



Workloads that handle sensitive or regulated information such as medical, financial, location data or high value IP such as machine learning models require additional security. This includes memory encryption, integrity tracking, access control from privileged processes and more. Confidential computing technologies provide trusted execution environments (TEE), which allow for these additional isolation capabilities. The CNCF Confidential Containers (CoCo) project provides a platform for running confidential cloud-native solutions in your familiar Kubernetes environment.
Using CoCo for AI workloads such as FaceApp provides a powerful tool to more safely process sensitive data in the cloud, knowing that neither the cloud service provider nor other workloads sharing the same infrastructure can access or manipulate it.
In this blog we will review how Azure, Intel and Red Hat are collaborating to enhance the security of AI workloads with CoCo. We will cover Intel® Trust Domain Extensions (Intel® TDX) which provides confidential computing capabilities, Azure confidential virtual machines (CVM), the Red Hat OpenShift CoCo solution, and Red Hat OpenShift AI. We will explain and demonstrate how these building blocks come together to deliver a more secure end-to-end AI solution.
Confidential Containers (CoCo) in the public cloud
Kata Containers: A brief overview
Kata Containers is an open source project that provides a container runtime for creating a virtual machine (VM) which is exposed as a pod with the container workloads running inside it. The pod level VM provides stronger workload isolation through virtualization technology. OpenShift sandboxed containers (OSC), based on Kata Containers, provides those capabilities as part of Red Hat OpenShift.
The following diagram shows the major components involved in a Kata solution:

Let’s go over the main components used in the Kata Containers (and OSC) solution.
- cri-o/containerd: Implements the Container Runtime Interface and provides an integration path between OCI runtimes and Kubelet. cri-o is the default in OpenShift.
- Kata runtime: Responsible for spinning up a Virtual Machine (VM) for each Kubernetes pod and launching the pod containers within it. The containers are “sandboxed” inside the VM.
- Local hypervisor support: The component within the Kata runtime that actually interacts with a hypervisor to spin up a VM. Kata supports a variety of hypervisors, which includes KVM/QEMU for bare metal deployments and peer-pods for Azure cloud deployments which we shall cover in more detail later.
- Pod VM: A VM pod that for all practical purposes is a Kubernetes pod.
- Kata agent: A process running inside the VM pod as a supervisor for managing the containers within and the processes running within them.
The following diagram shows the flow for creating a pod using Kata runtime:

Let’s go over the steps:
- A new pod creation request is received by the Kubelet
- Kubelet calls CRIO (in the case of OSC)
- CRIO calls the kata-runtime
- The kata-runtime spins up a new VM using the local hypervisor - KVM/QEMU
- The VM starts the kata-agent process
- The kata-runtime sends container creation request to the kata-agent process running inside the VM
- The kata-agent spins up the containers comprising the pod inside the VM
Peer-pods: Running Kata Containers in the public cloud
As described above, the existing Kata solution uses tools such as KVM/QEMU to launch VMs on bare-metal servers. These bare-metal servers are the Kubernetes worker nodes. This is as opposed to a more typical deployment of Kubernetes where the controller/worker nodes are deployed as VMs on top of the bare-metal servers (for example, in cloud deployments).
For supporting Kata Containers (and OSC) in the cloud we use peer-pods, also known as the Kata remote hypervisor (note that this repository is in the Confidential Containers GitHub and not in Kata GitHub; we will get back to this point later on).
The peer-pods solution enables the creation of Kata VMs on any environment without requiring bare-metal servers or nested virtualization support (yep, it’s magic). It does this by extending the Kata containers runtime to handle VM lifecycle management using cloud provider APIs (e.g. Microsoft Azure).
The following diagram shows the major components involved in the peer-pods solution (extending the Kata architecture previously described):

