
I recently implemented a complete backup solution for our Red Hat OpenShift clusters. I wanted to share the challenges we faced in putting together the OpenShift backups, restores, hardware migrations, and cluster-cloning features we needed to preserve users’ Persistent Volume Claims (PVCs).
At the moment, these features are not implemented directly in Kubernetes, and it doesn't come out-of-the-box with any Kubernetes distribution. There are some third-party products and projects that address some of these needs, such as Velero, Avamar, and others, but none of them were a complete fit for our requirements.
The existing options I checked didn’t fit my needs for a variety of reasons:
- Price / licenses: For some of the solutions I checked you need to purchase a license. We wanted to avoid this if possible, ideally using open-source software.
- Security: As a basic means of reducing the exposed surface, we avoided anything that relied on Kubernetes NodePorts or privileged pods.
- It implies development changes: You need to apply the sidecar pattern to your custom templates (or the templates that come out of the box with OpenShift), custom resources, … as the architecture of the solution needs that pattern to work.
- Other solutions need to install custom components (often a centralized control plane server and their own CLI tool).
For this reason I decided to implement a homemade solution. In short, this solution makes it easy to:
- Backup your current PVC in another PVC.
- Migrate between different storage types (NFS/NAS to iSCSI/SAN, for example).
- Clone your PVC as many times as you want.
This post describes the PVC backup system I put together. Note that this solution addresses only backing up and migrating user volumes, not Kubernetes control plane data and configuration, such as etcd.
Traditionally, backup and restore operations involve two different layers. The first is the application layer. Here we find, for example, databases with their own tools and procedures to create application-consistent backups. The other layer is the underlying storage. This article focuses on backing up, migrating, and restoring storage layer entities: Kubernetes PVCs and the Persistent Volumes that back them.
Considerations
Some files, such as a database’s backing store, may be written to in an almost constant stream. Backing up these files requires more consideration than backing up files that change less frequently, such as documents, pictures, or finished sound and video used for playback.
Describing best practices for backing up open files and databases is out of the scope of this article, but we tend to use the database’s native tools for backing up & restoring (e.g., mysqldump, pg_dump, etc.). A complete example of this can be found in the OpenShift documentation.
You can use a mix of your database’s backup tooling with the solution described in this article to get complete backups of database snapshots as part of the backup of Persistent Volumes. For example:
- Backup database (
mysqldump). - Store all dumps in your PV.
- Backup that PV with our custom solution. You might call this an archive PV.
- Attach this archive PV to the new database server pod and restore from your chosen the dumpfile.
Architecture
The architecture is relatively simple. The core component is a pod based on a custom container image. This pod is responsible for running the backup script.

As you can see in the above image, the BackupEr pod has access to the PVC of the MyPod pod that is deployed in the OpenShift Project creatively named MyProject. BackupEr also has its own PVC. When BackupEr starts, it runs the backup.sh script to copy the data from MyPod’s source PVC to its own target PVC.
There you are: A tool to backup, migrate, or clone your PVs inside an OpenShift Kubernetes cluster!
If you want to learn more or refresh your knowledge about persistent storage, check out the Persistent Storage topic in the OpenShift documentation.
Caveats
For NAS PVs:
If you've followed the security recommendations to setup an NFS server to provision persistent storage to your OpenShift Container Platform (OCP) cluster, the owner ID 65534 is used as an example. Even though NFS’s root_squash maps root (UID 0) to nfsnobody (UID 65534), NFS exports can have arbitrary owner IDs. Owner 65534 is not required for NFS exports.
This means that even if you have
rootaccess to the OCP node where the NFS mount point was provisioned, you likely won’t have read/write permissions to files stored on that mount point. The backup script contains a little magic especially for this case:
- The docker image doesn't need to run as root, but it requires a small but important trick before it is executed:
chmod u+s /usr/bin/sed && \
chmod +x $IMAGE_SCRIPTS_HOME/backup.sh
Setting the sticky bit on the
sedexecutable makes the effectiveUIDofsedprocesses that of the/usr/bin/sedexecutable file’s owner -- in this case,root-- rather than that of the user who executed it. -
The
backup.shscript then uses this SUIDsedto arrange file access from the source to the target PVC:- Gets the
uidandgidof the files in the PVC you want to clone. - Uses
sedto modify the BackupEr pod’s/etc/passwdand/etc/groupto add the UID/GID obtained in the previous step. - Runs
rsyncundersuto impersonate the UID/GID added to the pod’s user database files..
- Gets the
NOTE: You can see the complete
Dockerfileandscriptat following URLs:
- Dockerfile
- backup.sh
We will discuss the security implications of this UID munging later in this post.
For SAN PVs:
The only constraint here is to deploy the BackupEr pod on the same OpenShift cluster node with the pod/PVC you want to back up. Set the spec.nodeName of the BackupEr pod to the desired OCP node. You can see an example by reviewing the backup-block template.
A snippet:
apiVersion: v1
kind: Pod
metadata:[...]
spec:
containers:
[...]
dnsPolicy: ClusterFirst
nodeName: ${NODE}
[...]
Prerequisites
For the purposes of this article:
- You must have an OCP cluster running OpenShift version 3.9 or greater to provide the required
ValidatingWebhookConfigurationfeature. - You must build the BackupEr container image and push it to your container registry, or use the custom templates, or simply
docker pull quay.io/josgonza/pvc-backup:latest.
Installation
In OpenShift (with cluster-admin or similar privileges for steps 1 and 2, and oc adm command from step 3):
- Adjust OpenShift Security Context Constraints (SCCs) once, before making your first backup:
oc create -f https://raw.githubusercontent.com/josgonza-rh/pvc-backup/master/openshift/scc_restricted-runasnonroot-uid.yaml
- Add
BackupErtemplates to the platform. This is optional, but if you want to use the templates, do this before making your first backup:oc create -f https://raw.githubusercontent.com/josgonza-rh/pvc-backup/master/openshift/temp_backup-block.yaml -n openshift
oc create -f https://raw.githubusercontent.com/josgonza-rh/pvc-backup/master/openshift/temp_backup-shared.yaml -n openshift
- Add the adjusted SCC from step 1 to the ServiceAccount created by the template:
oc adm policy add-scc-to-user restricted-runasnonroot-uid -z pvc-backup-deployer -n myproject
Backing up
To perform a PVC backup, deploy the BackupEr pod:
## Using templates installed in step 2:#### ex How to backup a SAN/iSCSI PVC
oc new-app --template=backup-block \
-p PVC_NAME=pvc-to-backup \
-p PVC_BCK=pvc-for-backuper \
-p NODE=node1.mydomain.com
#### ex How to backup a NAS/NFS PVC
oc new-app --template=backup-shared \
-p PVC_NAME=pvc-to-backup \
-p PVC_BCK=pvc-for-backuper
Restoring
After step 3 binds the new SCC to the backup Service Account, , you can restore data when you want. You just need to detach your current PVC (the backup source) and attach the PVC with the data you backed up (the backup target):
oc set volumes dc/myapp --add --overwrite --name=mydata \
--type=persistentVolumeClaim --claim-name=pvc-for-backuper
This won't remove the original backup source PVC, so with a command likeoc rollback dc/myapp, you can switch back to it.
Security concerns
If you’ve been reading closely, you may have noticed that this solution is suitable only in fairly controlled cluster environments, because it has some security caveats:
- The
BackupErpod needs extra capabilities likeSETUID,SETGIDandDAC_OVERRIDE(granted to the Service Account by the new SCC). - A normal cluster user could use the Service Account
pvc-backup-deployerfor their own apps, not just for theBackupErpod.
This is where Admission Webhooks come in handy. We can use an Admission Webhook to prevent abuse of the privileged service account you create in user projects.
