Public clouds provide geo resilience in addition to being cost-effective when compared to on-premise deployments. Regulated industries such as the Financial Services Industry (FSI) traditionally have been unable to take advantage of public clouds since FSI is highly regulated from a security and resiliency standpoint.
Confidential computing (CC) and specifically confidential containers (CoCo) in the cloud provide data protection and integrity capabilities, facilitating the migration of financial workloads to the cloud.
In this blog we will look at the Financial Services Industry and how it can deploy relevant workloads such as fraud detection on public cloud instances using confidential computing building blocks. We will also take you through a demo of such a workload.
Confidential containers (CoCo) on Public Cloud
Confidential Containers (CoCo) is a project with a goal to standardize confidential computing at the pod level and simplify its consumption in Kubernetes. This enables Kubernetes users to deploy confidential container workloads using familiar workflows and tools without extensive knowledge of the underlying confidential computing technologies.
With CoCo, you can deploy your workloads on public infrastructure while also reducing the risk of unauthorized entities (including cluster admins) accessing your workload data and extracting your secrets. CoCo in the public cloud uses confidential virtual machines (CVMs) to provide the trusted execution environments for the containers.
For this article, we focus on the Azure cloud infrastructure — specifically, CoCo running in Azure public cloud with confidential VMs created via peer-pods and Intel® Trust Domain Extensions (Intel® TDX) providing Trusted Execution Environment (TEE) capabilities in the servers.
The following diagram shows the confidential containers solution we rely on in this blog:
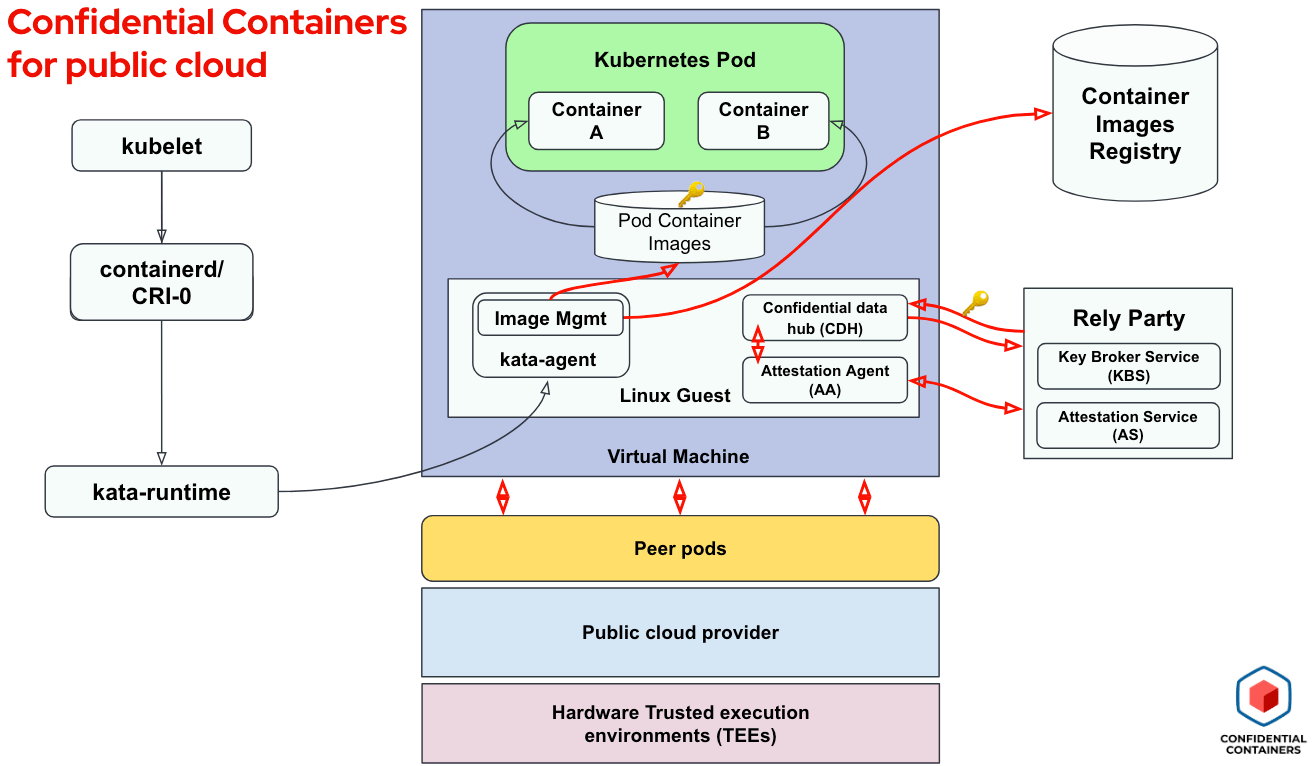
For details on the CoCo project—the Kata Containers project it emerged from, the architecture shown above, building blocks and attestation flow—we recommend reading our previous blog on Confidential containers for enhancing AI workload security in the public cloud.
Intel TDX for confidential computing
Intel TDX is a set of Intel CPU features designed to provide an extra layer of security and protection to VMs. VMs isolate data and hardware resources from other VMs, but any software or person with access to the corresponding main memory can access plaintext data. This includes firmware, BIOS, host OS and the host OS administrator. This is an issue when it comes to running sensitive workloads in a public cloud.
Intel TDX helps protect the memory of an individual VM by encrypting its data in main memory. A VM protected by Intel TDX is called a Trust Domain (TD), and the main memory of each TD is encrypted with a different, hardware-generated, hardware-managed and ephemeral key. The memory controller inside the CPU uses a unique key to transparently encrypt data belonging to a TD before writing it to the main memory and decrypting it on a read. Once inside the CPU caches and registers, the data is plaintext enabling highly performant processing. While the data is plaintext, the CPU enforces access control to only allow a TD to use its corresponding data. Other software, independent of the privilege level, cannot access the TD data. Overall, this adds protection for data while in use.
Before any sensitive data is provided to a TD, the legitimacy of the TD should be verified using attestation. With attestation, a TD can prove multiple facts to a third party. This helps verify that the workload runs on genuine Intel TDX-enabled hardware, the hardware was patched to a certain level and the expected VM image was loaded.
Existing workloads can be protected by Confidential Computing without modification. This enables cloud computing and workload scaling for even the most sensitive workloads. Preview instances supporting Intel TDX are available on Microsoft Azure, Google Cloud, Alibaba and Intel Developer Cloud.
The following diagram shows the standard VMs with isolation provided by the host virtual machine manager (VMM) compared to the isolation provided by Intel TDX using Trust Domains.

