
This is a guest post by Ankur Desai, director of product at Robin.io.
After successfully deploying and running stateless applications, a number of developers are exploring the possibility of running stateful workloads, such as PostgreSQL, on OpenShift. If you are considering extending OpenShift for stateful workloads, this tutorial will help you experiment on your existing OpenShift environment by providing step-by-step instructions.
This tutorial will walk you through:
- How to deploy a PostgreSQL database on OpenShift using the ROBIN Operator
- Create a point-in-time snapshot of the PostgreSQL database
- Simulate a user and rollback to a stable state using the snapshot
- Clone the database for the purpose of collaboration
- Backup the database to the cloud using AWS S3 bucket
- Simulate data loss/corruption and use the backup to restore the database
Install the ROBIN Operator from OperatorHub
Before we deploy PostgreSQL on OpenShift, let’s first install the ROBIN operator from the OperatorHub and use the operator to install ROBIN Storage on your existing OpenShift environment. You can find the Red Hat certified ROBIN operator here. Use the “Install” button and follow the instructions to install the ROBIN operator. Once the operator is installed you can use the “ROBIN Cluster” Custom Resource Definition at the bottom of the webpage to create a ROBIN cluster.
ROBIN Storage is an application-aware container storage that offers advanced data management capabilities and runs natively on OpenShift. ROBIN Storage delivers bare-metal performance and enables you to protect (via snapshots and backups), encrypt, collaborate (via clones and git like push/pull workflows) and make portable (via Cloud-sync) stateful applications that are deployed using Helm Charts or Operators.
Create a PostgreSQL Database
After you have installed ROBIN, let’s install the PostgreSQL client as the first step, so that we can use Postgresql once deployed.
yum install -y https://download.postgresql.org/pub/repos/yum/10/redhat/rhel-7-x86_64/pgdg-redhat10-10-2.noarch.rpm
yum install -y postgresql10
Let’s confirm that OpenShift cluster is up and running.
oc get nodes
You should see an output similar to below, with the list of nodes and their status as “Ready.”
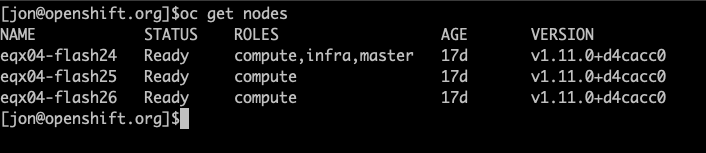
Let’s confirm that ROBIN is up and running. Run the following command to verify that ROBIN is ready.
oc get robincluster -n robinio

Let’s setup helm now. Robin has helper utilities to initialize helm.
robin k8s deploy-tiller-objects
robin k8s helm-setup
helm repo add stable https://kubernetes-charts.storage.googleapis.com
Let’s create a PostgreSQL database using Helm and ROBIN Storage. Before continuing, it’s important to note that the process shown, using Helm and Tiller, is provided as an example only. The supported method of using Helm charts with OpenShift is via the Helm operator.
Using the below Helm command, we will install a PostgreSQL instance. When we installed the ROBIN operator and created a “ROBIN cluster” custom resource definition, we created and registered a StorageClass named “robin-0-3” with OpenShift. We can now use this StorageClass to create PersistentVolumes and PersistentVolumeClaims for the pods in OpenShift. Using this StorageClass allows us to access the data management capabilities (such as snapshot, clone, backup) provided by ROBIN Storage. For our PostgreSQL database, we will set the StorageClass to robin-0-3 to benefit from data management capabilities ROBIN Storage brings.
helm install stable/postgresql --name movies --tls --set persistence.storageClass=robin-0-3 --namespace default --tiller-namespace default
Run the following command to verify our database called “movies” is deployed and all relevant Kubernetes resources are ready.
helm list -c movies --tls --tiller-namespace default
You should be able to see an output showing the status of your Postgres database.

