Back in time
Our journey so far has been all about control groups in Red Hat Enterprise Linux 7. Because Red Hat Enterprise Linux 7 leverages systemd and systemd itself has cgroups rolled into it, every Red Hat Enterprise Linux 7 user is benefiting from CPU share settings even if they never touch anything else.
If that first paragraph didn’t make sense because you’re just now starting this series, let me point you back to parts 1-4. They really do tell the story of how we got here. All of us will wait patiently and still be here when you get back from reading them.
The thing is, we’ve had the code for cgroup controllers in the Linux kernel from the day Red Hat launched Red Hat Enterprise Linux 6 in January of 2010...in computer years, that feels like a few centuries ago. Now, as time has marched on and more code has been written, these controllers have evolved and are more capable than they once were. But we still have some pretty cool things we can do with the original controllers in Red Hat Enterprise Linux 6.
Starting from scratch
Let’s take a use case that I’ve seen in my tenure as a TAM...nothing like solving real world problems, right? No actual names of companies or software products will be used, but this use case is based on multiple True Stories.

(Exciting, right? Also, because I didn’t want to *cough* borrow an image from the Internet, I made that all by myself. Guess it’s a good thing that I’m a fairly decent TAM, because I’d starve as a graphic designer.)
Nowadays, folks who work in IT seem to face more security challenges than ever. As we’ve connected all of our computing devices, phones, refrigerators, garden shears, you name it...security threats coming over networks are a fairly common occurrence. Now, one can attack this challenge from multiple fronts. Timely security patching? Yes please! Properly locking down systems using tools such as firewalls, SELinux and good identity management practices? Absolutely! Use a malware/virus scanner on your Linux system? Ummmm…
I’m not a huge fan of using scanner software on Linux machines. This class of software can be rather intrusive and sometimes cause more problems that it solves. That being said, we are sometimes mandated by Infosec departments or other management to run software so that systems comply with a security standard. That’s the whole “political reality” smacking us around, even when there may not be a good technical reason to deploy something. Work this career long enough and that will happen to you, I promise. Anyway, I’ll climb off this soap box now and get to our use case.
While Red Hat Enterprise Linux 7 is our current new and shiny operating system, whenever I take a straw poll of customers at Red Hat events, pretty much everyone in the room will raise their hands when asked “Who here is running Red Hat Enterprise Linux 6 today?” Not surprising, really, as one reason people choose Red Hat is that our software tends to be stable and long-lived.
So in the real world, I have a customer. Let’s call him Jerry.