Admission webhooks call webhook servers to either mutate pods upon creation --such as to inject labels-- or to validate specific aspects of the pod configuration during the admission process. They intercept requests to the master API prior to the persistence of a resource, but after the request is authenticated and authorized.
We are going to use one of the two types of Admission Webhooks, the Validating admission webhooks, that allow for the use of validating webhooks to enforce custom admission policies.
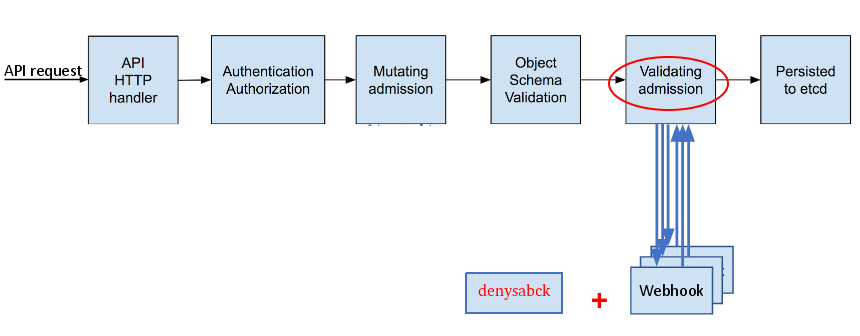
Our Validating Webhook denysabck intercepts requests to the API and discards any request that uses the Service Account pvc-backup-deployer for any container image other than our BackupEr image. You can see this procedure in the code.
Deploying our custom webhook
- Deploy the
Node.jscode: webhook-denysabck. There's a lot of possibilities:- Inside your cluster:
- Using your own
Node.jsimage. - OCP Source to image Node.js s2i.
- Outside
- Any cluster / server / etc that supports
Node.jsandHTTPS. - AWS Lambda
- GCP Cloud Functions
NOTE: The communication between your cluster/API and your Webhook must be secured and with trusteable SSL certificates. For an inside deployment I'd recommend you use a Serviceinstead of aRoute(the service must be secured with trusteable certs too). - Now, to configure/enable our custom webhook you can use the following yaml denysabck-webhook-cfg as a template. You only have to change the
webhooks.clientConfig.urlfor a valid one for an outside deployment orRouteinsteadServiceapproach. An example using theServiceapproach here.
Enable the ValidatingAdmissionWebhook admission controller
-
Edit
/etc/origin/master/master-config.yamland add the following:admissionConfig:
pluginConfig:[...]
ValidatingAdmissionWebhook:
configuration:
apiVersion: v1
disable: false
kind: DefaultAdmissionConfig[...]
- Restart API Server and controllers
-
Label the project where validation by our webhook should be in effect:
oc label namespace myproject “denysabck=enabled”
Check the Custom Admission Controllers section in the OpenShift documentation for more information.
WARNING: In OpenShift 3.9, Admission webhooks is a Technology Preview feature only.
Improvements
Some ideas / improvements:
- Use Role-Based Access to SCCs instead assigning the
ServiceAccountdirectly to an SCC (this retains cluster-wide scope and you could prefer to limit the scope to some projects, for example). We will see that in the following subheading. - Use
CronJobto automate backups. Some examples of automated maintenance tasks here. - Migrate this to an Operator.
Role-Based Access to SCCs
I didn’t mention this before, but I tried to keep it the installation steps as simple as possible, as this is a very interesting approach (GA since 3.11 and above). I decided to dedicate a couple of lines to this.
The advantage of this approach instead to using “traditional” SCC assignment (oc adm policy add-scc-to-) is that:
- You don’t need to change the SCC object (
groupsandusersfields) - Avoid losing all those assignments if you update the SCC
You only have to worry about to manage rolebindings.
- Create the ClusterRole
oc create -f https://raw.githubusercontent.com/josgonza-rh/pvc-backup/master/openshift/clusterrole_backuper.yaml
- Add
BackupErtemplates (first time / optional) to the platformoc create -f https://raw.githubusercontent.com/josgonza-rh/pvc-backup/master/openshift/temp_backup-block_3.11.yaml -n openshift
oc create -f https://raw.githubusercontent.com/josgonza-rh/pvc-backup/master/openshift/temp_backup-shared_3.11.yaml -n openshift
As the templates are responsible for creating the ServiceAccount and assigning our custom ClusterRole to that ServiceAccount, you don’t need extra commands to start the backup process (this does not change from what we have seen before, in the Backup point).
Conclusion
We have been able to see during the reading of all the chapters how I faced the challenge to implement backup-restore / migration capabilities in an OpenShift cluster with my artisanal solution.
We’ve seen interesting things that come out-of-the-box with OpenShift, like the use of WebHooks and the Role-Based Access to SCCs, and how they can help you to implement cool and secured custom applications.
My solution is unsupported by Red Hat and it is not recommended for production use, but rather, is just to have a customizable solution in case the others doesn't fit you for any reason.
You can reach other interesting solutions, based in an operator approach, in the OperatorHub.io like the etcd, whose operator is responsible for installing, backing up and restoring an etcd cluster (between many other cool features).
{{cta('1ba92822-e866-48f0-8a92-ade9f0c3b6ca')}}
執筆者紹介
類似検索
急激に進化する AI の脅威に対応する防御作とは
自動化を超えて:AI 駆動型のセキュリティ脆弱性の急増に対して、人間による技術的な支援が必要な理由
Collaboration In Product Security | Compiler
Keeping Track Of Vulnerabilities With CVEs | Compiler
チャンネル別に見る

自動化
テクノロジー、チームおよび環境に関する IT 自動化の最新情報

AI (人工知能)
お客様が AI ワークロードをどこでも自由に実行することを可能にするプラットフォームについてのアップデート

オープン・ハイブリッドクラウド
ハイブリッドクラウドで柔軟に未来を築く方法をご確認ください。

セキュリティ
環境やテクノロジー全体に及ぶリスクを軽減する方法に関する最新情報

エッジコンピューティング
エッジでの運用を単純化するプラットフォームのアップデート

インフラストラクチャ
世界有数のエンタープライズ向け Linux プラットフォームの最新情報

アプリケーション
アプリケーションの最も困難な課題に対する Red Hat ソリューションの詳細
仮想化
オンプレミスまたは複数クラウドでのワークロードに対応するエンタープライズ仮想化の将来についてご覧ください