You would also want to make sure Postgres database services are running before proceeding further. Run the following command to verify the services are running.
oc get service | grep movies

Now that we know the PostgreSQL services are up and running, let’s get Service IP address of our database.
export IP_ADDRESS=$(oc get service movies-postgresql -o jsonpath={.spec.clusterIP})
Let’s get the password of our PostgreSQL database from Kubernetes Secret
export POSTGRES_PASSWORD=$(oc get secret --namespace default movies-postgresql -o jsonpath="{.data.postgresql-password}" | base64 --decode)
Add data to the PostgreSQL database
We'll use movie data to load data into our Postgres database.
Let’s create a database “testdb” and connect to “testdb”.
-
PGPASSWORD="$POSTGRES_PASSWORD" psql -h $IP_ADDRESS -U postgres -c "CREATE DATABASE testdb;"
For the purpose of this tutorial, let’s create a table named “movies”.
PGPASSWORD="$POSTGRES_PASSWORD" psql -h $IP_ADDRESS -U postgres -d testdb -c "CREATE TABLE movies (movieid TEXT, year INT, title TEXT, genre TEXT);"
We need some sample data to perform operations on. Let’s add 9 movies to the “movies” table.
PGPASSWORD="$POSTGRES_PASSWORD" psql -h $IP_ADDRESS -U postgres -d testdb -c “INSERT INTO movies (movieid, year, title, genre) VALUES
('tt0360556', 2018, 'Fahrenheit 451', 'Drama'),
('tt0365545', 2018, 'Nappily Ever After', 'Comedy'),
('tt0427543', 2018, 'A Million Little Pieces','Drama'),
('tt0432010', 2018, 'The Queen of Sheba Meets the Atom Man', 'Comedy'),
('tt0825334', 2018, 'Caravaggio and My Mother the Pope', 'Comedy'),
('tt0859635', 2018, 'Super Troopers 2', 'Comedy'),
('tt0862930', 2018, 'Dukun', 'Horror'),
('tt0891581', 2018, 'RxCannabis: A Freedom Tale', 'Documentary'),
('tt0933876', 2018, 'June 9', 'Horror');”
Let’s verify data was added to the “movies” table by running the following command.
PGPASSWORD="$POSTGRES_PASSWORD" psql -h $IP_ADDRESS -U postgres -d testdb -c "SELECT * from movies;"
You should see an output with the “movies” table and the nine rows in it as follows:
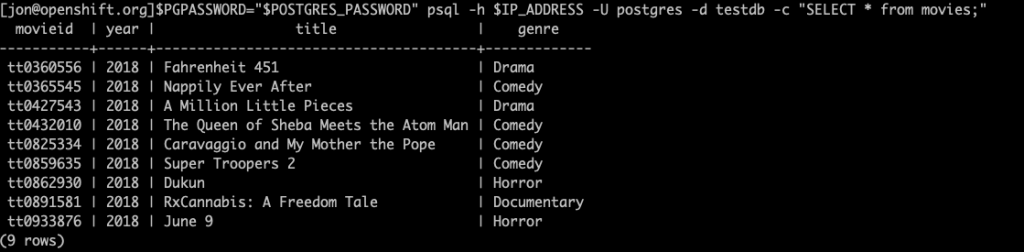
We now have a PostgreSQL database with a table and some sample data. Now, let’s take a look at the data management capabilities ROBIN brings, such as taking snapshots, making clones, and creating backups.
Register the PostgreSQL Helm release as an application
To benefit from the data management capabilities, we'll register our PostgreSQL database with ROBIN. Doing so will let ROBIN map and track all resources associated with the Helm release for this PostgreSQL database.
Let’s first get the ‘robin’ client utility and set it up to work with this OpenShift cluster.
To get the link to download ROBIN client do:
oc describe robinclusters -n robinio
You should see an output similar to below:
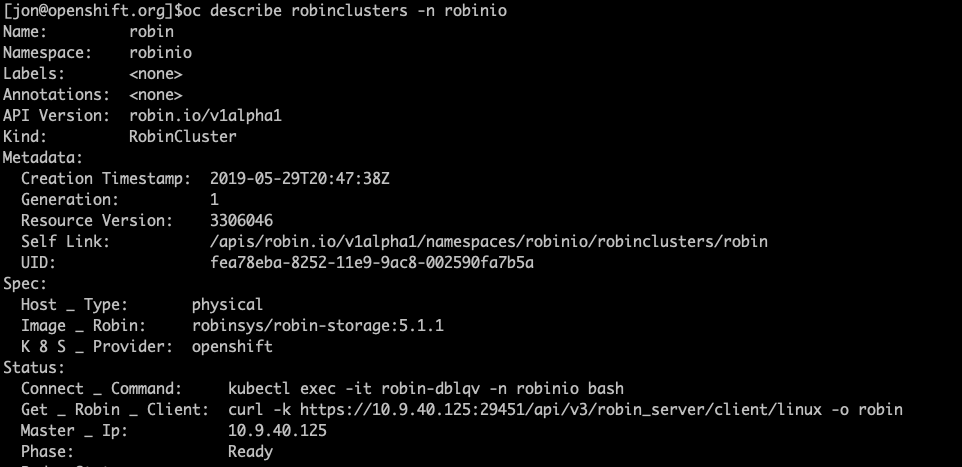
Find the field ‘Get _ Robin _ Client’ and run the corresponding command to get the ROBIN client.
curl -k https://10.9.40.125:29451/api/v3/robin_server/client/linux -o robin
In the same output above notice the field ‘Master _ Ip’ and use it to setup your ROBIN client to work with your openshift cluster, by running the following command.
export ROBIN_SERVER=10.9.40.125
Now you can register the Helm release as an application with ROBIN. Doing so will let ROBIN map and track all resources associated with the Helm release for this PostgreSQL database. To register the Helm release as an application, run the following command:
robin app register movies --app helm/movies