By Carl Lender -, CC BY 2.0
Jerry is responsible for managing a group of Red Hat Enterprise Linux 6 servers. He’s happy with how they perform, man...doesn’t want to have any trouble or worries with them.
His security team informs him that he will need to start running a tool called “ScanIT” on these systems. It will periodically scan both memory and filesystems for known pieces of malware, so it needs full root access.
Jerry sighs a little bit, puts down his guitar and installs ScanIT on a development box to check out the impact. He quickly discovers a few things:
-
When doing the scan run, scanit (the name of the script that kicks off the process) grabs all the CPU that it can. This has a negative impact on the performance of the rest of the system. In one case, it’s running so hot that Jerry can’t even ssh into the box.
-
Every so often, the scanit process consumes a huge chunk of memory, which makes OOM Killer start taking out other important processes.
This won’t do.
Jerry picks his guitar back up (playing helps him to think) and starts to mull over how to solve the problem. Strumming the chorus from “Touch of Grey”, he realizes that these fancy cgroups that his Red Hat Enterprise Linux 7 buddy Axl is always talking about might help. Based on some Red Hat Enterprise Linux 6 docs that Axl linked for him, he’ll need to install libcgroup first.
Checking his development box, he sees that he doesn’t have the bits installed, so he handles that first.
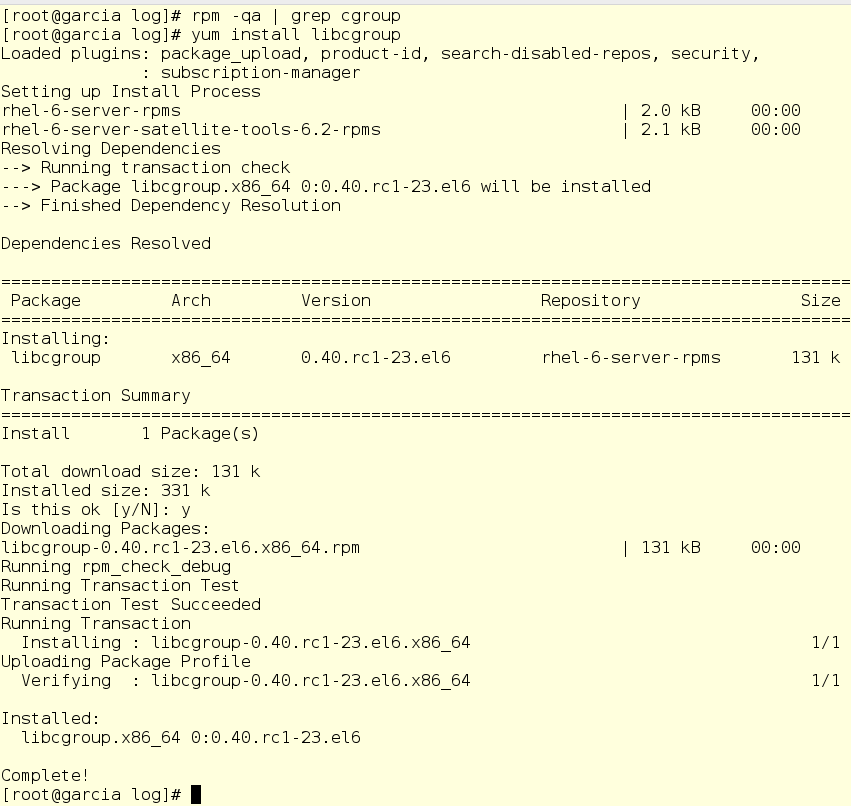
He also enables two important services that allow for persistent control groups:
-
cgconfig - this provides a fairly easy interface that allows the creation and manipulation of cgroup trees on the system. While Jerry could use very manual steps to mount and configure his cgroups, who has time for that?
-
cgred - this provides the cgroup “rules engine”. When a process starts up, this service checks to see if it matches certain rules and then places it into the appropriate cgroup if there is a positive match.

