

InstructLab は、コミュニティ主導のプロジェクトで、合成データの生成を通じて大規模言語モデル (LLM) への貢献とその強化を行うプロセスを簡単にするための取り組みです。この取り組みは、LLM への貢献の複雑さ、フォークモデルによって引き起こされるモデルのスプロールの問題、コミュニティの直接的なガバナンスの欠如など、開発者が直面している複数の課題に対処するものです 。InstructLab は Red Hat と IBM Research による支援の下で、新しい合成データに基づくアライメント・チューニング手法を活用してモデルのパフォーマンスとアクセシビリティを強化することを目指しています。ここでは、モデルを従来の方法でファインチューニングする際に生じる現在の問題や技術的な課題、および InstructLab が採用している解決アプローチについて説明します。
課題:データの品質が低い、計算リソースが効率的に使用されていない
LLM 分野での競争が激化するなか、インターネットで公開されている膨大な量の情報からトレーニングする大規模モデルの構築が主流になっているように思われます。しかしインターネットには、モデルのコア機能に役立たない冗長な情報や非自然言語データも大量に含まれています。
たとえば、後のバージョンのベースとなった LLM GPT-3 のトレーニングに使用されたトークンの 80% は、膨大な Web ページを含む Common Crawl に由来しています。このデータセットは、高品質のテキスト、低品質のテキスト、スクリプト、その他の非自然言語データが混在していることで知られています。データの大部分は役に立たない、または品質の低いコンテンツであると推定されています (Common Crawl の分析)。
厳選されていないデータが広範に存在すると、計算リソースの使用効率が低下し、トレーニングコストが上昇します。結果的には、モデルの利用者に費用が転嫁されるだけでなく、モデルをローカル環境に実装する際の課題も生じます。
現在の傾向では、データの量ではなくデータの質と関連性が重要になる、パラメータの少ないモデルが増えています。モデルの精度が改善し、意図的なデータキュレーションが増えれば、パフォーマンスは改善し、必要な計算リソースは減り、結果の品質は向上します。
InstructLab のソリューション:合成データの生成を改良
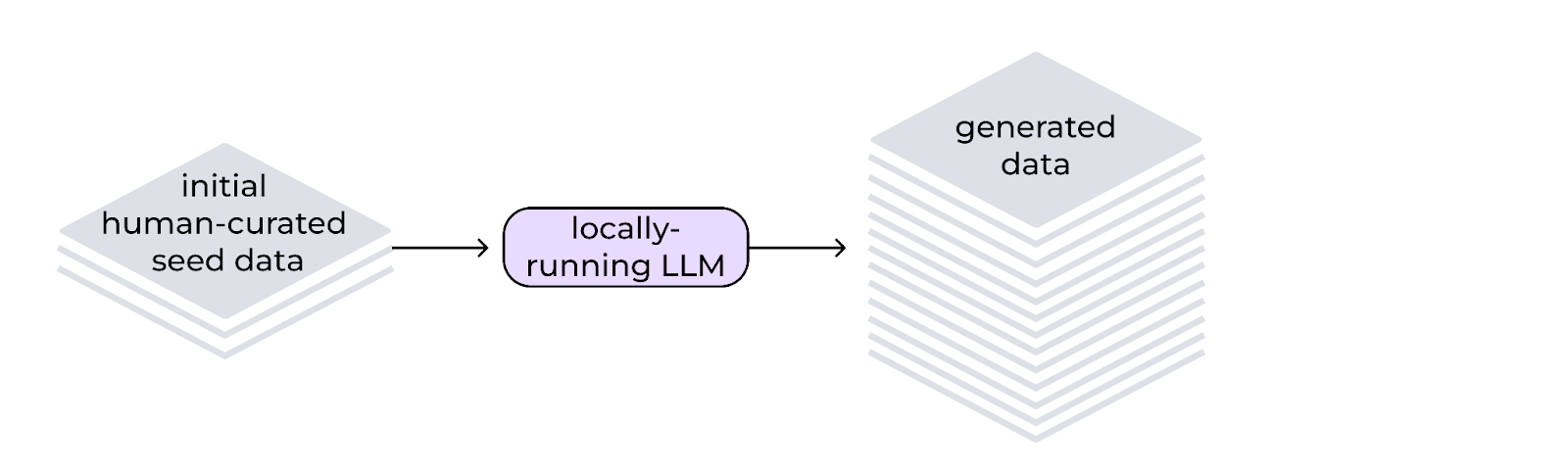
InstructLab の特徴は、最初はごく小さな初期データセットで、トレーニングに使用する大量のデータを生成できる点です。InstructLab が採用している Large-scale Alignment for chatBots (LAB) の手法は、人間が生成したデータと計算オーバーヘッドを最小限に抑えて LLM を強化します。これにより、個人は手軽に関連データを提供できるようになります。この関連データは、生成プロセスを支援するモデルを使用した合成データの生成により強化されます。

