
- Every data source requires a custom schema. This design means you must spend more time deciding how to store your data. Also, if there are changes in the underlying data source, you may have to alter your table schemas.
- A traditional relational database doesn't expire data. You often want to keep time-series data only for a certain period and discard the rest automatically.
- New time-series databases have optimized their storage format to make it quicker for multiple clients to write data and also faster to read the latest data. Relational databases worry much more about data duplicates and row-lock contention.
[ target="_blank">Top considerations for cloud-native databases and data analytics. ]
In this tutorial, I will show you how to use InfluxDB, an open source time-series platform. I like it because it offers integration with other tools out of the box (including Grafana and Python 3), and it uses Flux, a powerful yet simple language, to run queries.
Prerequisites
This tutorial requires:
- A Docker or Podman installation to run InfluxDB. You can also do a bare-metal installation, but I won't cover that here
- InfluxDB 2.4.0 or higher
- Flux for queries (instead of FluxQL)
- A Linux distribution (I use Fedora Linux)
- Python 3 and some experience writing scripts
- Basic knowledge of relational databases like MariaDB can be useful, but it is not required to use Flux
Run an InfluxDB server from a container
A container might be the easiest way to get started. Use an external volume to persist the data across container reboots and upgrades (please check the container page to see all the possible options):
$ podman pull influxdb:latest
$ podman run --detach --volume /data/influxdb:/var/lib/influxdb --volumne /data:/data:rw --name $ $ $ influxdb_raspberrypi --restart always --publish 8086:8086 influxdb:latest
$ podman logs --follow influxdb_raspberrypiMap an additional volume called /data inside the container to import some CSV files later.
Next, go to the machine where you are running InfluxDB (say http://localhost:8086) and complete the installation steps:
- Create a new user.
- Create a bucket (the equivalent of a relational database table) with no expiration where you will put your data. For reasons you will see below, call it USTS (short for underground storage tanks).