Let’s go over the different components mentioned in this diagram (on top of the ones previously mentioned in the Kata architecture section):
- Remote hypervisor support: Enhances the shim layer to interact with the cloud-api-adaptor instead of directly calling a hypervisor as previously done
- cloud-api-adaptor: Enables the use of the OpenShift sandboxed containers in a cloud environment and on third-party hypervisors by invoking the relevant APIs
- agent-protocol-forwarder: Enables kata-agent to communicate with the worker node over TCP
The following diagram shows the Kata solution using peer-pods:
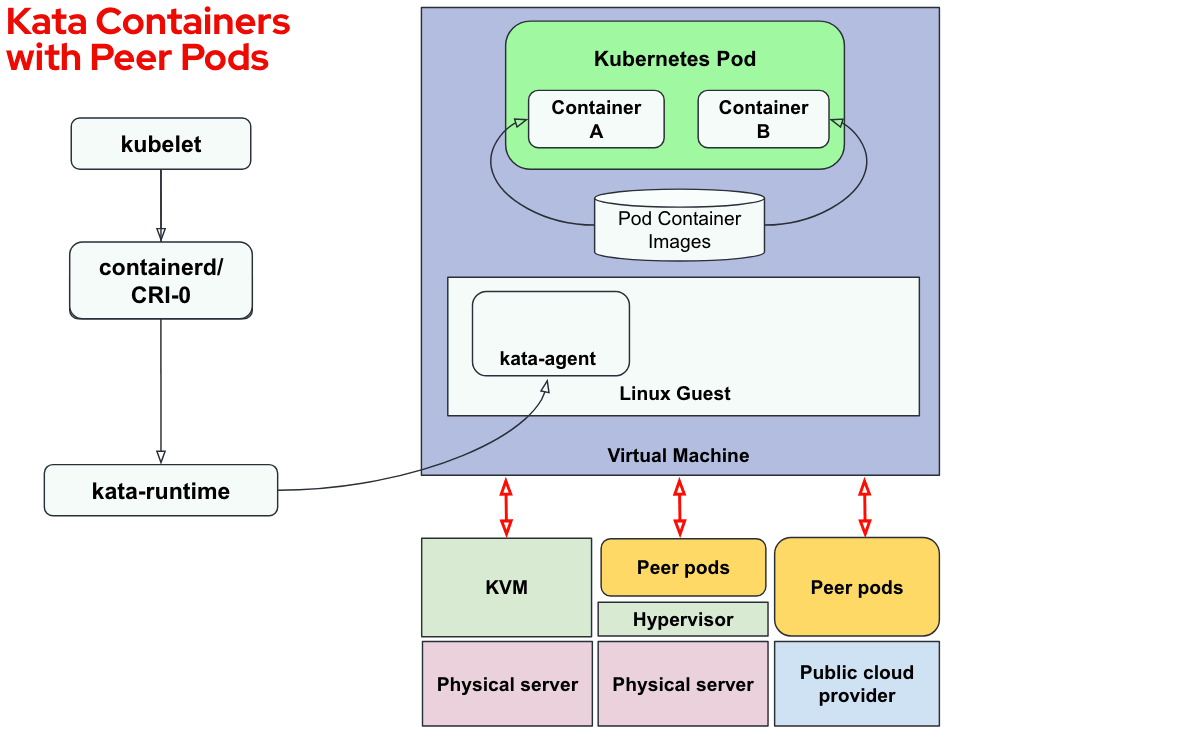
The Kata VM can now be deployed on the following environments:
- KVM: Same solution as described in the previous Kata section. Kata VM calls the hypervisor running on the physical server. Note that if the Kubernetes node is running on a VM, we invoke the VM KVM resulting in a nested Kata VM (VM running inside a VM).
- Peer-pods with direct access to a hypervisor (not nested): Using the peer-pods solution, we can now have our Kubernetes node running on a VM and instead of creating the Kata VM from the hypervisor inside the VM (such as KVM), we use the physical server hypervisor (such as KVM, VMware etc.). So the resulting Kata VM (peer-pods based) is a standard VM and not nested.
- Peer-pods on public cloud: Using peer-pods on a public cloud, we can invoke the cloud provider APIs (such as Azure APIs) to create a VM on a remote bare-metal server. Note that no nested virtualization is required in this solution. This approach will be the focus of this article.
For more information on peer-pods we recommend reading our previous blogs Peer-pods solution overview, Peer-pods technical deep dive and Peer-pods hands-on.
What is CoCo?
The goal of the CoCo project is to standardize confidential computing at the pod level and simplify its consumption in Kubernetes. This enables Kubernetes users to deploy confidential container workloads using familiar workflows and tools without extensive knowledge of the underlying confidential computing technologies.
With CoCo, you can deploy your workloads on public infrastructure yet significantly reduce the risk of unauthorized entities accessing your workload data and extracting your secrets. For this article, we focus on the Azure cloud infrastructure.
Confidential Containers architecture and its building blocks
The CoCo project, as stated earlier, uses Kata Containers as a key building block. Firstly CoCo launches a confidential VM (CVM), also known as a Trusted Execution Environment (TEE) or enclave, instead of a legacy VM. This could be a local VM or a remote VM using peer-pods. CoCo also introduces, in addition to the kata-agent in the CVM, the “enclave software stack” consisting of image-management, confidential data hub and the attestation agent. The following diagram provides a high-level view of the main components that the CoCo solution consists of and interacts with (note how additional blocks are added to the Kata Containers previous solution):
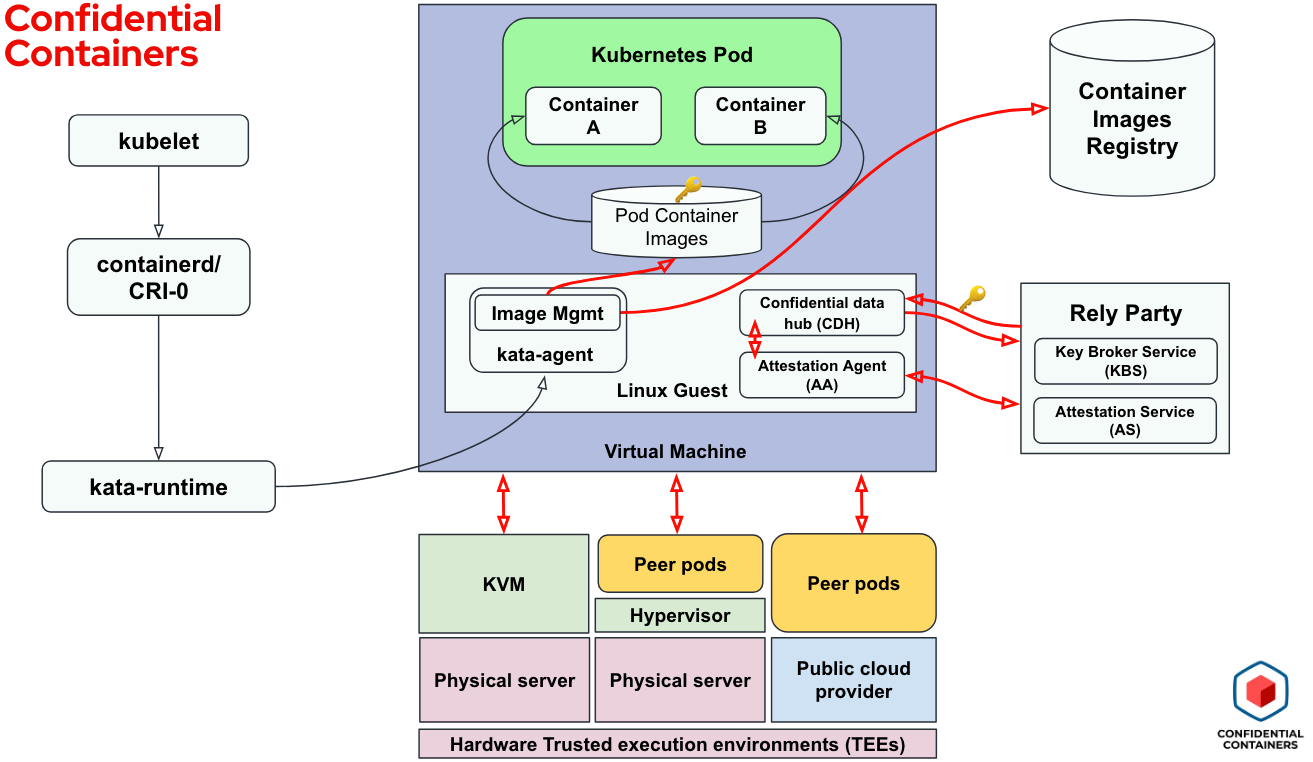