Confidential VMs on Azure
Confidential VMs (CVMs) on Azure provide a strengthened, hardware-enforced boundary to help meet your IT security needs (Intel TDX CVMs are available in public preview). Using CVMs and the open source Confidential Containers project, users can migrate their existing containerized workloads without modification into an encrypted and trusted environment. Cryptography-based proofs help validate that no one has tampered with the user’s workload, loaded software the user did not want, read or modified the memory used by the user’s workload, or injected a malicious CPU state to attempt to derail the initialized state. In short, it helps confirm that software runs without tampering, else it fails to run and the user is informed.
See Azure confidential computing for more information on this topic.
Financial Services Industry (FSI) and public cloud
FSI covers companies such as banks, insurance companies, and payment services. When we look at this industry it faces three main challenges.
1. Cost
With low interest rates comes a reduced opportunity to create revenue. As the rates are, at the beginning of 2024, again starting to be reduced, the opportunity for higher revenue is also reduced. So reducing cost is a focus for these industries.
2. Complexity
Some banks feel the need to swiftly change their services based on customer needs. This swift change can be more easily implemented when using a container-based platform not only supplied by an in-house infrastructure but also by a cloud infrastructure. With this new platform comes an increased complexity of operational processes. Reducing this complexity is one of the major goals to reduce possible errors and reduce induced costs of such complexity. Thus we would like to increase agility and streamline the operations while maintaining security and compliance.
3. Security
With the age of cloud computing comes the need to trust others when operating critical applications. Not all the services are now hosted in the safe harbor of an in-house datacenter, and trusting others with your critical business “secret sauce” can be difficult. This is not only seen by the FSI actors but also by the regulators. More and more regulations focus on components in the cloud, adding rules to be implemented, increasing the complexity and cost of operations.

