
In today’s Storage Tutorial, Brian chats with Red Hat’s Paul Cuzner of the storage business unit. Paul has been focused on finding new ideas and strategies where Red Hat Storage can make a difference for customers and, most recently, has spent time working with Splunk. Watch the video below to find out just how Paul and Red Hat work with customers to make the most of Splunk and their storage, but we’ve broken down one salient bit for you right here…keep reading!
Understanding Splunk data flows
Data arriving within a Splunk indexer, as it’s being parsed, is placed into a structure named a bucket – a directory in a file structure. This bucket is considered “hot” because its index is being actively built, or files are constantly being added or removed from it. When it reaches a certain size, or age, it moves to “warm” storage, meaning the index is built and closed, so no further information is added and it becomes a point of record.
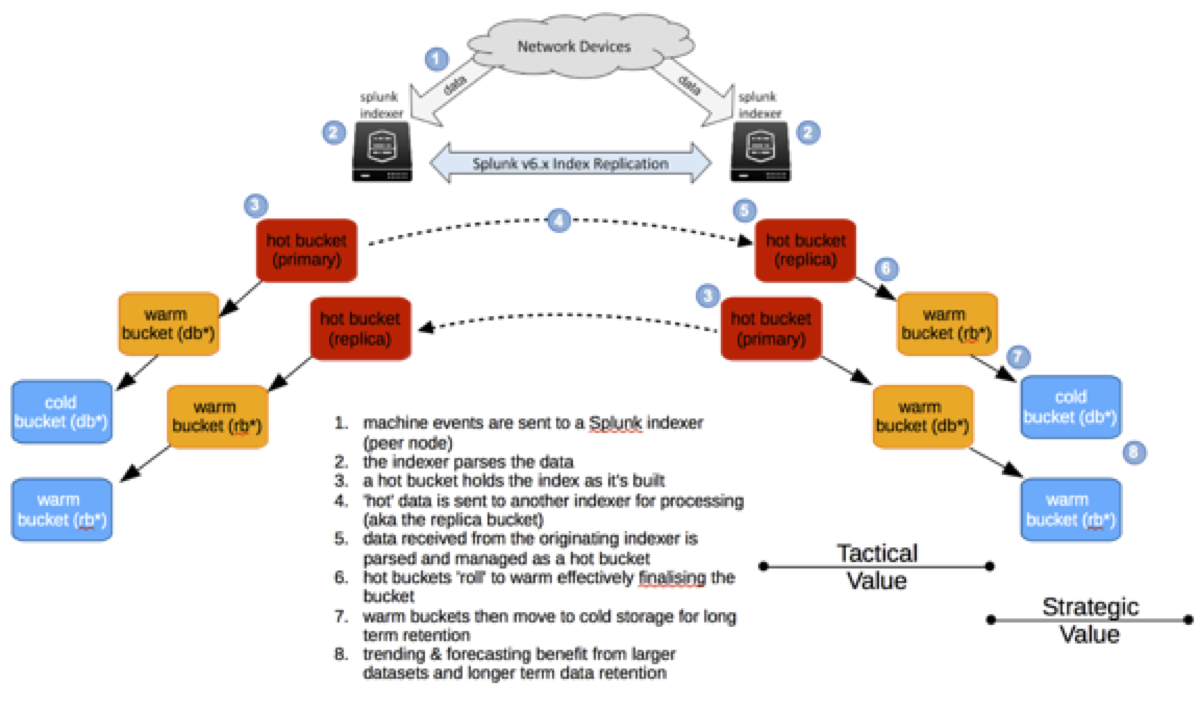 The Splunk data migration flow, illustrated!
The Splunk data migration flow, illustrated!
Hot and warm buckets, because they are considered to be in use or readily available, are typically placed on very fast storage – 10,000 or 15,000 RPM hard disks or flash storage, for example.
Eventually warm buckets are rolled into “cold” buckets. These are also not written to and are available for search. This storage, because it isn’t accessed quite as often, is typically placed on slower storage with very high capacity…and this is where customers struggle to choose a platform.
Be sure to check out the video, next:
執筆者紹介
類似検索
vi エディター入門
自動化を超えて:AI 駆動型のセキュリティ脆弱性の急増に対して、人間による技術的な支援が必要な理由
Untangling Networks | Compiler
Technically Speaking | Defining sovereign AI with open source
チャンネル別に見る

自動化
テクノロジー、チームおよび環境に関する IT 自動化の最新情報

AI (人工知能)
お客様が AI ワークロードをどこでも自由に実行することを可能にするプラットフォームについてのアップデート

オープン・ハイブリッドクラウド
ハイブリッドクラウドで柔軟に未来を築く方法をご確認ください。

セキュリティ
環境やテクノロジー全体に及ぶリスクを軽減する方法に関する最新情報

エッジコンピューティング
エッジでの運用を単純化するプラットフォームのアップデート

インフラストラクチャ
世界有数のエンタープライズ向け Linux プラットフォームの最新情報

アプリケーション
アプリケーションの最も困難な課題に対する Red Hat ソリューションの詳細
仮想化
オンプレミスまたは複数クラウドでのワークロードに対応するエンタープライズ仮想化の将来についてご覧ください