InstructLab のアプローチの主な特長:
分類を活用したデータキュレーション
最初のステップは、分類 (多様なスキルと知識の領域を整理する階層構造) の作成から始まります。この分類は、人間が作成した最初の例をキュレートするためのロードマップとして機能します。人間が作成した例は、合成データ生成プロセスにおけるシードデータとして機能します。このデータの構造では、モデルの既存の知識を探索して貢献できる部分 (ギャップ) を見つけることが簡単になるため、冗長で整理されていない情報が削減されます。同時に、質問と回答のペア形式で簡単にフォーマットされた YAML ファイルのみを使用して、モデルのターゲットをユースケースや特定のニーズに設定することができます。

合成データの生成プロセス
InstructLab は教師モデルを活用することで、データ生成プロセス中に、基盤となるシードデータから新しい例を生成します。重要な点として、このプロセスは教師モデルが保存した知識ではなく、特定のプロンプトテンプレートを使用します。このテンプレートは、データセットを大幅に拡張し、新しい例について、人間がキュレーションした元のデータの構造と意図を維持できることが特徴です。LAB 手法では、次の 2 つの合成データジェネレーターを使用します。
- スキルの合成データ生成ツール (Skills-SDG):指示の生成と評価、応答の生成、および最終のペア評価にプロンプトテンプレートを使用します。
- 知識 SDG:教師モデルではカバーされないドメインの指示データを生成し、生成されたデータを裏付けるために外部の知識ソースを使用します。
幸いなことに、これにより、手動でアノテーションを付けられた大量のデータの必要性が大幅に減少します。小規模でユニーク、かつ人間が生成した例を参照として使用することで、数百から数千、または数百万に及ぶ質問と回答のペアをキュレーションし、モデルの重みとバイアスに影響を与えることが可能になります。
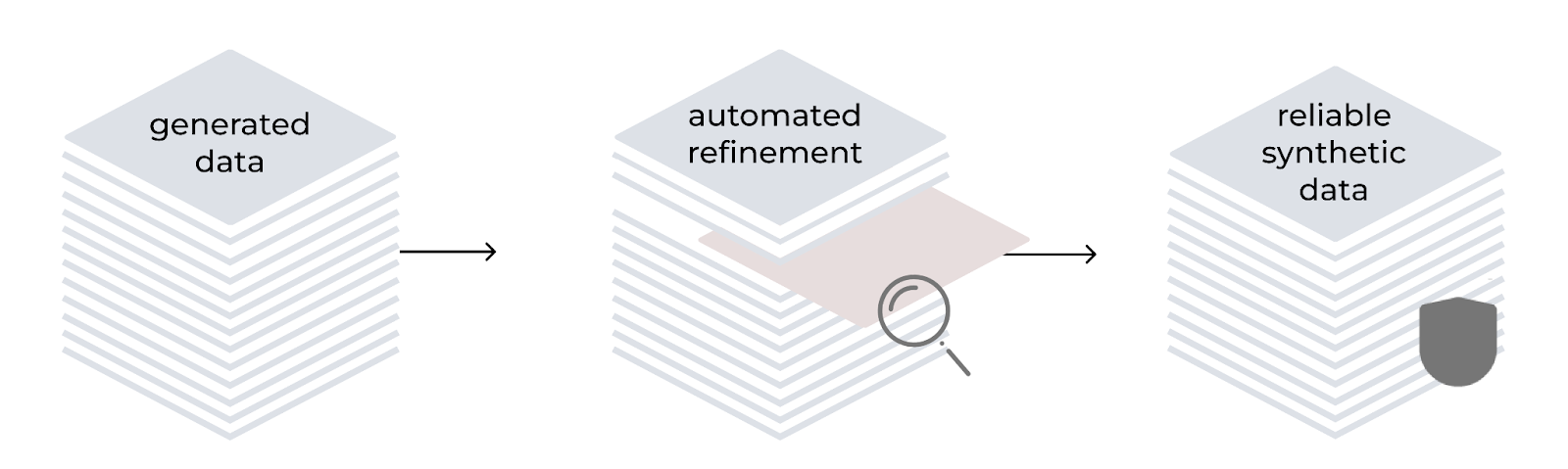
自動化された改良プロセス
LAB 手法には、合成的に生成されたトレーニングデータの品質と信頼性を向上させるための、自動化された改良プロセスが組み込まれています。これは、階層的な分類に基づいて、モデルを生成ツールおよび評価ツールとして使用します。このプロセスには、指示の生成、コンテンツのフィルタリング、応答の生成、3 段階評価システムを使用したペア評価が含まれます。知識ベースのタスクの場合、生成されたコンテンツは信頼性の高いソースドキュメントを基礎としており、これは専門的なドメインで起こりがちな不正確さに対処するものとなっています。
多段階チューニング・フレームワーク
InstructLab は、モデルのパフォーマンスを段階的に向上させる多段階のトレーニングプロセスを実装しています。この段階的なアプローチは、トレーニングの安定性を維持するのに役立ちます。データの再生バッファによって、破局的忘却を回避できるので、モデルは継続的に学習し、改善していくことができます。生成された合成データは、次の 2 段階のチューニングプロセスで使用されます。
- 知識のチューニング:新しい事実情報を統合し、短い応答のトレーニングと、その後の長い応答のトレーニング、および基礎スキルの習得に分けて実施されます。
- スキルのチューニング:構成的なスキルに重点を置いて、さまざまなタスクやコンテキストにおいて知識を応用できるようモデルの能力を強化します。