The goal is to reduce all three challenges at once, but how can this be accomplished?
We will start by looking at some of the regulations that impact FSI companies and how these impact the overall costs.
Why are regulations so critical?
The FSI provides services that are critical for the economy. For example, if the services of a bank are offline, customers won’t be able to access an ATM, perform an online payment or transfer money.
For those reasons the FSI vertical is highly regulated and is considered system critical.
Government organizations are focused on increasing the likelihood that system critical services will continue working under every circumstance. That is why regulations are needed and organizations (regulators) are created. Those regulators are given a set of rules which system critical services need to follow and implements those rules via a review process of companies in the regulated industry, for example the FSI vertical. The more important a single institution is, the more rigorous the review process. Now with cloud services also coming into view, the regulators are focused on implementing rules for using cloud services and improving operational resilience. Various countries are implementing the new rules at different speeds, but many are looking at it. See this link for a comparison on the current status.
What does “regulation” mean?
The bigger the bank is, the more system critical it becomes and the more often its processes are reviewed by regulators. For larger banks, reviews happen sometimes yearly. With emerging regulations such as Digital Operational Resilience Act (DORA), the review process is expected to become yearly for all.
A typical review process can take several weeks during which a team of reviewers is placed in the building of the service provider / IT department. They investigate topics such as how the bank implements its operational processes, procedures the bank has put in place for handling security vulnerabilities, the bank's supply chain software, how the bank handles outages in different levels of their IT infra and a lot more. These reviewers assess how the bank plans for catastrophic events, such as an earthquake destroying the datacenter or a power cable being cut by an excavator, to more minor events such as a disgruntled employee corrupting data.
At the end of the review process the regulator will present findings which the bank is required to fix in a given timeframe. And, while cloud-based services result in a more rigorous review process, the overall effects of moving to the cloud are positive.
Moving system critical applications into the public cloud
There are several implications of moving system critical services into the cloud.
One of those is risk concentration. If multiple banks move their services to the cloud and they all choose the same cloud provider, an outage of that one provider could result in the outage of several banks. With this "risk concentration" comes an enhanced regulatory review process not only for the banks, but also the service provider. In DORA this is addressed by also targeting third parties providing information communication technology (ICT) services.
If that single cloud provider fails to supply the environments needed for the system critical applications, the banks need to provide a mitigation plan for potential outages. In the end it means they need to provide an exit strategy by moving their services from one cloud provider to the other. This is also addressed in regulations like DORA. In on-premise datacenters this was addressed by creating a second datacenter far away from the first to improve the chances that services would continue. But with a cloud provider this becomes more problematic as the cloud provider's infrastructure is an integrated network of services where a catastrophic failure could cause the whole infrastructure to fail. In the eyes of regulators this needs to be addressed by the aforementioned exit plan.
Another reason some banks might be hesitant to move to the cloud is the enormous volume of transactional data involved. Moving that volume of data from one cloud provider to the other is an extreme, but not insurmountable, challenge. One solution would be to partition the data into more manageable portions and use cloud services for those manageable portions of the transactions.
Is it possible to move to the cloud in a cost-efficient and uncomplicated manner?
We believe many of the challenges that exist for the FSI industry can be addressed by deploying confidential container workloads in the public cloud:
- Cost: By using a consumption-based environment only if and when it is needed, the cost of adding services is minimized. Such environments fit well with public cloud deployments.
- Complexity: When using a container platform which is available on all of the cloud providers, the complexity of moving an application from one provider to another is reduced.
- Security: By leveraging confidential containers data and business logic cannot be interacted with or even read (even the public cloud admin can’t see it). This allows applications to be moved from one cloud provider to the next without having to change the application or its security settings, as all of that is supplied by the TEE.
AI is a hot topic for the FSI vertical. As we are at the beginning of this evolution, various use cases are currently being developed. One use case is already at the fore: fraud detection.
Fraud detection needs learning systems to evaluate transactions to see if a possible fraud can be detected.
Use case: Fraud detection workloads in the public cloud
Here are a few of the assumptions we have for this FSI use case:
- Looking at an AI workload: For more details on AI workload we recommend reading our previous blog on Confidential containers for enhancing AI workload security in the public cloud.
- In the use case we describe here, the focus is on an OpenShift cluster running on-prem with a breakout to a public cloud to run a confidential container workload. This is done using peer-pods (for details see Red Hat OpenShift sandboxed containers: Peer-pods solution overview).
- The actual use case demoed in this article has the OpenShift cluster running on Azure public cloud (instead of on-prem), however, the building blocks are similar and we rely on Azure to support the confidential VMs (CVMs) and Intel to provide those VMs with TEE capabilities.
- Focusing on cost reduction: For an FSI to extend their current infrastructure to support such a workload is a costly process. Our focus is on consumption-based usage of AI resources instead of large CAPEX investments on-prem.
- Network traffic sent out of the cloud is costly so we would like to minimize it.
- For a regulatory and a security context we need to make sure that the host admin (server) will not be able to access the business logic and data, whether on-prem or public cloud.
- As described in DORA, it has to be possible to move services with no dependencies on the specific cloud services (for a DORA exit strategy, for example).
- In practice, the majority of FSIs haven’t extended their on-prem infrastructure with GPU capabilities.
Fraud detection workload overview
The focus of this use case is the ability to analyze transactions for fraud detection.
An FSI company has trained an AI model using on-prem infrastructure using its on-prem transaction data and customer data. The goal is to run the fraud detection workload with the AI model at scale, but this FSI company hasn’t yet upgraded its on-prem infrastructure to support the number of GPUs needed to run computing-intensive AI models.
The use of public cloud is also challenging for the FSI due to the regulatory requirements, such as General Data Protection Regulation (GDPR).
The following diagram shows the fraud detention workload running on-prem:
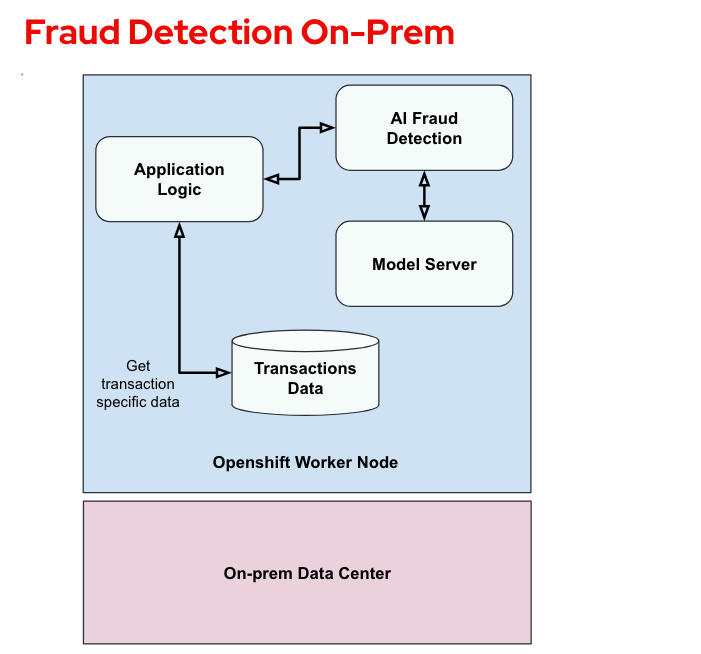
Note the following components:
- Application logic: Responsible for analyzing the transactions. For now the fraud detection is called for a single transaction, but the intention is to support bulk analysis of transactions in the future.
- AI fraud detection: Executing the trained fraud detection model.
- Model server: Where the trained model was uploaded.
- Transactions data: Where the transactional data is stored.
Fraud detection workload in public cloud
In order to provide the ability to run FSI workloads such as fraud detection in the public cloud we leverage the following components:
- Confidential containers (CoCo) for running the fraud detection workload
- Microsoft Azure Cloud for running CoCo and performing its attestation flows
- Intel TDX providing the TEE for the Azure instance
The idea is to create a TEE-based confidential container in the Azure public cloud with parts of the fraud detection workload running inside it. Since the workload is running in the public cloud it can leverage GPU capabilities which are also confidential. We can then establish a secure connection from the on-prem OpenShift cluster to the CoCo workload using peer-pods.
The following diagram illustrates this solution:

Here are the steps performed:
- An OpenShift cluster is running on the on-prem data center with access to the transactions data
- Using peer-pods, the OpenShift cluster creates a confidential container on the Azure public cloud leveraging the Intel TEE capabilities and attestation processes
- The AI fraud detection components requiring GPU capabilities are deployed inside the confidential container
- The connection to the confidential container in the public cloud is an attested connection, meaning the public cloud provider can’t see into it
- The model server in the confidential container workload is started and begins performing fraud detection analyses
- The fraud detection components running on the on-prem OpenShift cluster (left side) process the transaction data and then bundles the data to the public cloud AI fraud detection (right side) to analyze it
- The results from the analysis are sent back to the on-prem components
This deployment approach provides the following advantages when we look at cost:
- Transfering transactional data in bundles to the public cloud and returning short results back to the on-prem application saves on the connection cost (traffic moving out of the cloud is more expensive than traffic moving into the cloud)
- It uses consumption-based GPU in the public cloud, eliminating the need to extend on-prem infrastructure
- Asynchronous transactions can be compiled and executed in batches further reducing the overhead of a single call to the AI component in the public cloud
Demo: Deploying fraud detection with confidential containers
The use case we just described assumes the OpenShift cluster is running on-prem while the fraud detection workload is running in the public cloud using GPU resources. Given that some of the components required are still in tech preview and others are still being changed upstream, we assume the following for our demo:
- The OpenShift cluster also runs in Azure public cloud to avoid connecting on-prem to public cloud environments
- The fraud detection workload deployed in the public cloud runs without GPUs at this point and uses CPU resources instead (GPU attested interfaces are still being integrated into confidential containers)
Before starting with the confidential containers implementation, it is worth mentioning that there are two phases after an AI model is developed, which are training and inferencing.
- Training is how the newly developed model learns how to do its job, usually providing massive quantities of existing data that has already been validated and selected for the purpose of learning. It's as if the AI model is going to school. This phase requires a lot of computing effort, and speeding it up is usually achieved through additional GPUs.
- Inferencing is where the model is moved to the “production” phase—the AI is facing new previously-unseen data, and has to evaluate it and provide answers.This phase is also usually done using GPUs. In practice, however, depending on the AI model and the type of decisions that it’s required to make (object detection is different from fraud recognition, for example), it can also be feasible using CPUs only.
In this demo we will be focusing on the inferencing part using CPUs in the public cloud. In the future we'll provide a similar demo using GPUs.
The Red Hat OpenShift AI operator
The Red Hat OpenShift AI operator lets developers perform both the training and inferencing phases with OpenShift. Training and development use Notebooks or Pipelines, while inferencing is performed via Model Serving.
The OpenShift AI operator also offers a variety of models and development environments to develop an AI model, including the OpenVINO toolkit. In this demo, we are going to simplify the process and focus on the inferencing part, providing an already trained OpenVINO .onnx model to the OpenShift AI operator.
Overall flow and components
We will base our demo on the Fraud Detection workshop with Red Hat OpenShift Data Science (Red Hat OpenShift AI was previously known as Red Hat OpenShift Data Science) which we build upon to support confidential containers. This basic workshop walks you through the necessary steps to train and inference a fraud detection workload.
The following diagram shows the operator stack and component connections between the OpenShift AI, Openshift Serverless and Openshift Service Mesh operators used in this demo. Given that there are a lot of details, for additional information on the components and flow we recommend reading Red Hat OpenShift AI documentation.

