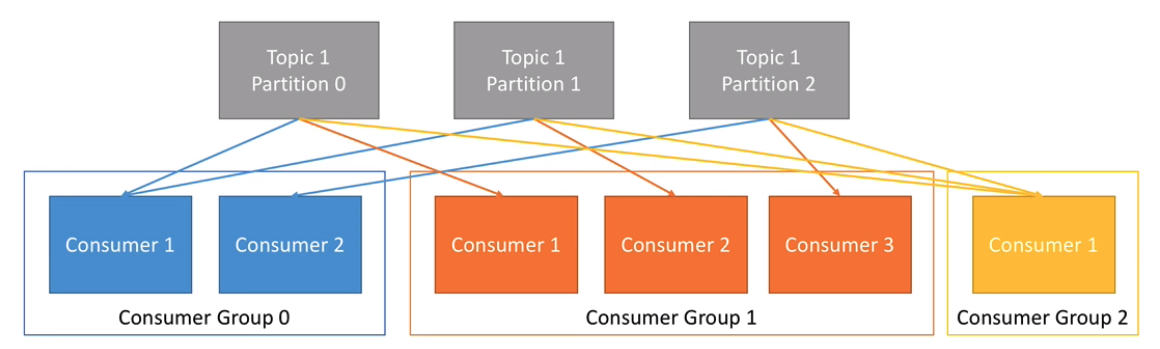
図 2. コンシューマーグループ(出典)
5. Kafka クラスターと Kafka ブローカー
名前からもわかるとおり、Kafka ブローカー はプロデューサーとコンシューマー間のトランザクションを調整します。ブローカーは、イベントの書き込みおよび読み取りに関するクライアント要求をすべて処理します。簡単に言えば、Kafka クラスター は 1 つ以上の Kafka ブローカーのコレクションです。
6. Kafka トピックと Kafka パーティション
イベントストリームについての説明を思い出してください。言うまでもありませんが、イベントは同時に多数発生するため、それらを整理する方法が必要です。Kafka では、イベントを整理するための基本ユニットを トピック と呼びます。
Kafka におけるトピックとは、データの保存先または公開先であるユーザー定義のカテゴリまたはフィードの名前です。言い換えれば、トピックとはイベントログです。たとえば、Web サイトのアクティビティを追跡するユースケースでは、「click」という名前のトピックがあり、ユーザーが特定のボタンをクリックするたびに「click」イベントを受信し、保存します。
Kafka のトピックは パーティション化 されます。つまり、トピックは別々の Kafka ブローカー上に存在できる複数のログファイルに分割されます。そうすることで、クライアントアプリケーションは多数のブローカーに対して同時に公開/サブスクライブできるだけでなく、複数のブローカーにパーティションを複製することでデータの高可用性を実現できるため、このスケーラビリティはとても重要です。クラスター内の 1 つの Kafka ブローカーがダウンした場合、Kafka は安全に別のブローカー上のパーティションレプリカにフェイルオーバーできます。
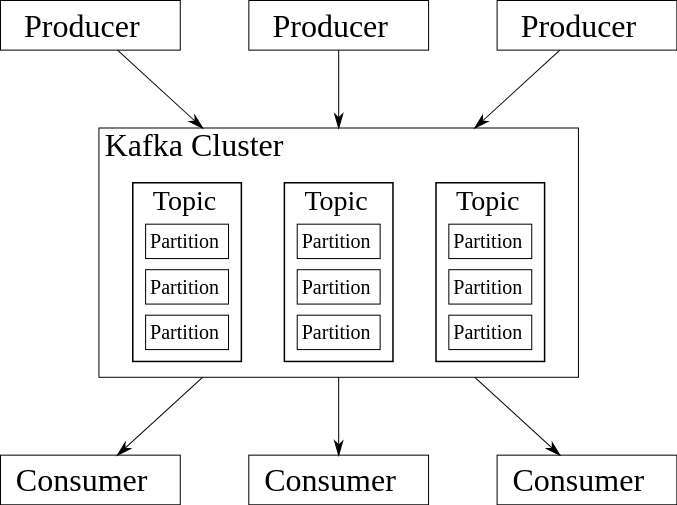
図 3.Kafka アーキテクチャの例。(出典)
{kind=link}
最後に、パーティション内におけるイベントの順序付けについて説明します。前述した Web サイトのトラフィックアクティビティ関連のユースケースを見てみましょう。このユースケースで、「click」トピックを 3 つのパーティションに分割するとします。
Web クライアントが「click」イベントをトピックに公開するたびに、そのイベントは 3 つのパーティションのいずれか 1 つに追加されます。イベントペイロードにキーが含まれる場合、そのキーを使用してパーティションの割り当てが決定されます。キーが含まれない場合、イベントはラウンドロビン方式でパーティションに送信されます。イベントはパーティション内に順次追加および保存され、各イベントが取得した個別の ID (最初のイベントは 0、2 番目のイベントは 1、など) は オフセット と呼ばれます (図 3 参照)。
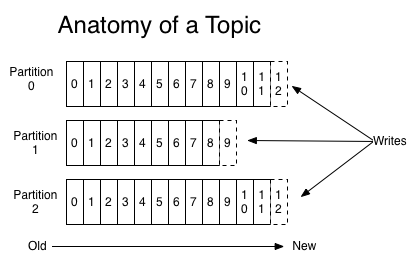
図 4. Kafka トピックの仕組み。(出典)
7. Kafka トピックのレプリケーション、リーダー、フォロワー
前述のとおり、パーティションは別の Kafka ブローカー上に配置できます。これは、Kafka をデータ損失から保護するための重要な方法であり、複数ブローカーにおけるデータのコピー数を指定する トピックレプリケーション係数 を設定することで実行できます。
たとえば、レプリケーション係数 が 3 の場合、別のブローカーのパーティションごとにトピックのコピーが 3 つ保持されます。
この場合、クラスター内に実際のデータとそのコピーの両方が存在するという混乱が予測されますが、たとえばプロデューサーには特定のパーティションのデータを公開するブローカーを判別する方法が必要であり、混乱を回避するためにも Kafka ではリーダー/フォロワーシステムが適用されています。このシステムでは、1 つのブローカーをトピックパーティションの リーダー に、残りのブローカーをそのパーティションの フォロワー に設定し、リーダーのみクライアント要求を処理できるように設定できます。
8. Apache ZooKeeper
実稼働環境では、Apache Software Foundation の別プロジェクトである Apache ZooKeeper で Kafka を使用する可能性が高いと考えられます。ZooKeeper は、分散アプリケーションの連携と管理に使用できる中央集中型サービスです。
前述のとおり、Kafka は分散システムです。Kafka は、ZooKeeper を使用して選択の実行 (コントローラーおよびトピックリーダー)、トピックの設定 (トピック一覧の維持、それぞれのパーティション数など)、メタデータの保存 (パーティションの場所など)、Kafka ブローカーのステータス追跡などを行います。
(ZooKeeper は Apache Kafka 3.0.0 から 段階的に廃止 されています)
9. Kafka Connect
Kafka Connect は、Apache Kafka のデータ統合フレームワークです。基本的には、メッセージキューやリレーショナルデータベースなどの外部ソースから Kafka クラスターにデータを取得するために Kafka Connect を使用できます。また、クラスターからデータを (別の場所で保存または同期するために) 取得する際にも使用できます。
その場合、一般的なデータストアへの接続に使用するコードの再利用可能部である コネクター を使用します。独自コネクターの起動は非常に難しいため、一般的に開発者は Kafka コミュニティで開発およびサポートされている既存のコネクターを使用します。
Kafka には 2 種類のコネクターがあります。ソースコネクター はデータストアからデータを取得するコネクター、シンクコネクター は Kafka トピックからデータストアにデータを提供するコネクターです。
10. Kafka Streams
Kafka Streams は、Kafka トピック内でデータを処理および変換できるストリーミングアプリケーションをビルドする Java API です。つまり、Kafka Streams を使用すると、リアルタイムでトピックからデータを読み取り、そのデータを処理 (フィルタリング、グループ化、集計など) し、処理後のデータを別のトピックやレコードシステムに書き込むことができます。
Red Hat OpenShift Streams for Apache Kafka
以上が、Apache Kafka のいくつかの基本用語と概念に関する説明です。プロデューサー、コンシューマー、コンシューマーグループをはじめとする Kafka の用語はわかりにくく、読み進めるのも容易ではなかったかもしれません。
Apache Kafka により多くのことが簡単になりますが、面倒な作業も少なくありません。
たとえば、Apache Kafka にはデータ検証がありません。明確に定義されたデータスキーマ が存在しないため、コンシューマーはプロデューサーからのデータを理解できない可能性があります。また、Apache Kafka の Day 2 オペレーション ではモニタリング、ロギング、アップグレードなどの管理作業を行う必要があり、これも手間がかかります。
このような多くの課題に対応できるのが、マネージド・クラウド・サービスの Red Hat OpenShift Streams for Apache Kafka です。クラウドサービスファミリーと Red Hat OpenShift 製品ファミリーに属する OpenShift Streams for Apache Kafka には、Kafka のエコシステムが含まれています。パッケージ化されているため Kafka のコア・テクノロジーに限定されず、多岐にわたるデータ駆動型ソリューションの構築に役立ちます。
それだけではありません。Red Hat OpenShift Streams for Apache Kafka のホスト型マネージド・サービスを、今すぐ無料で お試し いただけます (任意のアプリケーションとの接続も可能)。
関連情報
- ブログ投稿:Apache Kafka の使用に関する一般的な 3 つの課題
- ドキュメント:Red Hat OpenShift Streams for Apache Kafka の製品ドキュメント
- eBook:イベントメッシュ:入門編
- ウェビナー:企業における Kafka について
- Blueprint:ハイブリッドクラウド Blueprint のイベント駆動型アーキテクチャ
執筆者紹介
Bill Cozens is a recent UNC-Chapel Hill grad interning as an Associate Blog Editor for the Red Hat Blog.
類似検索
vi エディター入門
急激に進化する AI の脅威に対応する防御作とは
Container Roundup | Compiler
Untangling Networks | Compiler
チャンネル別に見る

自動化
テクノロジー、チームおよび環境に関する IT 自動化の最新情報

AI (人工知能)
お客様が AI ワークロードをどこでも自由に実行することを可能にするプラットフォームについてのアップデート

オープン・ハイブリッドクラウド
ハイブリッドクラウドで柔軟に未来を築く方法をご確認ください。

セキュリティ
環境やテクノロジー全体に及ぶリスクを軽減する方法に関する最新情報

エッジコンピューティング
エッジでの運用を単純化するプラットフォームのアップデート

インフラストラクチャ
世界有数のエンタープライズ向け Linux プラットフォームの最新情報

アプリケーション
アプリケーションの最も困難な課題に対する Red Hat ソリューションの詳細
仮想化
オンプレミスまたは複数クラウドでのワークロードに対応するエンタープライズ仮想化の将来についてご覧ください