このフレームワークでは、学習率が小さく、ウォームアップ期間が延長され、実質的なバッチサイズが大きいため、安定性が確保される。
反復的な改善サイクル
合成データの生成プロセスは、繰り返しを前提としています。分類体系に新たな貢献が加わるたびに、それらを使って新たな合成データを生成され、これによってモデルをさらに強化することができます。このように改善を繰り返すことで、モデルを常に最新の状態に保ち、その関連性を維持できます。
InstructLab の結果と重要性
InstructLab の重要性は、プロプライエタリなモデルに依存せず、公開されている教師モデルを使用して最先端のパフォーマンスを達成できる点にあります。ベンチマークでは、InstructLab の手法は有望な結果を示しています。たとえば、LAB でトレーニングされたモデルを Llama-2-13b (結果的には Labradorite-13b) と Mistral-7B (結果的には Merlinite-7B) に適用した場合、これらのモデルは MT-Bench スコアにおいて、それぞれのベースモデルでファインチューニングされた現在の最高のモデルよりも優れたパフォーマンスを発揮しました。さらに、これらのモデルは MMLU (マルチタスク言語理解のテスト)、ARC (推論能力の評価)、HlaSwag (常識的推論の評価) など、他のメトリクスでも高いパフォーマンスを維持しました。

コミュニティベースのコラボレーションとアクセシビリティ
InstructLab の大きなメリットの 1 つは、そのオープンソースの性質にあります。これは、モデルの未来を形作る際に誰でも参加できるようにする仕方で生成 AI を民主化するという目標の達成に役立ちます。コマンドラインインタフェース (CLI) は、個人用ノートパソコンなどの一般的なハードウェアで使うことを想定しているため、開発者やコントリビューターにとって使用のハードルが低くなります。また、InstructLab プロジェクトでは、メンバーが、定期的に構築され、Hugging Face でリリースされる主なモデルに新しい知識やスキルを提供できるようにすることで、コミュニティへの参加を促進しています。最新のモデルをご確認ください。

LAB 手法に基づいて構築された InstructLab の合成データ生成プロセスは、生成 AI の分野における大きな進歩を意味します。InstructLab は、新しい機能と知識ドメインによって LLM を効率的に強化することで、AI 開発における協調的で効果的なアプローチへの道を切り開いています。このプロジェクトの詳しい情報は、instructlab.ai をご覧ください。または、お使いのマシンで InstructLab を試すには、スタートガイドをご利用ください。
執筆者紹介
Cedric Clyburn (@cedricclyburn), Senior Developer Advocate at Red Hat, is an enthusiastic software technologist with a background in Kubernetes, DevOps, and container tools. He has experience speaking and organizing conferences including DevNexus, WeAreDevelopers, The Linux Foundation, KCD NYC, and more. Cedric loves all things open-source, and works to make developer's lives easier! Based out of New York.
Legare Kerrison is a Technical Marketing Manager and Developer Advocate working on Red Hat's Artificial Intelligence offerings. She is passionate about open source AI and making technical knowledge accessible to all. She is based out of Boston, MA.
類似検索
vi エディター入門
急激に進化する AI の脅威に対応する防御作とは
Scaling with Orchestrators | Compiler
Container Roundup | Compiler
チャンネル別に見る

自動化
テクノロジー、チームおよび環境に関する IT 自動化の最新情報

AI (人工知能)
お客様が AI ワークロードをどこでも自由に実行することを可能にするプラットフォームについてのアップデート

オープン・ハイブリッドクラウド
ハイブリッドクラウドで柔軟に未来を築く方法をご確認ください。

セキュリティ
環境やテクノロジー全体に及ぶリスクを軽減する方法に関する最新情報

エッジコンピューティング
エッジでの運用を単純化するプラットフォームのアップデート

インフラストラクチャ
世界有数のエンタープライズ向け Linux プラットフォームの最新情報

アプリケーション
アプリケーションの最も困難な課題に対する Red Hat ソリューションの詳細
仮想化
オンプレミスまたは複数クラウドでのワークロードに対応するエンタープライズ仮想化の将来についてご覧ください