The inference service pod is the part of this demo that is deployed as a confidential container, as shown in the following diagram:
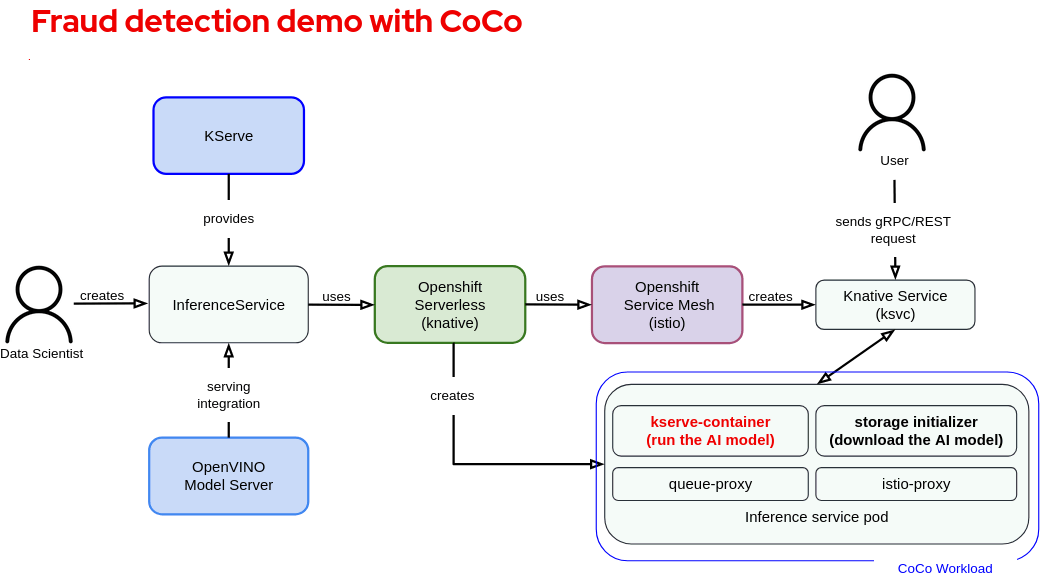
Fraud detection WITHOUT CoCo
After following all the steps of the Fraud Detection workshop, the data science project (namespace) will contain 3 pods, created in the following order:
- A Notebook pod for the training with persistent storage attached to it. This is a Jupyter notebook where the developer can download his code, apply changes and test new features locally. Once the model is ready, the notebook performs the necessary steps to train the model. Training can be also automated with Pipelines. The Notebook pod uploads the finished model in a local storage container.
- A minio pod for local storage containing the trained model.
- An InferenceService pod for the inferencing part responsible for downloading the model and running it, making it available for the user with the Kserve + OpenShift Serverless + OpenShift Service Mesh + Knative Service mesh stack shown above. As mentioned this pod will run later on inside the confidential container.
As mentioned above, our focus is on inference and not training thus we focus on the Inference service pod. We will assume training and model uploading is performed in a secure environment that we will refer to as the “User secure environment”. The following diagram shows the overall workflow:
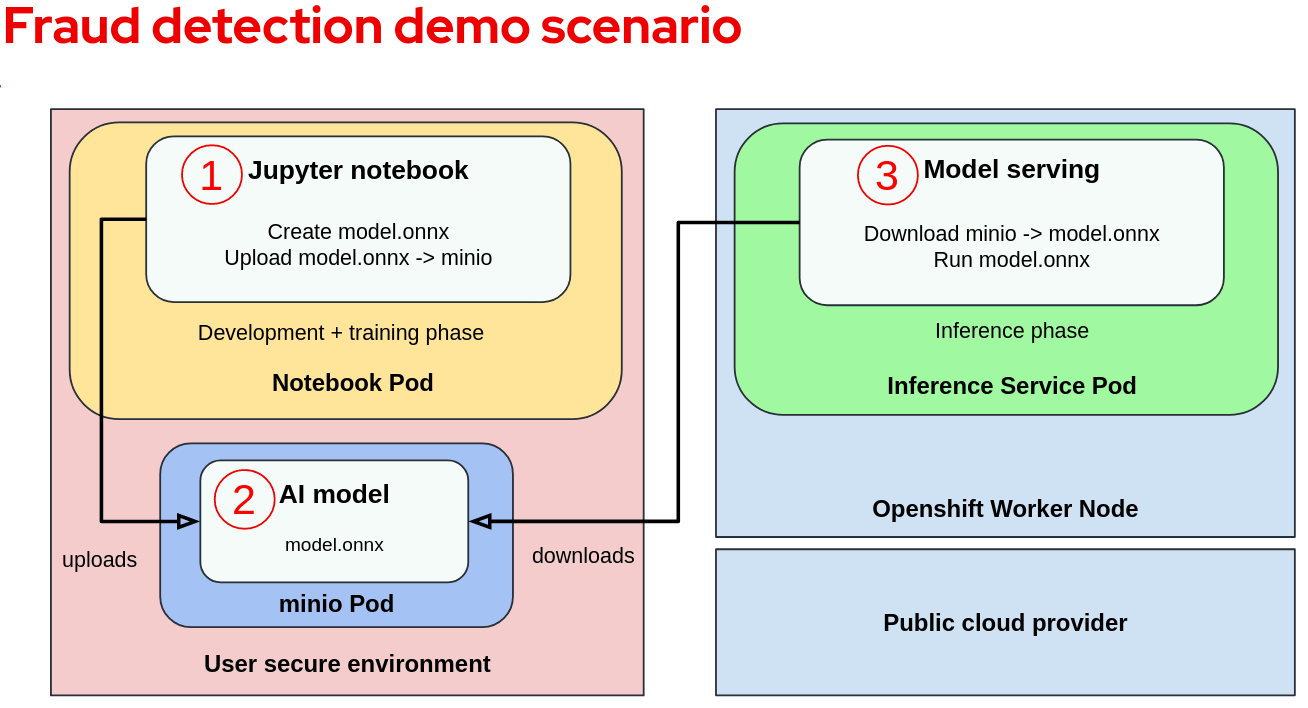
Attacker perspective - why are we using CoCo?
Given the standard scenario above, we identify the following attacker:
A malicious infrastructure or cluster administrator can access or alter the model parameters and related data without proper authorization. For instance, they could access the memory of the worker node and get access to the data (like the credit card transactions) or the model parameters.
The reason to use confidential containers is to protect the model from any external entity.