Let’s verify ROBIN is now tracking our PostgreSQL Helm release as a single entity (app).
robin app status --app movies
You should see an output similar to this:

We have successfully registered our Helm release as an app called “movies”.
Snapshot and Rollback a PostgreSQL Database on OpenShift
If you make a mistake, such as unintentionally deleting important data, you may be able to undo it by restoring a snapshot. Snapshots allow you to restore the state of your application to a point-in-time.
ROBIN lets you snapshot not just the storage volumes (PVCs) but the entire database application including all its resources such as Pods, StatefulSets, PVCs, Services, ConfigMaps etc. with a single command. To create a snapshot, run the following command.
robin snapshot create snap9movies movies --desc "contains 9 movies" --wait
Let’s verify we have successfully created the snapshot.
robin snapshot list --app movies
You should see an output similar to this:

We now have a snapshot of our entire database with information of all 9 movies.
Rolling back to a point-in-time using snapshot
We have 9 rows in our “movies” table. To test the snapshot and rollback functionality, let’s simulate a user error by deleting a movie from the “movies” table.
PGPASSWORD="$POSTGRES_PASSWORD" psql -h $IP_ADDRESS -U postgres -d testdb -c "DELETE from movies where title = 'June 9';"
Let’s verify the movie titled “June 9” has been deleted.
PGPASSWORD="$POSTGRES_PASSWORD" psql -h $IP_ADDRESS -U postgres -d testdb -c "SELECT * from movies;"
You should see the row with the movie “June 9” does not exist in the table anymore.

Let’s run the following command to see the available snapshots:
robin app info movies
You should see an output similar to the following. Note the snapshot id, as we will use it in the next command.