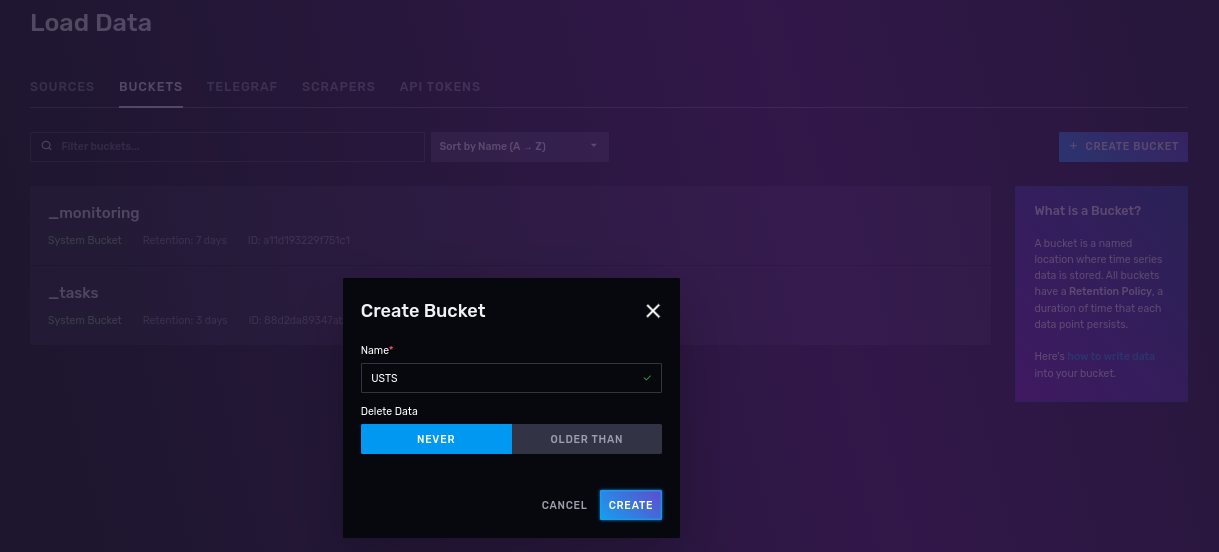
3. Create a read/write API token that works only on the USTS buckets.
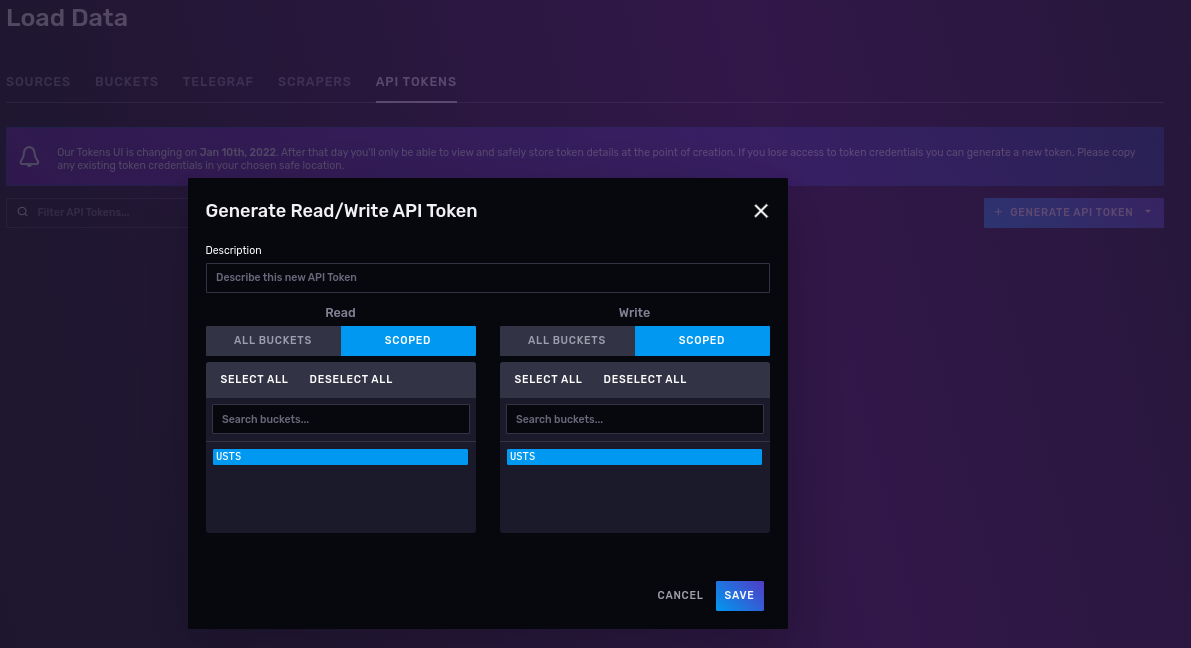
The API token will look similar to this:
nFIaywYgg0G6oYtZCDZdp0StZqYmz4eYg23KGKcr5tau05tb7T2DY-LQSIgRK66QG9mkkKuK2nNCoIKJ0zoyng==Keep your token safe, as you will use it to read and write data into your USTS bucket.
Work with datasets
In this tutorial, I will use publicly available data from the Connecticut Open Data Portal.
Specifically, I will use the Underground Storage Tanks (USTs) - Facility and Tank Details data (download). The underground storage tank regulations and the Connecticut underground storage tank enforcement program have been in effect since November 1985. This list is based on notification information submitted by the public since 1985 and is updated weekly.
I like this dataset for the following reasons:
- It's a relatively extensive dataset, with 49.1K rows and 27 columns. This will require some data normalization and large-data import techniques.
- It has data in the form of time series (Last Used Date column).
- It also has geographical details (latitude and longitude coordinates), which can be used to run some interesting queries using the geolocation experimental features.