Fraud detection with confidential containers
The first step is to encrypt the model and then upload it to the storage (minio pod). For the purpose of this demo and given our assumptions, we changed the training code to make sure that the generated model is encrypted after being trained.
The following diagram shows the changes required when encrypting the model:
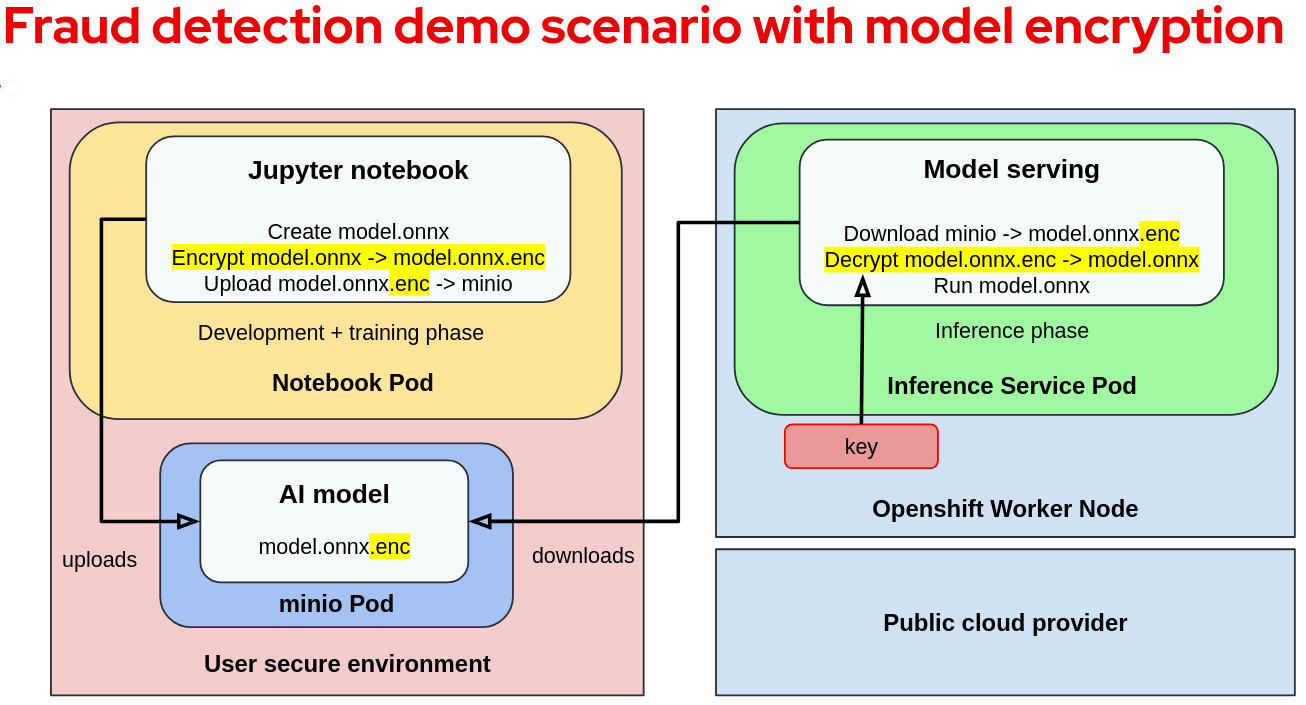
It is a common misconception that encrypting a model is enough to prevent inside actors such as malicious infrastructure or cluster administrators from accessing it. In practice, the cluster administrator can access the key from the worker node. On top of that, the infrastructure administrator can access the key by reading the worker node's memory.
This is where confidential containers come in to prevent insider threats by making sure infrastructure admins aren't trusted and can't access the container memory.
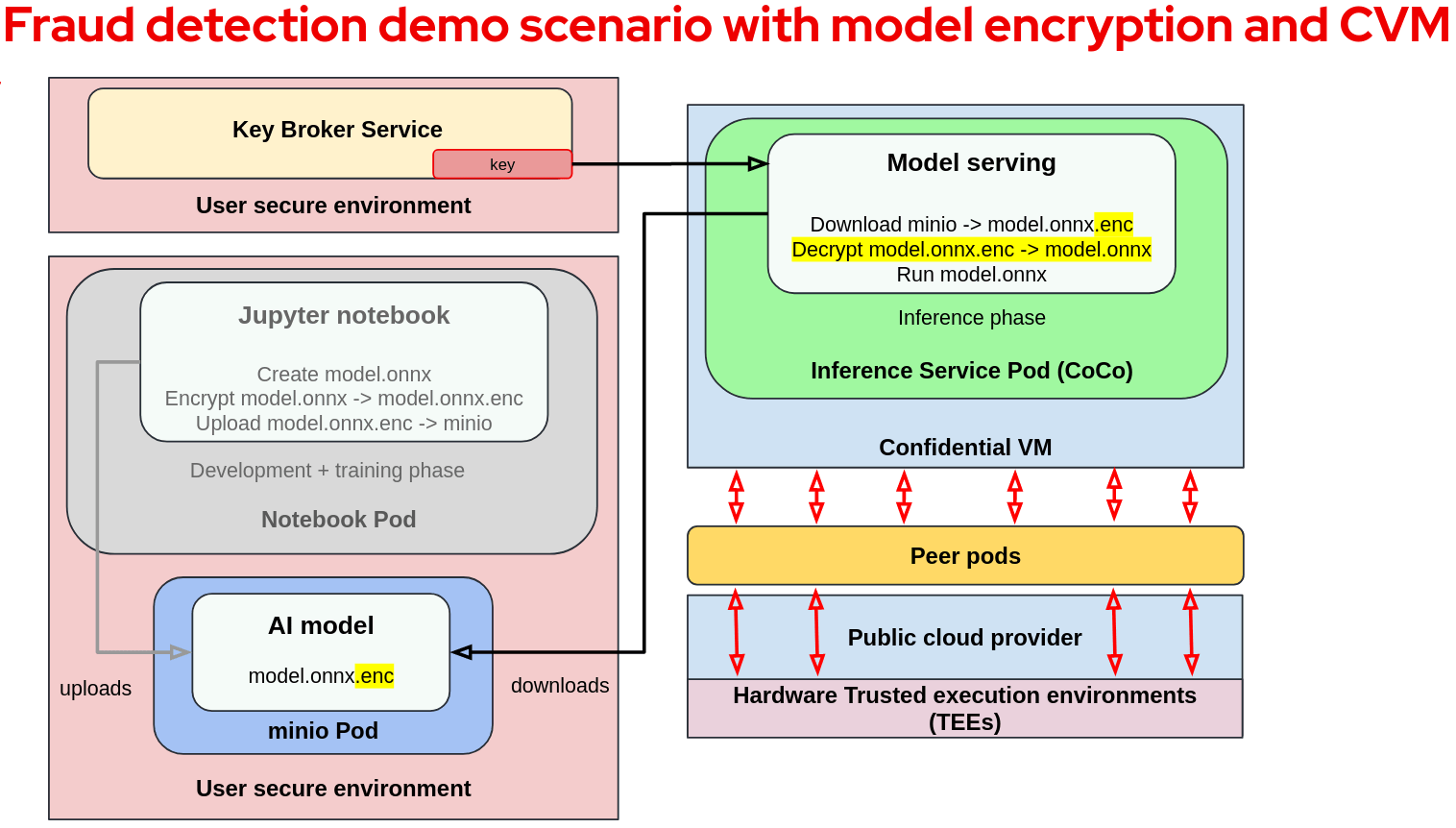
The model decryption key is made available only inside the VM TEE running the container. The key is made available by the Key Broker Service (KBS) after a successful attestation process which verifies the TEE running the container workload.
The KBS is a service provided as part of the CoCo project, and is responsible for attestation and key management. It is typically deployed in a user secure environment. Once the key is received, the model server will decrypt and run the model.
For details on the KBS and attestation flow we recommend reading our previous blog on Confidential containers for enhancing AI workload security in the public cloud.
The following diagram shows the fraud detection workload running with encrypted models and confidential containers (training parts are grayed out to simplify the picture):
Comparing fraud detection with and without CoCo
To conclude, let’s compare the CoCo approach with the original approach:
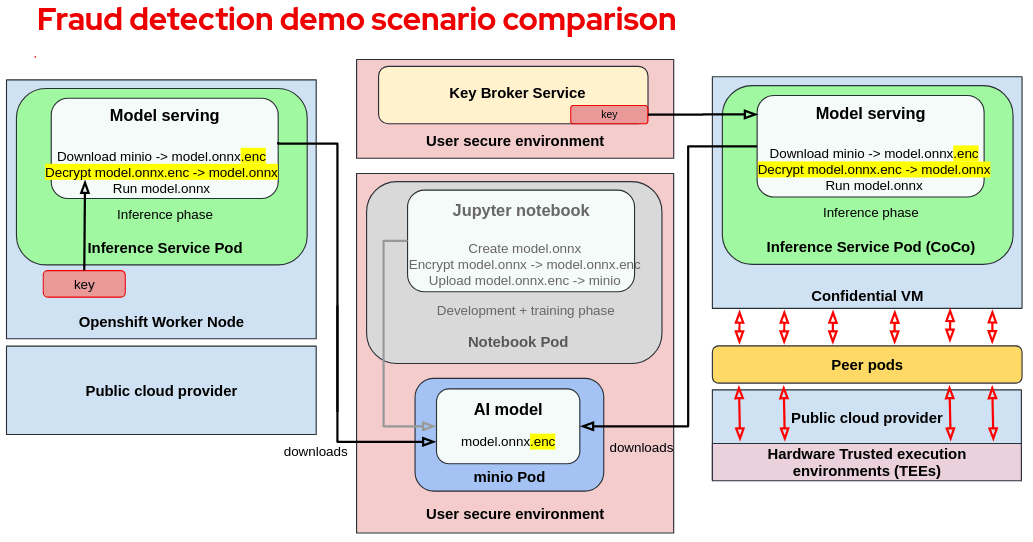