The container images are downloaded and kept inside the enclave and can be either signed and/or encrypted.
The enclave software stack is measured, which means that a trusted cryptographic algorithm is used to measure the guest image and other entities running within the confidential VM. These measurements can be used for attestation purposes. Access to secrets—including encryption keys to decrypt the container image itself or to unlock a database used by the workload—can be controlled, released only when the enclave is attested to be valid.
Attestation is the process of verifying that an enclave measurement meets some user specified criteria. The attestation agent is responsible for initiating attestation and fetching of the secrets from the key broker service. Overall, the kata-agent is responsible for downloading the container images, decrypting or verifying the signatures and creating and running the containers.
Supporting components for the solution are the container image registry and the relying party, which combines the attestation and key broker services. While a container image may contain multiple layers, they may not all be encrypted, and individual layers may be encrypted with a different key.
CoCo attestation and key management components
In CoCo, attestation involves using cryptography-based proofs to ensure your workload is free from tampering. This process helps validate that your software is running without any unauthorized software, memory modification, or malicious CPU state that can compromise your initialized state. In short, CoCo helps confirm that your software runs without tampering in a trusted environment.
The Attestation Agent (AA) is a process on the VM (peer-pod VM in our case) providing a local facility for secure key release to the pod. It is part of guest-components. It gathers the TEE evidence to prove the confidentiality of its environment. The evidence is then passed to the Key Broker Service (described below), along with the request for a specific key.
The Key Broker Service (KBS) is a discrete, remotely deployed service acting as a Relying Party. It manages access to a set of secret keys and will release those keys depending on the authenticity of the Evidence provided by the AA and conformance with predefined policies. KBS is a remote attestation entry point that integrates the Attestation Service (described below) to verify the TEE evidence.
The Attestation Service (AS) is a component responsible for verifying that the Evidence provided to the KBS by an Attester is genuine. AS verifies the evidence signature and the Trusted Computing Base (TCB) described by that evidence. Upon successful verification, it will extract facts about the TEE from the given Evidence and provide it back as a uniform claim to the KBS. It can be deployed as a discrete service or integrated as a module into a KBS deployment.
Given that we have an application running inside a confidential pod (backed by a confidential VM) requiring a secret key, the following diagram illustrates the CoCo attestation workflow:

Following are the steps (marked by numbers):
- Within a peer-pod confidential VM, the confidential pod reaches out to the AA in Guest Components for obtaining a secret key
- The AA requests the secret key from the KBS
- The KBS answers with a cryptographic nonce which is required to be embedded in the Evidence to ensure this particular exchange cannot be replayed
- The AA sends the evidence to the KBS
- The KBS will verify this evidence with the AS
- If the verification is successful the KBS releases the key to the AA
- The AA then provides the key back to the confidential pod to continue its flow
For more details on the topic of attestation we recommend reading the blog series Learn about Confidential Computing Attestation.
For a deeper understanding of how attestation happens in practice on Azure cloud for the case of AMD SEV-SNP (which this work is based on), we recommend reading Confidential Containers on Azure with OpenShift: A technical deep dive.
CoCo with Peer-pods on Azure public cloud
Bringing these building blocks together, we want to zoom into CoCo running on public clouds, such as Azure cloud in our case. For that, we focus only on a VM created with peer-pods in a public cloud provider. The following diagram shows this solution:

Note that we now only have peer-pods as the layer for creating confidential virtual machines.
Intel TDX
Intel TDX is Intel's newest hardware-based confidential computing technology. This hardware-based TEE facilitates the deployment of trust domains (TDs), which are hardware-isolated VMs designed to enhance the protection of sensitive data and applications from unauthorized access. The memory and register state associated with the TEE are encrypted with a key specific to the TEE and accessible only to the hardware.
A CPU-measured Intel TDX module enables Intel TDX. This software module runs in a new CPU Secure mode and the module itself resides in special reserved memory.
Intel TDX delivers greater confidence in data integrity, confidentiality and authenticity, which enables engineers and tech professionals to create and maintain more secure systems, establishing more trust in virtualized environments.