Now, let’s rollback to the point where we had 9 movies, including “June 9”, using the snapshot id displayed above.
robin app rollback movies Your_Snapshot_ID --wait

To verify we have rolled back to 9 movies in the “movies” table, run the following command.
PGPASSWORD="$POSTGRES_PASSWORD" psql -h $IP_ADDRESS -U postgres -d testdb -c "SELECT * from movies;"
You should see an output similar to the following:
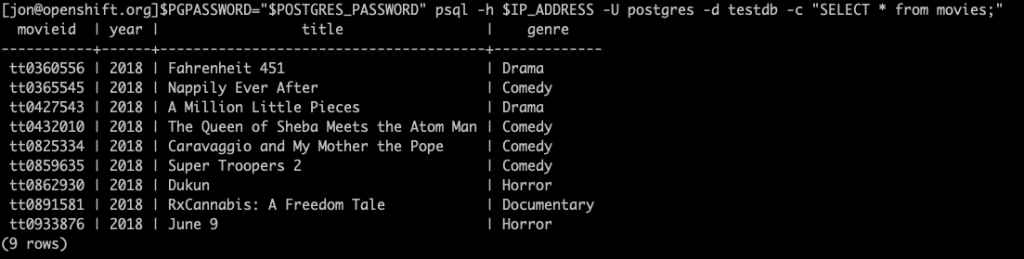
We have successfully rolled back to our original state with 9 movies!
Clone a PostgreSQL Database Running on OpenShift
ROBIN lets you clone not just the storage volumes (PVCs) but the entire database application including all its resources such as Pods, StatefulSets, PVCs, Services, ConfigMaps, etc. with a single command.
Application cloning improves the collaboration across Dev/Test/Ops teams. Teams can share applications and data quickly, reducing the procedural delays involved in re-creating environments. Each team can work on their clone without affecting other teams. Clones are useful when you want to run a report on a database without affecting the source database application, or for performing UAT tests or for validating patches before applying them to the production database, etc.
ROBIN clones are ready-to-use "thin copies" of the entire app/database, not just storage volumes. Thin-copy means that data from the snapshot is NOT physically copied, therefore clones can be made very quickly. ROBIN clones are fully-writable and any modifications made to the clone are not visible to the source app/database.
To create a clone from the existing snapshot created above, run the following command. Use the snapshot id we retrieved above.
robin clone create movies-clone <b>Your_Snapshot_ID</b><span> --wait</span>