With those bits now installed and configured, Jerry is ready to make some decisions. After mulling it over some more he decides upon the following:
-
The scanit process and its children may consume no more than 20% of the available CPU time on the system. In fact, it may not consume more than 20% of a single core, even on a multiprocessor system. For this, Jerry will use the ability of cgroups to establish a CPU quota.
-
To protect the system from scanit using too much RAM, the process and its children may consume no more than 512M of system memory. If scanit violates this, Jerry wants the system to kill scanit, not any other processes.
Don’t tell me what to do, man!
There are two sets of configuration files Jerry is going to need to manipulate.
-
/etc/cgconfig.conf is generated automatically when libcgroup is installed.
-
/etc/cgrules.conf contains the ruleset that cgred uses to place processes into control groups on process start
Here is what the default cgconfig.conf looks like:
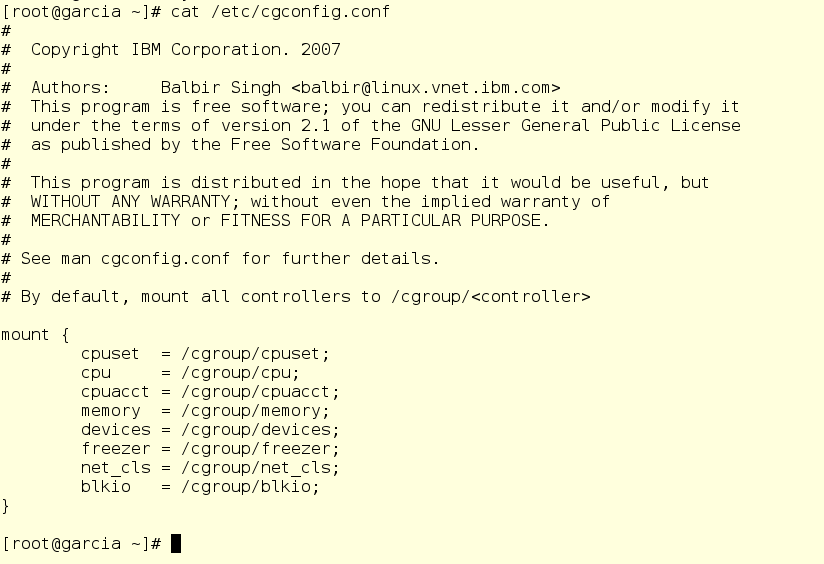
While Jerry could jump in and add new configuration stanzas, the best practice for making changes involves using a drop-in config file. Any files put into the directory /etc/cgconfig.d that end with .conf are parsed and added to the configuration. This makes it easy to have use-case specific config files that you can add and remove using your configuration management tool of choice, such as Ansible (wink wink nudge nudge).
Jerry creates a drop-in file to test capping just the CPU first.
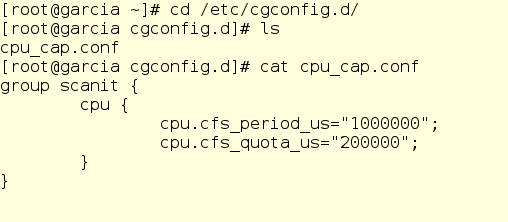
Let’s take a look and figure out how this works.
The “group” keyword sets the name of the new cgroup. In this case, we’re calling it “scanit”. Inside of the curly braces, we then identify what controllers the cgroup will be using. For this initial test, we’re starting with the CPU controller. “cpu.cfs_period_us” and “cpu.cfs_quota_us” are used to set the actual limits when we’re using the Completely Fair Scheduler. That’s the default kernel scheduler in Red Hat Enterprise Linux 6, so let’s see what the Red Hat Enterprise Linux 6 Resource Management Guide says about them:

So what Jerry has done here translates to “For processes in the scanit cgroup, every 1 second (1000000 microseconds) check the CPU allocation. If the CPU time used by ALL tasks running in this cgroup hits 200000 microseconds, throttle them to zero CPU usage” In other words, cap all processes in the scanit cgroup and their children to 20% of CPU.
Restarting the cgconfig server will re-read the configuration and if we check the filesystem, we will see scanit is now found in the cpu controller directory.

This is all well and good, but now we need a method to get scanit into that cgroup. That’s where crged comes in. The default looks like so:
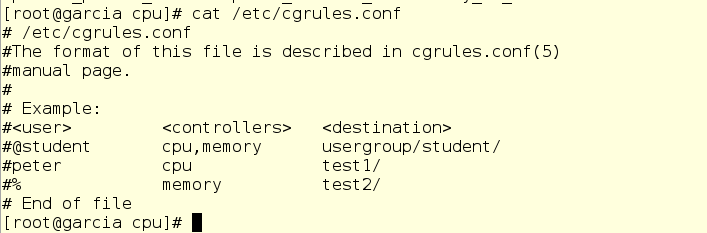
Using the file is fairly easy. We do need to edit cgrules.conf directly, as it does not support drop-ins. We identify a user or group that owns a process as well as a specific process name if we like, the controller impacted and the destination cgroup.
Now, we don’t actually have a real program named “scanit”. Rather, a script called scanit launches “stress” workers, which put artificial load on the system. Without the cgroup, here’s what that looks like:

