Like any building, a Red Hat OpenShift cluster using the Red Hat OpenShift Virtualization Operator should have a solid foundation to build from.
This blog covers configuring one piece of that foundation—storage.
I will utilize an existing NetApp appliance for a cluster's storage needs. I'll use the open source Astra Trident (Trident) storage provisioner. It is easy to configure and use.
The provisioner is provided, maintained, and fully supported by NetApp.
The article covers creating and configuring a Storage Virtual Machine (SVM) on the NetApp that provides storage to clusters using the Trident provisioner with a Network File System (NFS) backend.
A previous blog post written by Bala Ramesh does a great job of walking through one method of installing the Trident provisioner.
The documentation also effectively presents several methods to install Trident in a cluster.
One method is using the Trident operator.
Using the operator provides several benefits, such as self-healing and automatically handling updates and upgrades.
Environment
The environment uses a six-node OpenShift cluster, a NetApp appliance, and two networks.
The first network is a lab network called the Data network. It is used to connect to the server and NetApp appliance for administration. This network can route to other networks and the internet.
The Data network is also used for external pod and VM communications. It has a Classless Inter-Domain Routing (CIDR) address specification of 192.168.50.0/24.
The second network is used for storage traffic and is called the Storage network. The Storage network interface is configured using the NMState Operator after the cluster is installed. It has a CIDR of 172.31.0.0/16.
The OpenShift cluster has three control plane nodes and three worker nodes. All the nodes connect to the Data network while only the worker nodes connect to the Storage network.
- The NetApp appliance connects to the Data network for management purposes.
- The SVMs are connected to the Storage network.
- The NetApp storage is split equally into two aggregates, aggregate_01 and aggregate_02.
- The NetApp contains a single ipspace called Default.