You can grab a copy with curl. For example:
$ curl --location --silent --fail --show-error --output ~/Downloads/ust.csv 'https://data.ct.gov/api/views/utni-rddb/rows.csv?accessType=DOWNLOAD'
$ wc -l ~/Downloads/ust.csv
49090 /home/josevnz/Downloads/ust.csvNext, I'll show how to import your data into your bucket and some issues you may encounter.
[ Download a sysadmin's guide to Bash scripting. ]
Import the data
It is a good practice to define what questions you can answer with the data before deciding what to import and what to ignore. Here are a few examples this tutorial will try to answer:
- Total number of tanks reported (active, inactive)
- Number of inactive tanks by installation time
- Number of tanks over type, grouped by substance type
- Number of tanks close to Hartford, Connecticut
Check the available columns and make a note of what to ignore during the import process to answer the questions you define.
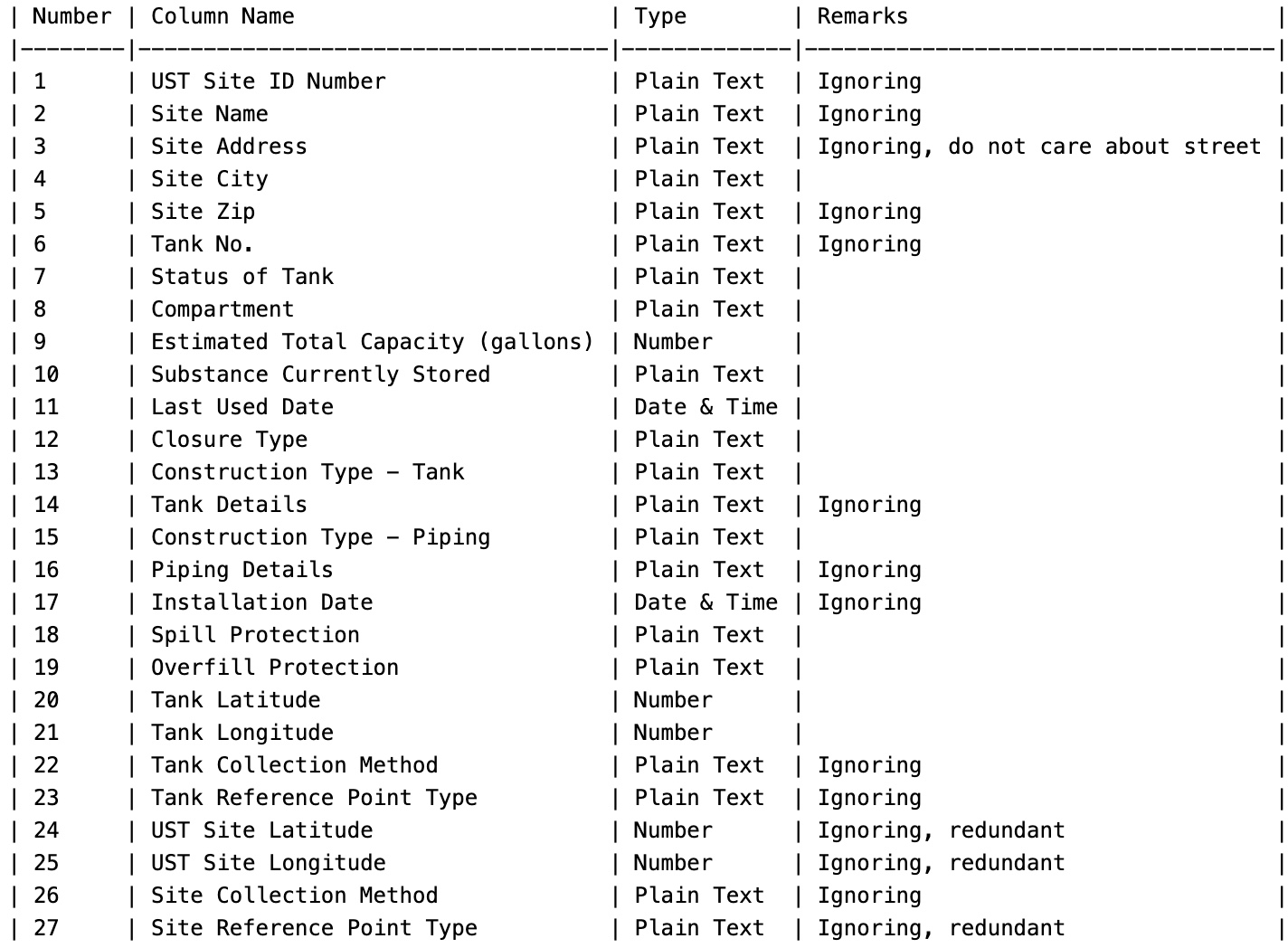
Take a peek at your data:
ST Site ID Number,Site Name,Site Address,Site City,Site Zip,Tank No.,Status of Tank,Compartment,Estimated Total Capacity (gallons),Substance Currently Stored,Last Used Date,Closure Type,Construction Type - Tank,Tank Details,Construction Type - Piping,Piping Details,Installation Date,Spill Protection,Overfill Protection,Tank Latitude,Tank Longitude,Tank Collection Method,Tank Reference Point Type,UST Site Latitude,UST Site Longitude,Site Collection Method,Site Reference Point Type
50-11456,Brewer Dauntless Marina,9 NOVELTY LN,ESSEX,06426,1,Permanently Closed,,4000,Gasoline,10/18/2018,Tank was Removed From Ground,Coated & Cathodically Protected Steel (sti-P3),Double Walled,Flexible Plastic,"Containment Sumps @ Dispensers,Containment Sumps @ Tanks,Double Walled,Metallic fittings isolated from soil and water",06/01/1999,Spill Bucket,Ball Float Device,41.350018,-72.385442,Address Matching,Approximate Location,41.350018,-72.385442,Address Matching,Approximate Location