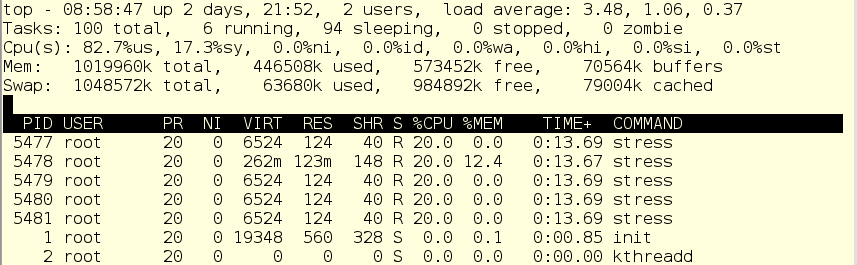
The CPU is running at capacity, mostly in user space with some system.
Jerry scratches his beard in thought. He fires up vi and, using only his index fingers to type, makes some changes and restarts the cgred daemon.
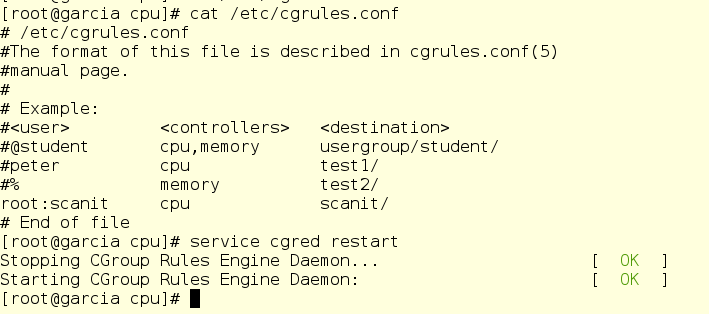
He starts a scanit run by hand….

And declares victory!
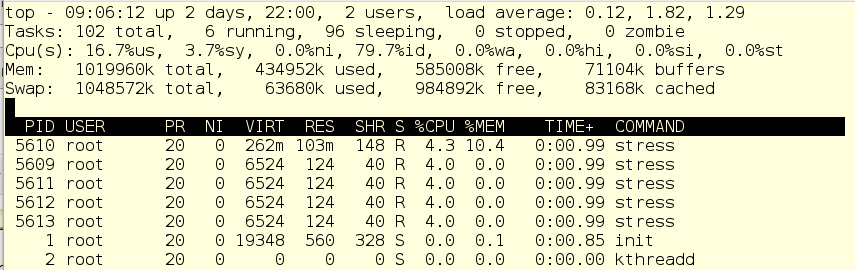
As we can see, the stress processes (children of scanit) are now using 20% of the CPU, mostly in user space but some in system. That pesky scan will no longer bog down the system.
Do you remember what was next?
Pleased with his progress, Jerry almost forgets about the memory issue. He remembers, while munching on his free-range peanut butter and gluten-free jelly sandwich (on extra-whole wheat bread, of course). Wiping his beard off, he fires up vi again and adds to his config file.
He adds two settings to the new memory stanza.
-
Memory.limit_in_bytes - this is the maximum amount of RAM that all processes in the scanit cgroup can use. This does not include swap space. Jerry sets it to 256 MB
-
Memory.memsw.limit_in_bytes - this is the maximum amount of RAM plus swap space that all processes in the scanit cgroup can use. Violating this will causes processes to be terminated by the OOM killer. While Jerry is fundamentally a pacifist, sometimes harsh calls need to be made. This is set to 512 MB
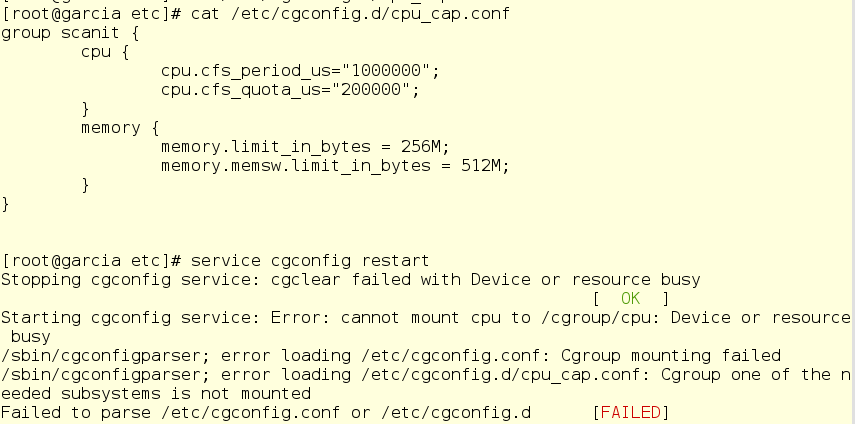
Oh no! What’s going on, man?
Jerry checks “top” and realizes that the scanit child processes are still running. Since that cgroup is actually in use, he can’t reload the service. He kills the child processes and then is able to restart the services.