SVMs
An SVM on the NetApp provides the backend storage for the Trident provisioner. You can configure the Trident provisioner to use NFS shares or iSCSI LUNs for its backend storage. A single SVM created on the NetApp can provide the NFS shares, iSCSI LUNs, or both.
I will create a single SVM for NFS storage.
Using NFS with Trident for backend storage
To use NFS on the NetApp for storage, configure an SVM on the NetApp, configure a Trident backend, and then the cluster.
This process is simple and involves the following steps. Note that the NetApp configuration is done from the NetApp's command line.
On the NetApp:
- Create an SVM
- Configure protocols
- Add an access rule to the default export policy
- Create Logical InterFaces (LIF) on the SVM
- Enable NFS on the SVM
On the cluster :
- Install the Trident provisioner (refer to the Trident documentation and linked blog post above on installing it)
- Configure a backend
- Create a storageClass
- Finally, test the NFS backend
Create an SVM
An SVM is also referred to as a vserver when issuing commands to the NetApp from the command line.
Create an SVM called svm_nfs in the Default ipspace. Place its root volume on the aggregate_01 disk aggregate. Specify that the SVM will provide NFS data services on its interfaces.
vserver create -vserver svm_nfs -aggregate aggregate_01 -data-services data-nfs -ipspace Default
Set allowed protocols for the SVM
The SVM should run at least the NFS protocol. Configure this by modifying the SVM and allowing the NFS protocol. Other protocols can be optionally disabled if not needed.
The following command adds NFS to the SVM's allowed protocols.
vserver add-protocols -vserver svm_nfs -protocols nfs
You can optionally disable unused protocols.
vserver remove-protocols -vserver svm_nfs -protocols cifs,fcp,iscsi,ndmp,nvme,s3
Add a rule to the default export policy
The default export policy does not contain any rules when the SVM is created. You must create at least one rule to allow the SVM to export NFS shares to the nodes on the storage network.
The following rule is very permissive and allows all levels of permissions to the NFS exports to every system on the storage network. This configuration may not be a good practice in a production environment.
This permissive rule is not much of an issue in my environment since this is a closed and non-routable network. Please see the official NetApp documentation for information on making this more secure for your environment.
vserver export-policy rule create -vserver svm_nfs -policyname default -clientmatch 172.31.0.0/16 -rorule any -rwrule any -superuser any -allow-suid true
Create LIF(s) on the SVM
The SVM was created without a logical interface (LIF). It must have at least one LIF defined for network traffic to pass into and out of the SVM.
When creating the LIF, a home node and port can be specified. This is not required but is useful with a NetApp that sits on multiple networks or if you wish to balance the NetApp's interface traffic manually.
The following command specifies a home node and port. The home node specifies a NetApp controller and the port is a port defined on the NetApp. You can view both using the network port show command on the NetApp.
It also specifies a required IP address for the LIF and its netmask length. The default-data-files service policy is used.
network interface create -vserver svm_nfs -lif lif_svm_nfs_storage -home-node node_01 -home-port a0b -address 172.31.131.40 -netmask-length 16 -service-policy default-data-files
You now have a LIF for the actual data to go across, but the service policy default-data-file does not allow management traffic. You have a few options for management traffic. You can create a second LIF for management traffic, create a new service policy that allows both NFS data traffic and management traffic, or modify the default-data-files service policy.
I will take the easy route and create a second LIF since many extra IP addresses are available. If you want to modify the default-data-files service policy or create a new one, please see the network interface service-policy command in the NetApp documentation.
The following command creates a LIF and assigns the SVM's default-management service policy to the LIF. This policy allows management traffic.
network interface create -vserver svm_nfs -lif lif_svm_nfs_mgmt -home-node node_01 -home-port a0b -address 172.31.132.40 -netmask-length 16 -service-policy default-management
Add an aggregate to the SVM
The SVM itself was created on the aggregate_01 disk aggregate. This does not mean the aggregate is used to create volumes. Any aggregate can be used to create the volumes, but it must be specified. You need to assign an aggregate to the SVM for data volumes.
I will use the same aggregate as the SVM's root volume.
vserver add-aggregates -vserver svm_nfs -aggregates aggregate_01
Add NFS to the SVM
To get the NFS service running on the SVM, you need to enable it.
vserver nfs create -vserver svm_nfs
Once the NFS service is enabled, you can view its mounts from any system that matches the export policy rule you created earlier.
$ showmount -e 172.31.131.40
Export list for 172.31.131.40:
/ (everyone)
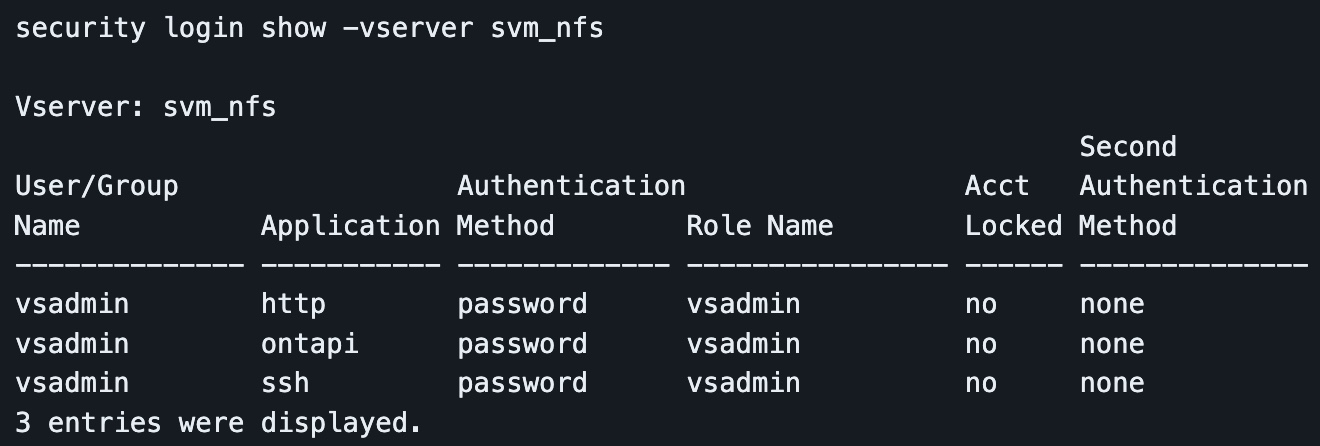
Set a password
The Trident provisioner authenticates to the SVM to create and delete the volumes for the PVs. It connects with the SVM using either credential-based or certificate-based authentication. Please see the Trident documentation for more information on authentication settings.
I will use credential-based authentication. A user account with admin privileges is needed and can be created, but the documentation recommends using the existing vsadmin user account. Set a password for this account. I will use a password of changem3.
security login password -vserver svm_nfs -username vsadmin
Enter a new password:
Enter it again:
This account is also locked by default. The following command unlocks it.
security login unlock -vserver svm_nfs -username vsadmin
Confirm the account is no longer locked.
Create a backend for Trident
Before performing the following steps, install the Trident provisioner using the documentation and blog post mentioned earlier.
Note: If your cluster uses the OVNKubernetes network stack, you may need to enable routingViaHost for the operator to install. Please see this KCS article for more information.
The following JSON file creates a backend for the trident provisioner. Please see the Trident documentation on the available options. Some options are discussed below.
{
"version": 1,
"storageDriverName": "ontap-nas",
"backendName": "nfs-svm",
"managementLIF": "172.31.132.40",
"dataLIF": "172.31.131.40",
"svm": "svm_nfs",
"username": "vsadmin",
"password": "changem3",
"storagePrefix": "cluster01",
"nfsMountOptions": "nfsvers=4.1",
}
The following explanations apply to the entries in the file above:
storageDriverName
This option specifies which driver to use when communicating to the NetApp. I chose ontap-nas because it suits most cases. This driver creates a FlexVol for each PV requested by the OpenShift cluster. These volumes are created on the SVM's aggregate.
managementLIF
This is the IP address for the LIF that allows management traffic; it is the second LIF created above.
dataLIF
This is the IP address for the LIF for data; it is the first LIF created above.
storagePrefix
The string specified here is prepended to the name of any volumes created on the NetApp. I like to specify this because it makes identifying which cluster a volume belongs to easier. This helps in cleaning up stale volumes.
This can also be used when multiple clusters use the same SVM. I don't think I would use a single SVM for multiple clusters in a production environment, but I have used it in a non-production lab/testing environment.
Note: I recommend using unique short names for each cluster's nodes if multiple clusters connect to the same SVM. I have seen nodes denied NFS access when two different clusters use the same names for their nodes, such as worker-0, worker-1, etc. There is a discussion on the NetApp community site concerning this.
Once the JSON file is created, run the tridentctl command to create the backend. The trident operator is installed in the trident namespace of the cluster.
tridentctl -n trident create backend -f backend.json
Check to see that the backend is created and online.