Note the following:
- On the left side of the diagram, we have the standard scenario with an encrypted model running on an OpenShift worker node.
- On the right side, we have the CoCo scenario with an encrypted model running in a CVM.
- In the middle, we find the User secure environment where the key and encrypted model are safely stored.
From this comparison we can point out the following:
- For a regular container the model decryption key that is available on the worker node is vulnerable to unauthorized access.
- In the case of CoCo, the decryption key is available inside the VM TEE provided by the CVM and is not available to any entity that is external to the VM TEE. Even reading the memory of the VM TEE will show garbage as its encrypted memory.
YouTube demo video
Summary
The cloud industry is moving towards servers with CPUs supporting confidential computing. In the upcoming years this is likely to become a standard offering on public clouds. Today the majority of FSI customers have not decided what AI services they would like to provide or how to provide them. Their current on-prem environments lack pools of GPU support for AI workloads among other limitations. By providing confidential computing capabilities in the public cloud, the notion of running workloads for the FSI is becoming feasible including for AI workloads.
FSI regulations are also evolving and will support the FSI workloads on public cloud assuming they can maintain operational resiliency by making sure that system critical services can be provided uninterrupted.
In this blog we have shown how FSI workloads such as fraud detection can be deployed in the public cloud while still maintaining the operation resiliency through confidential computing tools. We have shown how we can leverage confidential containers on Azure cloud with Intel TDX technology to protect the FSI workload from the cloud provider itself.
Sobre os autores