Now for a quick modification to cgred.conf:
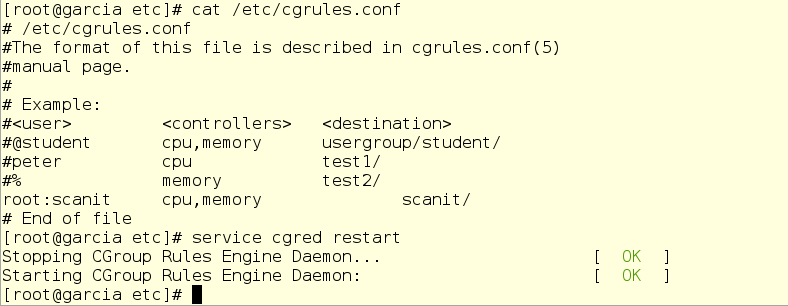
Jerry fires up a bunch of scanit jobs to test. Sure enough, the out of memory killer strikes!
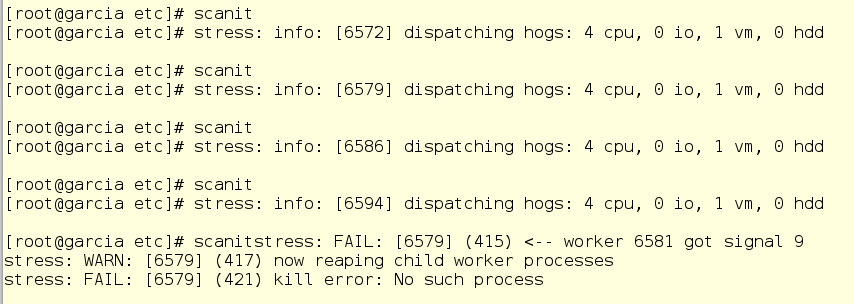
Jerry checks the system log and nods happily. Now scanit can no longer fill up memory willy-nilly.
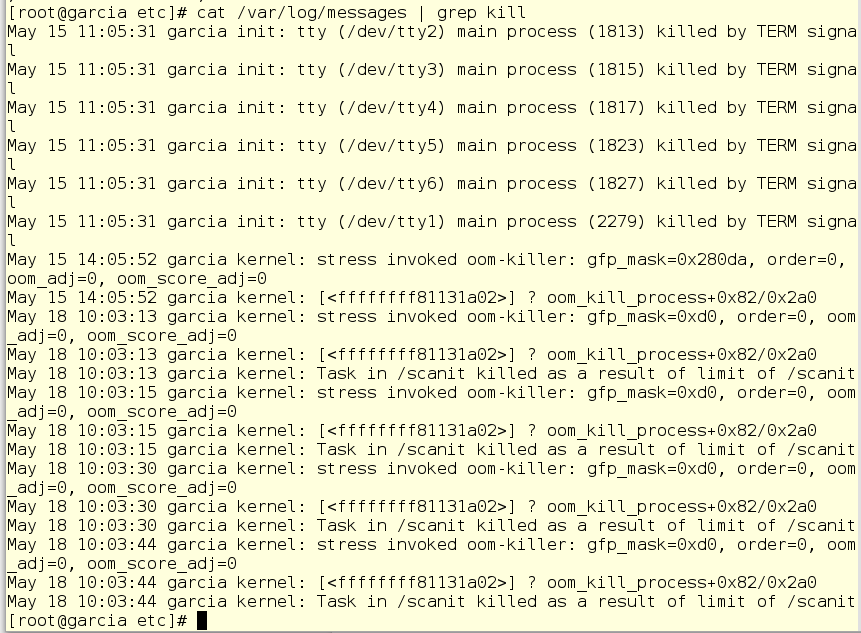
Now his system is trucking away! Time for an awesome 20 minute guitar solo...
Summary and closing
With this entry, I’m done with my series on cgroups. You should now have a good sense of what they are, how to use them on Red Hat Enterprise Linux 7, how to create them on Red Hat Enterprise Linux 6 and (hopefully) have been thinking through how they might be useful inside of your own environments.
I would love any feedback you may have - my email is mrichter at redhat.com
Next time - well, we’ll have to see what next time brings, won’t we?
Until then, keep on rockin in the free world!