Let’s verify ROBIN has cloned all relevant Kubernetes resources.
oc get all | grep "movies-clone"
You should see an output similar to below.
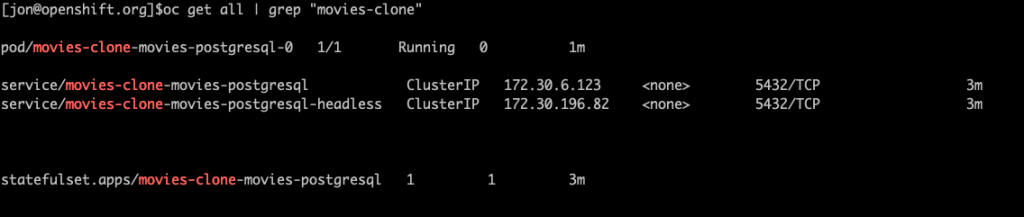
Notice that ROBIN automatically clones the required Kubernetes resources, not just storage volumes (PVCs), that are required to stand up a fully-functional clone of our database. After the clone is complete, the cloned database is ready for use.
Get Service IP address of our postgresql database clone, and note the IP address.
export IP_ADDRESS=$(oc get service movies-clone-movies-postgresql -o jsonpath={.spec.clusterIP})
Get Password of our postgresql database clone from Kubernetes Secret
export POSTGRES_PASSWORD=$(oc get secret movies-clone-movies-postgresql -o jsonpath="{.data.postgresql-password}" | base64 --decode;)
To verify we have successfully created a clone of our PostgreSQL database, run the following command.
PGPASSWORD="$POSTGRES_PASSWORD" psql -h $IP_ADDRESS -U postgres -d testdb -c "SELECT * from movies;"
You should see an output similar to the following:
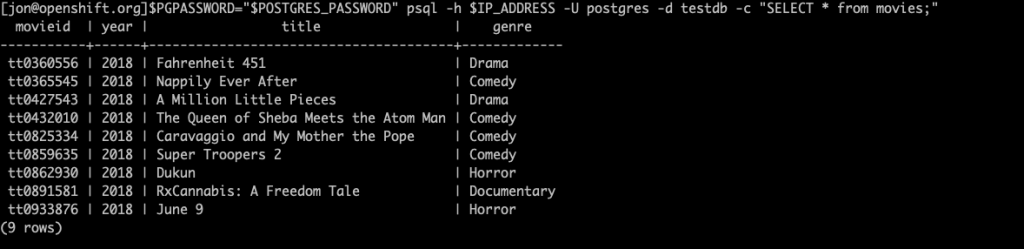
We have successfully created a clone of our original PostgreSQL database, and the cloned database also has a table called “movies” with 9 rows, just like the original.
Now, let’s make changes to the clone and verify the original database remains unaffected by changes to the clone. Let’s delete the movie called “Super Troopers 2”.
PGPASSWORD="$POSTGRES_PASSWORD" psql -h $IP_ADDRESS -U postgres -d testdb -c "DELETE from movies where title = 'Super Troopers 2';"
Let’s verify the movie has been deleted.
PGPASSWORD="$POSTGRES_PASSWORD" psql -h $IP_ADDRESS -U postgres -d testdb -c "SELECT * from movies;"
You should see an output similar to the following with 8 movies.
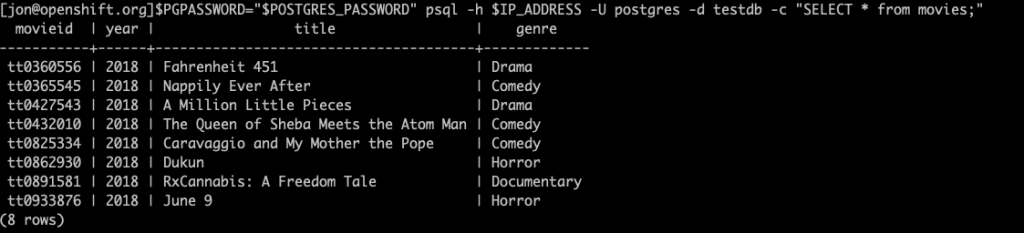
Now, let’s connect to our original PostgreSQL database and verify it is unaffected.
Get Service IP address of our postgresql database.
export IP_ADDRESS=$(oc get service movies-postgresql -o jsonpath={.spec.clusterIP})<span> </span>
Get Password of our original postgre database from Kubernetes Secret.
export POSTGRES_PASSWORD=$(oc get secret --namespace default movies-postgresql -o jsonpath="{.data.postgresql-password}" | base64 --decode;)
To verify that our PostgreSQL database is unaffected by changes to the clone, run the following command.
Let’s connect to “testdb” and check record :
-
PGPASSWORD="$POSTGRES_PASSWORD" psql -h $IP_ADDRESS -U postgres -d testdb -c "SELECT * from movies;"
You should see an output similar to the following, with all 9 movies present:
This means we can work on the original PostgreSQL database and the cloned database simultaneously without affecting each other. This is valuable for collaboration across teams where each team needs to perform unique set of operations.
To see a list of all clones created by ROBIN run the following command:
robin app list
Now let’s delete the clone. Clone is just any other ROBIN app so it can be deleted using ‘robin app delete’ command.
robin app delete movies-clone --wait