Create a storageClass
Now that you have configured Trident and you have a working backend, it is time to create a storageClass to use.
Create the storageClass from the command line using a YAML file.
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: trident-nfs-svm
annotations:
storageclass.kubernetes.io/is-default-class: "true"
provisioner: csi.trident.netapp.io
reclaimPolicy: Delete
allowVolumeExpansion: true
volumeBindingMode: Immediate
parameters:
backendType: "ontap-nas"
The YAML file sets an annotation, making this storageClass the cluster default. The YAML makes sure that allowVolumeExpansion is set to true. The need for this will be discussed when a VolumeSnapshotClass is created. The provisioner and backendType are specified. Be sure the backendType is the same as the storageDriverName specified in the backends JSON file.
Apply the YAML to the cluster to create the storage class.
oc create -f storage-class.yaml
After applying the YAML, you can see the new storageClass.

Create a VolumeSnapshotClass
A VolumeSnapshotClass allows the cluster to use the snapshot capabilities of the underlying storage when cloning PVCs for VM creation. This can drastically speed up the time it takes to clone a PVC.
It is important that allowVolumeExpansion is set to true in the StorageClass used with the Trident provisioner. OpenShift Virtualization checks if the StorageClass allows volume expansion before attempting a snapshot clone. If resizing of the PVC is allowed, then a snapshot is taken and restored into a PVC that has been resized appropriately.
The following YAML defines a VolumeSnapshotClass for a StorageClass that specifies csi.trident.netapp.io as its provisioner in its configuration.
apiVersion: snapshot.storage.k8s.io/v1
kind: VolumeSnapshotClass
metadata:
name: csi-snapclass
annotations:
snapshot.storage.kubernetes.io/is-default-class: "true"
driver: csi.trident.netapp.io
deletionPolicy: Delete
Apply the YAML to create a VolumeSnapshotClass.
oc create -f volume-snapshot-class.yaml
After applying the YAML, the new VolumeSnapshotClass is created.