For more detailed information, please review the developer documentation for Intel TDX at: Intel TDX documentation.
Confidential VMs on Azure
Confidential VMs on Azure provide a strengthened, hardware-enforced boundary to help meet your IT security needs. You can migrate your existing containerized workloads without modification to run as an Azure peer-pod. Cryptography-based proofs (see the previous attestation section) help validate that no one has tampered with your workload, loaded software you did not want, read or modified the memory used by your workload, or injected a malicious CPU state to attempt to derail your initialized state. In short, it helps confirm that your software runs without tampering, else it fails to run and you will know about it.
See Azure confidential computing for more information on this topic.
How to better secure AI workloads in the public cloud?
What is Red Hat OpenShift AI?
OpenShift AI provides tools across the full lifecycle of AI/ML experiments and models. OpenShift AI provides a flexible, scalable MLOps platform to reduce complexity, empower teams to focus on innovation, and improve security, reliability and efficiency. It enables ITOps to provide their data science and application teams the tools they need to build, deploy and manage AI-enabled applications across the open hybrid cloud.
CoCo for AI workload security
We will utilize the KServe/Caikit/TGIS stack for the deployment and monitoring of a sample large language model (LLM). The Caikit/TGIS Serving image is a combined image that allows data scientists to perform LLM inference. Inference in the context of LLMs relates to the model’s ability to generate predictions or responses based on the context and input it has been given. That is, when a model is given a prompt, it will use its understanding of the language and context to generate a response that is relevant and appropriate.
In general we would like to first fine-tune the model and then deploy it. In this article, however, we will focus on the deployment portion of it. For additional details on fine-tuning LLMs see Fine-tuning and Serving an open source foundation model with Red Hat OpenShift AI.
The KServe/Caikit/TGIS stack is composed of:
- KServe: A Kubernetes orchestration component that handles the lifecycle of a model serving inference engine.
- Text Generation Inference Server (TGIS): A high performance inference engine which is the back end for serving models. Inference engines load the actual models into memory, take in data and produce the results from the model.
- Caikit: An AI toolkit/runtime that, in this case, is being used to connect to a TGIS backend. Caikit provides several more advanced features like serving of a prompt tuned model. The advanced features aren't being used in this demo, but Caikit is providing the serving endpoint that users communicate with.
- Red Hat OpenShift Serverless: This is based on the open source Knative project that enables developers to build and deploy enterprise-grade serverless and event-driven applications.
- Red Hat OpenShift Service Mesh: This is built upon the open source Istio project that provides a platform for behavioral insight and operational control over networked microservices in a service mesh.
The following diagrams shows the interactions between components and user workflow for the KServe/Caikit/TGIS stack:

To deploy the model, we will use Caikit/TGIS serving runtime and backend, which simplifies and streamlines the scaling and maintenance of the model. We will also use KServe, which provides a more reliable and advanced serving infrastructure. In the background, OpenShift Serverless (Knative) will provision a serverless deployment of the model, while OpenShift Service Mesh (Istio) will handle all the networking and traffic flow.
Our focus for this article is only on the Inference Service pod (lower right block in the above diagram). An inference service is a server that accepts input data, passes it to the model, executes the model and returns the inference output. Using this service, the user can then perform inference calls asking the model to complete a sentence of your choice (which will be shown in the demo later on).
The inference service pod is where the magic really happens: it’s where your trained model is running and the data is processed. This is also where CoCo comes into the picture.
We want to protect the following:
- The AI model: The secret sauce which the model owner worked hard to train and perfect.
- The data used by the model: Potentially private data that we need to ensure no one can see or tamper with.
We will use CoCo for running the inference service pod and help secure it from the cloud provider itself.
The following diagram shows what this solution looks like:

The general flow is the same, including the interaction with Knative, Istio and KServe. What changes is that we now run the pod as a CoCo workload. This is made possible by using a specific RuntimeClass. Additionally, we are using a custom KServe storage initializer which downloads the encrypted model, retrieves the key from the KBS and decrypts the model for use by the ServingRuntime (CaiKit+TGIS).
Demoing the use case
Summary
As AI workloads are becoming increasingly mainstream, the topic of confidentiality—both for the AI models (the secret sauce of the workload) and the data being processed (medical, financial, personal etc.)—will become critical.
In this article, we have shown how CoCo can be used to mitigate those risks to help AI workloads run more safely on Azure public cloud using Intel TDX for creating TEEs (as of November 2023 TDX is still a private preview on Azure). These AI workloads are fully isolated inside the cloud, both from other workloads and from the cloud provider admins themselves, since everything related to this workload is encrypted by hardware and keys only the workload owner knows.
In future articles, we plan to provide hands-on instructions for deploying the AI workloads covered here.
About the authors
Pradipta is working in the area of confidential containers to enhance the privacy and security of container workloads running in the public cloud. He is one of the project maintainers of the CNCF confidential containers project.
Suraj Deshmukh is working on the Confidential Containers open source project for Microsoft. He has been working with Kubernetes since version 1.2. He is currently focused on integrating Kubernetes and Confidential Containers on Azure.
More like this
Can't patch fast enough? Zero trust as a last line of defense
Govern privileged workload boundaries with Red Hat OpenShift, Ansible Automation Platform, and Identity Management
Collaboration In Product Security | Compiler
Keeping Track Of Vulnerabilities With CVEs | Compiler
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds