
プライベートクラウドが、まるでルール無用の食べ放題ビュッフェのように感じられることはありませんか?これが確かに価値を提供していることは分かっていますが、いざ請求書が届くと、誰が何を消費しているのかを把握することはほぼ不可能です。
今日の動的なクラウド環境では、特に独自のクラウド・インフラストラクチャを運用している企業にとって、コストを内部ユーザーに適切に割り当て可能にすることがますます重要になっています。コストを部門間で公平に分配したり、チームにワークロードの適正化を促したりするには、アカウンタビリティを確立する必要があり、その第一歩となるのは、可視性を高めることです。
Red Hat OpenStack Services on OpenShift 18 の機能リリース 5 (FR5) では、この課題を解決するための重要な要素、つまりテナントの測定された使用状況に基づいて評価する機能を提供します。
FR5 では、 OpenStack ネイティブの評価サービスである CloudKitty を一般に提供可能にします。このサービスは、生の技術指標と財務業務との間のギャップを埋めます。
CloudKitty が重要な理由
CloudKitty は、サーバーの使用状況に関するデータを、部門予算の策定に役立つ情報に変換する変換レイヤーを提供します。CloudKitty はメーターの検針員のようなものだと考えてください。これは、収集されたメトリクスと、 FinOps または課金ソリューションの間に位置します。このサービスは、仮想マシン (VM) の稼働時間やストレージの消費量といった生の技術データを取り込み、設定された特定の評価ルールを適用してレポートを生成します。これにより、 2 つの主要な目標を達成できます。
- 透明性の高いコスト回収:テナントごとのリソース使用状況が、項目別に明確に表示されるようになりました。これにより、不透明な評価で社内ユーザーを困惑させることなく、運用コストを正確に回収できます。
- 信頼と最適化:テナントは、自らの消費量 (プロジェクト、フレーバー、メトリクス別) がコストにどのように影響するかを確認することで、古いデータのアーカイブや VM 使用状況の最適化など、情報に基づいた意思決定を行うことができます。
CloudKitty は純粋に可視化および評価エンジンとしてのみ機能し、テナントが特定のコストしきい値を超えた場合でも、自発的に予算制限を適用したり、リソース (Nova インスタンスなど) の作成をブロックしたりすることはありません。
CloudKitty の仕組み
CloudKitty は完全な課金ソリューションではありませんが、使用量とコストをつなぐ重要な架け橋となります。ワークフローを簡単に説明すると、次のようになります。
Rating Rules を設定 → Metrics を収集 → Rating Reports を生成
ルールの設定
架空のテナントリストから、サンプルのテナントである「データ省」を例にとって見てみましょう。同省はこれまで、分析ワークロード用に大規模な VM を起動し、計算が完了した後もそれらを長時間稼働させたままにしていました。
透明性の高いコスト回収を実現するには、同省のコンピュートフットプリントを追跡する必要があります。これは、 ceilometer_cpu メトリクスを追跡することによって行います。この特定のメトリクスを使用することで、フレーバーベースの稼働時間を提供できます。つまり、 VM インスタンスが稼働している期間ごとに、 CloudKitty はそのサイズに基づいて異なるレートを計算できます。
ステップ 1:サービスの作成
まず、メトリクス用にトップレベルのコンテナを作成する必要があります。サービス名は、メトリクス名、または metrics.yaml で定義されている alt_name と完全に一致している必要があります。(このファイルについては、後ほど詳しく説明します。)
openstack rating hashmap service create ceilometer_cpu
+----------+--------------------------------------+
| Name | Service ID |
+----------+--------------------------------------+
| ceilometer_cpu | <uuid> |
+----------+--------------------------------------+このサービス ID (UUID) を保存しておいてください。次のコマンドで必要になります。
ceilometer_cpu という名前のサービスを作成することで、コレクターから送られてくるすべての CPUデータポイントが、この新しい評価ルールに直接ルーティングされるようになります。
ステップ 2:グループの作成 (任意)
データ省のコンピュート料金が、ストレージやネットワークの請求と混ざり合ってしまうのを防ぎたいと考えています。グループを使用することで、関連するマッピングを整理し、計算を分離できます。
openstack rating hashmap group create cpu_ratingこれらのマッピングをグループ化することで、異なる請求シナリオを区別できます。同じグループ内の複数のマッピングが一致する場合、CloudKitty は最もコストの高いもののみを適用します。
ステップ 3:マッピングの作成
マッピングはコストを定義するルールです。まず、項目ごとに固定費を請求することで、データ省のベースラインを設定します。直前の手順で返された UUID を <service_id> と <group_id> を置き換えることで、この新しいルールを ceilometer_cpu サービスおよび cpu_rating グループに直接リンクできます。
openstack rating hashmap mapping create 0.02 \
-s <service_id> \
-g <group_id> \
-t flatこのシナリオでは、0.02 は収集期間ごと (デフォルトでは 1 時間ごと) の 0.02 ユニットを意味します。各 CPU インスタンスには、使用量に関係なく一律 0.02 ユニットの料金が発生します。
ステップ 4:フィールドベースの評価 (秘密兵器)
データ省は、リソースを大量に消費する大規模なデータベースノードと並行して、小規模な Web サーバーを稼働しています。すべてに対して一律の料金を課金することは、公平とは言えません。同省が使用する特定の VM フレーバーごとに、異なる料金を課金したいと考えています。
まず、メタデータキーを参照するフィールドを作成します。
openstack rating hashmap field create <service_id> flavor_id次に、そのフレーバー値に対する特定のマッピングを作成します。
openstack rating hashmap mapping create 0.05 \
--field-id <field_id> \
--value <flavor_uuid> \
-t flat環境内で利用可能なすべてのフレーバーについて、このマッピングの作成を繰り返します。特定の VM サイズが稼働しているときに、評価サービスが計算すべきレートを認識できるように、フレーバーごとに新しいルールを作成します。
結果:連携の仕組み
月末になり、データ省から使用状況の提示を求められた際、CloudKitty が上記で構築したルールをどのように処理するかを以下に示します。
ceilometer_cpu (metric)
└─> Service: ceilometer_cpu
└─> Field: flavor_id (optional)
└─> Mapping: m1.tiny = 0.01, m1.large = 0.05
└─> Mapping (direct):0.02 flat測定可能であれば、評価も可能に
主な例としてデータ省の CPU 使用量 (ceilometer_cpu) を使用しましたが、計算は全体の一部にすぎません。Red Hat OpenStack Services on OpenShift における CloudKitty の真の価値は、Prometheus との統合にあります。
すでに収集されているメトリクスは評価に使用できることに留意してください。つまり、上記で説明したのとまったく同じ手順を使用して、残りのテナントのフットプリントについての評価ルールを簡単に作成できます。たとえば、以下に対するコストマッピングを作成できます。
- ブロックストレージ:
ceilometer_disk_device_capacityを使用した GB の月間容量の追跡 - ネットワーキング:
ceilometer_ip_floatingを使用した、割り当てた公開アドレスの課金 - 送信帯域幅:
ceilometer_network_outgoing_bytesを使用した VM からの総送信トラフィックの評価
CloudKitty が Prometheus からこの範囲のデータを取得すると、プロセッサーがカスタマイズされた評価ルールを適用し、評価済みのメトリクスをストレージのバックエンドに直接プッシュします。これは、生の技術テレメトリーと FinOps レポートをつなぐ、究極の自動化された架け橋として機能します。
評価レポートの生成:真実の瞬間
ルールを作成し、 Prometheus からメトリクスを収集したら、最後のステップとして評価済みデータを抽出します。
ここで、CloudKitty は請求システムではない点に留意してください。これは、見栄えの良い PDF の請求書を生成するためのものではありません。むしろ、 REST API や OpenStack クライアントを介して、クリーンで解析可能な JSON データを提供する堅牢なデータエンジンとして機能します。これにより、評価済みデータを企業の既存の FinOps やショーバック、課金ミドルウェアに直接取り込むことが容易になります。
テナントのビュー:データ省が利用料金を確認します
CloudKitty には、テナント対応のアクセス制御機能が組み込まれています。データ省が現在の使用状況を確認したい場合、アクセスできるのは独自のプロジェクトのフットプリントのみです。他のテナントのデータを表示しようとしても、 API が自動的にブロックするか無視します。
同省は、月次サマリーを取得するために OpenStack クライアントを使用できます。
# Get summary for a specific month
openstack rating summary get --begin 2026-02-01 --end 2026-03-01管理者のビュー:全体を俯瞰する視点
データ省のアクセスは自らの使用状況に制限されていますが、クラウド管理者は容量を管理し、グローバルのチャージバックを円滑に行うために、環境全体を包括的に把握する必要があります。
管理者トークンを使用することで、オペレーターは完全な可視性を得ることができます。オペレーターは、このコマンドを拡張して、 --tenant-id <project_uuid> を使用して特定のテナントを絞り込むことができます。
openstack rating summary get \
--begin 2026-02-01 \
--end 2026-03-01 \
--tenant-id <project_uuid>または、FinOps チームが請求システムにエクスポートするために全体像を必要としている場合、管理者は --all-tenants フラグを使用して、クラウド全体の評価済みデータを一度に取得できます。
FinOps ソリューションへの直接接続
FinOps ミドルウェアがプログラムからこのデータを取得している場合、REST API を使用して、先ほど設定した特定のサービスタイプ(ceilometer_cpu など)ごとにグループ化された詳細な内訳をリクエストできます。
curl -X GET \
-H "X-Auth-Token: $TENANT_TOKEN" \
"http://localhost:8888/v1/report/summary?begin=2026-02-01T00:00:00&end=2026-03-01T00:00:00&groupby=res_type"結果として出力される JSON では、リソースタイプ、期間、計算された合計ユニット数が分かりやすく整理されます。
{
"summary": [
{
"tenant_id":"MoD-project-uuid",
"res_type": "ceilometer_cpu",
"begin":"2026-02-01T00:00:00",
"end":"2026-03-01T00:00:00",
"rate":125.50
}
]
}このように構造化および集約された JSON データを企業の広範な財務ソフトウェアに直接取り込むことで、生のインフラ消費量とコストの説明責任の間のループを効果的に閉じることができます。
内部の仕組み
オペレーターの視点から CloudKitty の実際の動作を確認したところで、次はエンジン内部の仕組みを詳しく見ていきましょう。アーキテクチャを理解することは、スケーラビリティの検討、問題のトラブルシューティング、および特定の設計上の決定が下された理由を理解するのに役立ちます。
アーキテクチャの概要
CloudKitty は、それぞれ異なる役割を持つ 2 つの独立したプロセスとして実行されます。
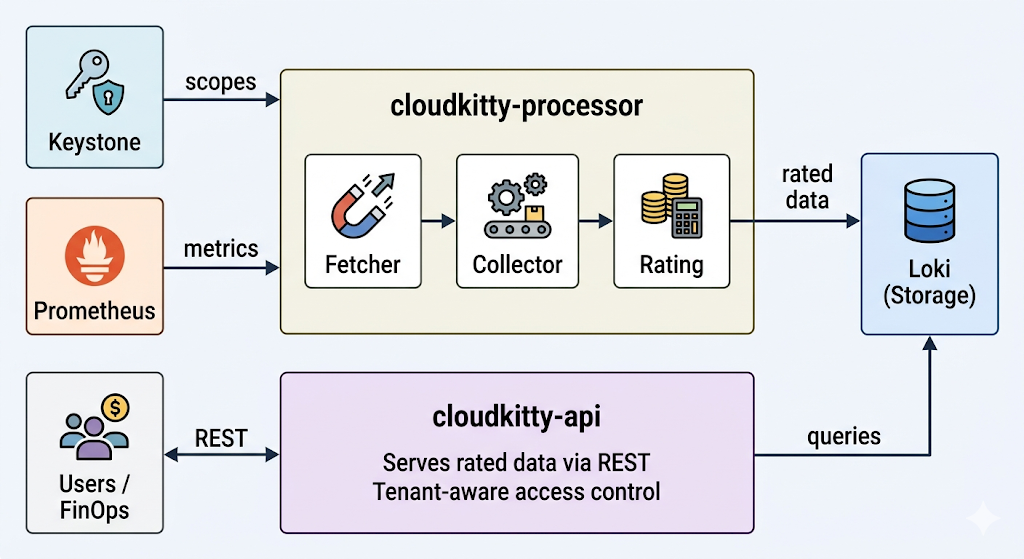
図 1 CloudKitty アーキテクチャ。 cloudkitty-processor は Keystone からスコープ、Prometheus からメトリクスを取得し、データを評価して Loki に保存します。 cloudkitty-api は Loki の評価済みデータを REST を介してユーザーや FinOps ツールに提供します。
cloudkitty-processor は評価エンジンです。cloudkitty-processor は、収集期間 (デフォルトでは 1 時間) ごとに、4 ステージのパイプラインを実行します。