Test the NFS backend
After the backend works and a default storageClass is specified, the Catalog populates with the Red Hat-provided DataSources. The Catalog can take a few minutes to populate.
Next, create a VM that will utilize the newly created storage. You can do this through the OpenShift UI.
Navigate to Catalog or VirtualMachines and select Create Virtual Machine.
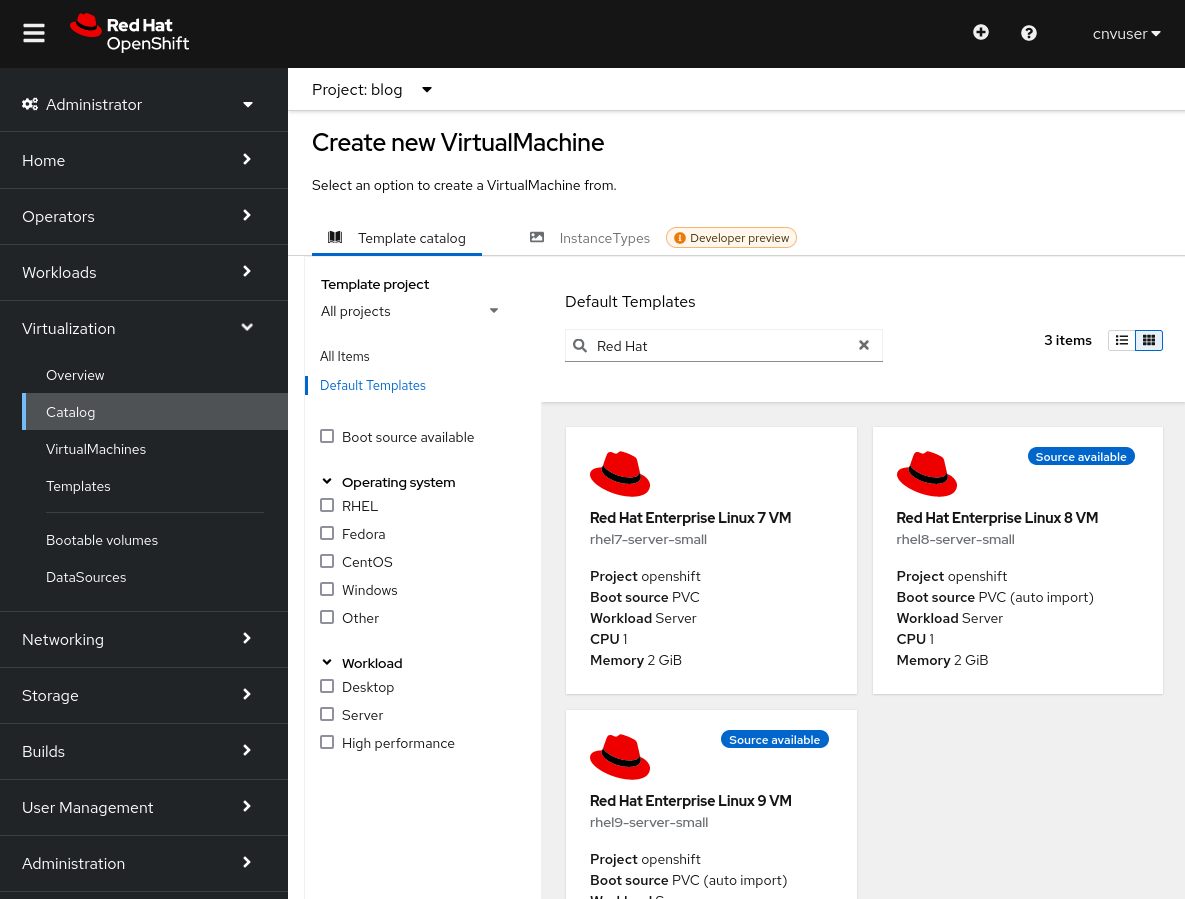
Select the Red Hat Enterprise Linux 9 VM.
On the next page, select Customize VirtualMachine. Change the name to rhel9-nfs so you can easily identify it. Select Optional parameters and change the password to something you can remember.

Select Next and then Create VirtualMachine.
The VM should start provisioning.
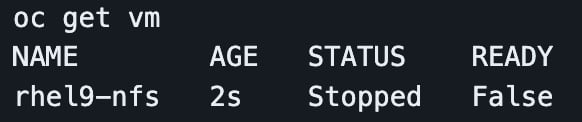
A rhel9 image is cloned to the VM's PV during provisioning. If the VolumeSnapshotClass is working, this should only take a few seconds.

Once the VM is provisioned, you should see its PVC using the trident-nfs-svm storageClass created earlier.

And you also have a PV.

Looking at the NetApp, you can see the volume was created with the name of the PVC. Notice that the PVC is prepended with the string specified for the storagePrefix field in the backend configuration file.

Final thoughts
As you can see, configuring a Red Hat OpenShift cluster to use a NetApp appliance for VM storage is fairly easy. It provides some useful features, such as prepending a custom string to the volumes created on the NetApp and providing quick snapshots.
I will create a follow-up blog on using the same NetApp but with iSCSI LUNs presented to the cluster.
執筆者紹介

チャンネル別に見る

自動化
テクノロジー、チームおよび環境に関する IT 自動化の最新情報

AI (人工知能)
お客様が AI ワークロードをどこでも自由に実行することを可能にするプラットフォームについてのアップデート

オープン・ハイブリッドクラウド
ハイブリッドクラウドで柔軟に未来を築く方法をご確認ください。

セキュリティ
環境やテクノロジー全体に及ぶリスクを軽減する方法に関する最新情報

エッジコンピューティング
エッジでの運用を単純化するプラットフォームのアップデート

インフラストラクチャ
世界有数のエンタープライズ向け Linux プラットフォームの最新情報

アプリケーション
アプリケーションの最も困難な課題に対する Red Hat ソリューションの詳細
仮想化
オンプレミスまたは複数クラウドでのワークロードに対応するエンタープライズ仮想化の将来についてご覧ください