Marc Richter (RHCE) is a Technical Account Manager (TAM) in the US Northeast region. He has expertise in Red Hat Enterprise Linux (going all the way back to the glory days of Red Hat Enterprise Linux 4) as well as Red Hat Satellite. Marc has been a professional Linux nerd for 15 years, having spent time in the pharma industry prior to landing at Red Hat. Find more posts by Marc at https://www.redhat.com/en/about/blog/authors/marc-richter
A Red Hat Technical Account Manager (TAM) is a specialized product expert who works collaboratively with IT organizations to strategically plan for successful deployments and help realize optimal performance and growth. The TAM is part of Red Hat’s world class Customer Experience and Engagement organization and provides proactive advice and guidance to help you identify and address potential problems before they occur. Should a problem arise, your TAM will own the issue and engage the best resources to resolve it as quickly as possible with minimal disruption to your business.
執筆者紹介

Marc Richter (RHCE) is a Principal Technical Account Manager (TAM) in the US Northeast region. Prior to coming to Red Hat in 2015, Richter spent 10 years as a Linux administrator and engineer at Merck. He has been a Linux user since the late 1990s and a computer nerd since his first encounter with the Apple 2 in 1978. His focus at Red Hat is RHEL Platform, especially around performance and systems management.
類似検索
Implementing best practices: Controlled network environment for Ray clusters in Red Hat OpenShift AI 3.0
Friday Five — December 12, 2025 | Red Hat
Technically Speaking | Platform engineering for AI agents
Technically Speaking | Driving healthcare discoveries with AI
チャンネル別に見る

自動化
テクノロジー、チームおよび環境に関する IT 自動化の最新情報

AI (人工知能)
お客様が AI ワークロードをどこでも自由に実行することを可能にするプラットフォームについてのアップデート

オープン・ハイブリッドクラウド
ハイブリッドクラウドで柔軟に未来を築く方法をご確認ください。

セキュリティ
環境やテクノロジー全体に及ぶリスクを軽減する方法に関する最新情報

エッジコンピューティング
エッジでの運用を単純化するプラットフォームのアップデート

インフラストラクチャ
世界有数のエンタープライズ向け Linux プラットフォームの最新情報

アプリケーション
アプリケーションの最も困難な課題に対する Red Hat ソリューションの詳細
仮想化
オンプレミスまたは複数クラウドでのワークロードに対応するエンタープライズ仮想化の将来についてご覧ください