- フェッチ:フェッチでは、Keystone に対し、評価が必要な OpenStack プロジェクト (スコープ) のリストを要求します。
- 収集:収集では、各スコープについて、
metrics.yamlで定義されている生のメトリクス値を Prometheus に問い合わせます。 - 評価:評価では、ハッシュマップルール (先ほど設定したサービス、フィールド、マッピング) を適用して、生の消費量を評価済みデータに変換します。
- 保存:保存では、結果として得られた評価済みデータフレームを Loki にプッシュして永続化します。
cloudkitty-api は REST フロントエンドです。これは、テナント、管理者、および外部の FinOps ツールからのすべてのクエリを処理します。ユーザーが評価の概要をリクエストすると、cloudkitty-api は Loki にクエリを実行して結果を返します。このプロセスはステートレスであり、水平方向にスケーリングして、より多くの同時リクエストを処理できます。
これら 2 つのプロセスは分離されているため、個別にスケールできます。たとえば、API レプリカを追加してクエリ負荷を処理したり、プロセッサーの並列処理を調整して、より多くのスコープを同時に評価したりできます。
Loki を使用する理由
Loki は主にログ集約システムとして知られているため、評価済みデータのストレージ・バックエンドとして Grafana Loki を使用することは、一般的ではない選択肢に見えるかもしれませんが、実際には非常に適しています。
- 時系列ネイティブ:評価済みデータは本質的には時間ベースのデータです。すなわち、収集期間ごとのスコープあたりのコストです。Loki は、構造化ストリームに対する効率的な時間範囲クエリの実行に特化して設計されています。
- スタックに組み込み済み:OpenStack Services on OpenShift のデプロイメントには、ログ管理用の LokiStack がすでに含まれています。CloudKitty は、オペレーターが管理するのと同じインフラストラクチャを再利用するため、追加のデータベースをデプロイしたりメンテナンスしたりする必要はありません。
- オブジェクトストレージが基盤:Loki はデータを S3 互換のオブジェクトストレージに永続化するため、運用上のフットプリントを小さく抑えることができます。追加の PVC やデータベース・クラスタを管理する必要はありません。
- 構造化メタデータ:今後は、 CloudKitty はインデックス付きメタデータ (テナント、メトリクスタイプ、フレーバー) を各ログエントリーに直接保存します。これにより、 JSON 全体を解析することなく、高速なフィルタリング・クエリが可能になり、大規模なクエリのパフォーマンスが大幅に向上します。
メトリクスの設定
収集段階の中心になるのは、metrics.yaml です。このファイルは CloudKitty に、どの Prometheus メトリクスを収集し、それらをどのように処理するかを指示します。以下は、出荷時の設定例からの抜粋です。
metrics:
ceilometer_cpu:
unit: instance
alt_name: instance
groupby:
- resource
- user
- project
- flavor_name
- flavor_id
mutate: NUMBOOL
extra_args:
aggregation_method: max
ceilometer_image_size:
unit: MiB
factor: 1/1048576
groupby:
- resource
- project
metadata:
- container_format
- disk_format
extra_args:
aggregation_method: max各エントリーは、 CloudKitty が特定の Prometheus メトリクスを収集して解釈する方法を制御します。
unit:評価レポートに表示される請求単位 (例:instance、GiB、B、ip)。alt_name:メトリクスの代替名。ハッシュマップサービスを作成する際は、 Prometheus メトリクス名 (ceilometer_cpu) またはalt_name(instance) のいずれかを使用できます。groupby:メトリクスを細分化するために使用される Prometheus ラベル。ceilometer_cpu の場合、 flavor_name と flavor_id でグループ化することで、先ほど設定したフレーバーベースの評価ルールが有効になります。mutate:生の値に適用される変換。 NUMBOOL はゼロ以外の任意の値を 1 に変換するため、「is this resource active? (このリソースはアクティブか?)」というセマンティクスに最適です。生の CPU カウンターの値は重要ではなく、インスタンスが稼働していることが重要となります。factor:単位変換の乗数。たとえば、ceilometer_image_sizeは 1/1048576 を使用して生のバイトを MiB に変換します。metadata:情報提供を目的として評価済みデータに引き継ぐための追加の Prometheus ラベル (例: イメージのcontainer_format、disk_format)。extra_args:バックエンド固有の引数。aggregation_method: maxは、 Prometheus コレクターに各収集期間内の最大値を使用するように指示します。
CloudKitty のコレクターは Prometheus と直接通信するため、利用可能な任意のメトリクスについての評価は簡単です。適切なラベルと単位を指定して metrics.yaml に新しいエントリーを追加すれば、 CloudKitty は次の処理サイクルからその収集と評価を開始します。
生データの検査
openstack rating summary get コマンドでは集計された合計値が得られますが、より詳細な情報を確認する必要がある場合もあります。評価ルールが正しく適用されているかの検証や、不足しているメトリクスのデバッグ、あるいは CloudKitty の保存内容の把握など、いずれの場合においても、 openstack rating dataframes get コマンドを使用することで、 Loki に格納されている個々の評価済みデータポイントを確認できます。
サマリーを月次の明細書、データフレームをレシート上の個々の明細項目として考えてみてください。
特定の時間内の生の評価済みデータフレームを取得するには、以下を実行します。
openstack rating dataframes get --begin 2026-03-01T00:00:00Z --end 2026-03-01T01:00:00Z出力の各行は、 1 つの収集期間における単一の評価済みデータポイントを表します。
| Begin | End | Metryc Type | Unit | Qty | Price | Group by | メタデータ |
|---|---|---|---|---|---|---|---|
2026-03-01T00:00:00Z |
2026-03-01T01:00:00Z |
ceilometer_cpu |
instance |
1 |
0.05 |
flavor_id=<uuid>, flavor_name=m1.large, project=<project_uuid>, resource=<vm_uuid> |
|
2026-03-01T00:00:00Z |
2026-03-01T01:00:00Z |
ceilometer_cpu |
instance |
1 |
0.01 |
flavor_id=<uuid>, flavor_name=m1.tiny, project=<project_uuid>, resource=<vm_uuid> |
各列が表す内容を詳しく説明します。
- Begin/End:このデータポイントが対象とする収集期間。デフォルトでは、 CloudKitty は 1 時間ごとにデータを収集するため、1 時間の枠が表示されます。
- Metric Type:
metrics.yamlのメトリクス名 (例:ceilometer_cpu、ceilometer_ip_floating) - Unit:
metrics.yamlで定義されている請求単位。 - Qty:mutate または factor の変換適用後の生の数量。
ceilometer_cpuを指定してNUMBOOLを使用する場合、インスタンスが実行中であれば 1 になります。 - Price:ハッシュマップルールを適用した後の評価済みの値。ここで、正しいマッピングが適用されたことを確認できます。
m1.largeを 0.05 に設定した場合、ここにその値が表示されます。 - Group By:
metrics.yamlのgroupbyフィールドのラベル値。ここで CloudKitty はデータを細分化し、特定のリソース、フレーバー、またはプロジェクトをドリルダウンして詳細に分析できるようにします。 - Metadata:
metrics.yamlのメタデータフィールドを介して引き継がれる追加のラベル。
これにより、オペレーターは生のメトリクスから最終的な価格までの完全なパスを追跡するためのツールを得ることができ、すべてのステップで CloudKitty の動作が透明化されるのでデバッグが可能になります。
コスト計算を開始する準備はできていますか?
社内の部門からの正確なコスト回収であっても、リソース消費状況の透明性の高い可視化であっても、CloudKitty はそれを実現するために必要な、信頼性の高い構造化されたデータを提供します。CloudKitty は、生の OpenStack テレメトリーとエンタープライズ FinOps ミドルウェアの間のギャップを埋める役割を果たします。
プライベートクラウドを、誰もが自由に使える無料のビュッフェのように扱う時代は終わりました。機能リリース 5 において、このネイティブで、かつ高度にカスタマイズ可能な機能を OpenStack Services on OpenShift のエコシステムに提供できることを大変嬉しく思います。勘に頼るのではなく、正確な評価の仕組みを導入しましょう。
今すぐ始める
ご使用の環境で CloudKitty を設定し、管理するための公式ドキュメントをご覧ください。
詳細はこちら
デモ動画をご覧いただき、管理者がフレーバーベースの評価ルールを簡単に設定し、月次明細の抽出を開始する方法をご確認ください。
この動画は、2 つの個別のターミナルセッションを編集してまとめたものです。バックグラウンドで実行されている生のコマンドをインタラクティブかつ詳細に確認したい場合は、こちらからノーカットの Asciinema 録画をご覧ください。
- https://asciinema.org/a/ofDLdVKxHfMAsaNM:CloudKitty のデプロとフレーバーベースの評価ルールの作成
- https://asciinema.org/a/P11NR7CEqfiewF4R:チャージバック・データフレームを検証し、月次サマリーを抽出します。
製品トライアル
Red Hat OpenShift Container Platform | 製品トライアル
執筆者紹介
Juan Larriba is a software engineer specializing in cloud infrastructure and OpenStack observability. He is a contributor to the OpenStack Kubernetes Operators ecosystem, where he works on the Telemetry Operator — a project that brings together metrics collection, alarming, and rating services like CloudKitty into cloud-native Kubernetes deployments. His work focuses on bridging traditional OpenStack telemetry components with modern container-native architectures, helping operators gain visibility and cost insight into their cloud workloads. Juan is passionate about open source collaboration and has contributed to projects spanning Ceilometer, Aodh, and CloudKitty, with a focus on making rating and chargeback capabilities more accessible in production OpenStack environments.
チャンネル別に見る

自動化
テクノロジー、チームおよび環境に関する IT 自動化の最新情報

AI (人工知能)
お客様が AI ワークロードをどこでも自由に実行することを可能にするプラットフォームについてのアップデート

オープン・ハイブリッドクラウド
ハイブリッドクラウドで柔軟に未来を築く方法をご確認ください。

セキュリティ
環境やテクノロジー全体に及ぶリスクを軽減する方法に関する最新情報

エッジコンピューティング
エッジでの運用を単純化するプラットフォームのアップデート

インフラストラクチャ
世界有数のエンタープライズ向け Linux プラットフォームの最新情報

アプリケーション
アプリケーションの最も困難な課題に対する Red Hat ソリューションの詳細
仮想化
オンプレミスまたは複数クラウドでのワークロードに対応するエンタープライズ仮想化の将来についてご覧ください