Backup a PostgreSQL Database from OpenShift to AWS S3
ROBIN elevates the experience from backing up just storage volumes (PVCs) to backing up entire applications/databases, including their metadata, configuration, and data.
A backup is a full copy of the application snapshot that resides on completely different storage media than the application’s data. Therefore, backups are useful to restore an entire application from an external storage media in the event of catastrophic failures, such as disk errors, server failures, or entire data centers going offline, etc. (This is assuming your backup doesn't reside in the data center that is offline, of course.)
Let's now backup our database to an external secondary storage repository (repo). Snapshots (metadata + configuration + data) are backed up into the repo.
ROBIN enables you to back up your Kubernetes applications to AWS S3 or Google GCS ( Google Cloud Storage). In this demo we will use AWS S3 to create the backup.
Before we proceed, we need to create an S3 bucket and get access parameters for it. Follow the documentation here.
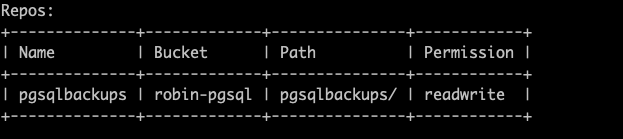
Let's first register an AWS repo with ROBIN:
robin repo register pgsqlbackups s3://robin-pgsql/pgsqlbackups awstier.json readwrite --wait

Let's confirm that our secondary storage repository is successfully registered:
robin repo list

You should see an output similar to the following :
Let's attach this repo to our app so that we can backup its snapshots there:
robin repo attach pgsqlbackups movies --wait
Let's confirm that our secondary storage repository is successfully attached to app:
robin app info movies
You should see an output similar to the following :
Let's backup up our snapshot to the registered secondary storage repository:
robin backup create bkp-of-my-movies <b>Your_Snapshot_ID</b> pgsqlbackups --wait
Let's confirm that the snapshot has been backed up in S3:
robin app info movies
You should see an output similar to the following :

Let's also confirm that backup has been copied to remote S3 repo:
robin repo contents pgsqlbackups
You should see an output similar to the following :

The snapshot has now been backed up into our AWS S3 bucket.
Now since we have backed-up our application snapshot to cloud, let’s delete that snapshot locally.
robin snapshot delete Your_Snapshot_ID --wait

Now let’s simulate a data loss situation by deleting all data from the “movies” table.
$PGPASSWORD="$POSTGRES_PASSWORD" psql -h $IP_ADDRESS -U postgres -d testdb -c "DELETE from movies;"
Let’s verify all data is lost.
$PGPASSWORD="$POSTGRES_PASSWORD" psql -h $IP_ADDRESS -U postgres -d testdb -c "SELECT * from movies;"

We will now use our backed-up snapshot on S3 to restore data we just lost.
Now let’s restore snapshot from the backup in cloud and rollback our application to that snapshot.
robin snapshot pull movies <b>Your_Backup_ID</b> --wait
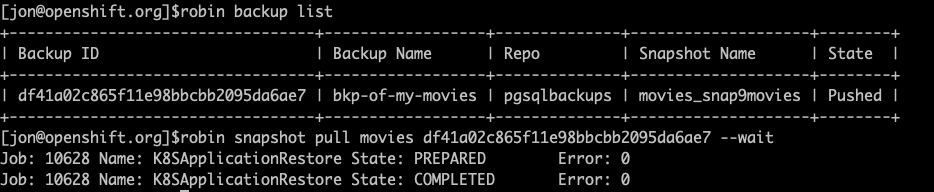
Remember, we had deleted the local snapshot of our data. Let’s verify the above command has pulled the snapshot stored in the cloud. Run the following command:
robin snapshot list --app movies