Master of Business Administration at Christian-Albrechts university, started at insurance IT, then IBM as Technical Sales and IT Architect. Moved to Red Hat 7 years ago into a Chief Architect role. Now working as Chief Architect in the CTO Organization focusing on FSI, regulatory requirements and Confidential Computing.


Jens Freimann is a Software Engineering Manager at Red Hat with a focus on OpenShift sandboxed containers and Confidential Containers. He has been with Red Hat for more than six years, during which he has made contributions to low-level virtualization features in QEMU, KVM and virtio(-net). Freimann is passionate about Confidential Computing and has a keen interest in helping organizations implement the technology. Freimann has over 15 years of experience in the tech industry and has held various technical roles throughout his career.
Emanuele Giuseppe Esposito is a Software Engineer at Red Hat, with focus on Confidential Computing, QEMU and KVM. He joined Red Hat in 2021, right after getting a Master Degree in CS at ETH Zürich. Emanuele is passionate about the whole virtualization stack, ranging from Openshift Sandboxed Containers to low-level features in QEMU and KVM.


Magnus has received an academic education in Humanities and Computer Science. He has been working in the software industry for around 15 years. Starting out in the world of proprietary Unix he quickly learned to appreciate open source and has applied it everywhere since. He was engaged mostly in the niches of automation, virtualization and cloud computing. During his career in various industries (mobility, sustainability, tech) he exercised various contributor and leadership roles. Currently he's employed as a Software Engineer at Microsoft, working in the Azure Core organization.

Suraj Deshmukh is working on the Confidential Containers open source project for Microsoft. He has been working with Kubernetes since version 1.2. He is currently focused on integrating Kubernetes and Confidential Containers on Azure.
Mais como este
OpenShift: Consistent integration for the hybrid enterprise
When AI finds the bugs: Why defense in depth was always the answer
Collaboration In Product Security | Compiler
Keeping Track Of Vulnerabilities With CVEs | Compiler
Navegue por canal

Automação
Últimas novidades em automação de TI para empresas de tecnologia, equipes e ambientes

Inteligência artificial
Descubra as atualizações nas plataformas que proporcionam aos clientes executar suas cargas de trabalho de IA em qualquer ambiente

Nuvem híbrida aberta
Veja como construímos um futuro mais flexível com a nuvem híbrida

Segurança
Veja as últimas novidades sobre como reduzimos riscos em ambientes e tecnologias

Edge computing
Saiba quais são as atualizações nas plataformas que simplificam as operações na borda

Infraestrutura
Saiba o que há de mais recente na plataforma Linux empresarial líder mundial

Aplicações
Conheça nossas soluções desenvolvidas para ajudar você a superar os desafios mais complexos de aplicações
Virtualização
O futuro da virtualização empresarial para suas cargas de trabalho on-premise ou na nuvem