Now we can rollback to the snapshot to get our data back and restore the desired state.
robin app rollback <b>Your_Snapshot_ID</b><span> movies --wait</span>
Let’s verify all 9 rows are restored to the “movies” table by running the following command:
-
PGPASSWORD="$POSTGRES_PASSWORD" psql -h $IP_ADDRESS -U postgres -d testdb -c "SELECT * from movies;"
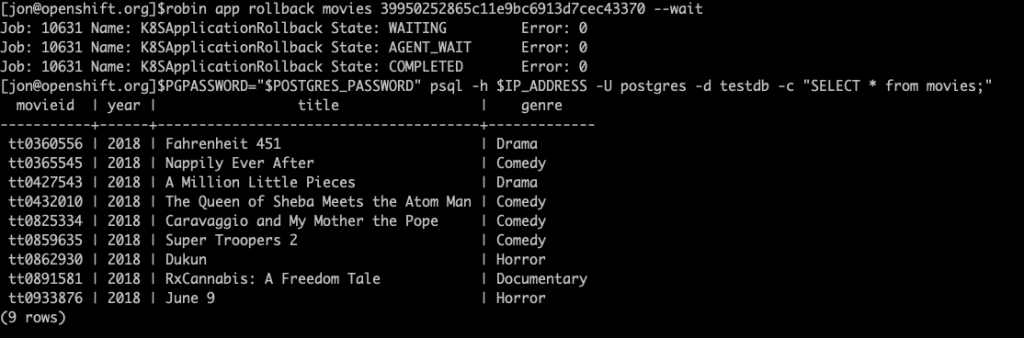
As you can see, we can restore the database to a desired state in the event of data corruption. We simply pull the backup from the cloud and use it to restore the database.
Running databases on OpenShift can improve developer productivity, reduce infrastructure cost, and provide multi-cloud portability. To learn more about using ROBIN Storage on OpenShift, visit the ROBIN Storage for OpenShift solution page.
執筆者紹介
Red Hatter since 2018, technology historian and founder of The Museum of Art and Digital Entertainment. Two decades of journalism mixed with technology expertise, storytelling and oodles of computing experience from inception to ewaste recycling. I have taught or had my work used in classes at USF, SFSU, AAU, UC Law Hastings and Harvard Law.
I have worked with the EFF, Stanford, MIT, and Archive.org to brief the US Copyright Office and change US copyright law. We won multiple exemptions to the DMCA, accepted and implemented by the Librarian of Congress. My writings have appeared in Wired, Bloomberg, Make Magazine, SD Times, The Austin American Statesman, The Atlanta Journal Constitution and many other outlets.
I have been written about by the Wall Street Journal, The Washington Post, Wired and The Atlantic. I have been called "The Gertrude Stein of Video Games," an honor I accept, as I live less than a mile from her childhood home in Oakland, CA. I was project lead on the first successful institutional preservation and rebooting of the first massively multiplayer game, Habitat, for the C64, from 1986: https://neohabitat.org . I've consulted and collaborated with the NY MOMA, the Oakland Museum of California, Cisco, Semtech, Twilio, Game Developers Conference, NGNX, the Anti-Defamation League, the Library of Congress and the Oakland Public Library System on projects, contracts, and exhibitions.
類似検索
エージェント型のパラドックスとハイブリッド AI の事例
過去を管理するのをやめて、IT の未来を構築しましょう
The Containers_Derby | Command Line Heroes
Crack the Cloud_Open | Command Line Heroes
チャンネル別に見る

自動化
テクノロジー、チームおよび環境に関する IT 自動化の最新情報

AI (人工知能)
お客様が AI ワークロードをどこでも自由に実行することを可能にするプラットフォームについてのアップデート

オープン・ハイブリッドクラウド
ハイブリッドクラウドで柔軟に未来を築く方法をご確認ください。

セキュリティ
環境やテクノロジー全体に及ぶリスクを軽減する方法に関する最新情報

エッジコンピューティング
エッジでの運用を単純化するプラットフォームのアップデート

インフラストラクチャ
世界有数のエンタープライズ向け Linux プラットフォームの最新情報

アプリケーション
アプリケーションの最も困難な課題に対する Red Hat ソリューションの詳細
仮想化
オンプレミスまたは複数クラウドでのワークロードに対応するエンタープライズ仮想化の将来についてご覧ください