106-1923,FOOD BAG #509,1652 BOSTON POST RD,OLD SAYBROOK,06475,D1,Permanently Closed,a,10000,Diesel,03/01/1998,Tank was Removed From Ground,Coated & Cathodically Protected Steel (sti-P3),,Rigid Fiberglass Reinforced Plastic,,02/01/1983,,,41.286115,-72.414762,Address Matching,Approximate Location,41.286115,-72.414762,Address Matching,Approximate LocationYou can use the InfluxDB bulk importers as your first take using the line protocol. This means you help InfluxDB digest the data as follows:
- Inform it what kind of measure you are taking.
- Choose the appropriate types for data types, like numbers, dates, or geographical coordinates.
- Choose what columns to skip.
Using CSV annotations is a way to go, but it has limitations on how much you can manipulate during the import process.
Then you must decide where and how to store the data. InfluxDB uses the concept of tags, fields, and measurements:
- A bucket is the database where the data will be stored.
- InfluxDB stores data into measurements (the equivalent of a table on relational databases). This one is fuel_tanks.
- Tags are a combination of keys and values used on indexes. Their values do not change over time. Think about them as metadata. In this case, the Substance Currently Stored and Closure Type are tags.
- Fields change over time and are not indexed. The Estimated Total Capacity (gallons) total is a counter that will change over time.
- Time is the fabric of the data and will be derived from the report period and not from the date updated fields.
Notice there are not one but two date-time columns:

And, like any time series, there can only be one dateTime column.
So what to do? Well, you can split the data into two buckets, depending on what you want to track, store one of them as a tag (useless as it makes it harder to use), or just ignore it completely.
For this analysis, you care more about the last-used date, so ignore the installation date.
How does that look for the data?
#constant measurement,fuel_tanks
#datatype ignore,ignore,ignore,tag,ignore,ignore,tag,tag,long,tag,dateTime:01/02/2006,tag,tag,ignore,tag,ignore,ignore,tag,tag,double,double,ignored,ignored,ignored,ignored,ignored,ignored
ID,Name,Address,City,Zip,TankNo,Status,Compartment,EstimatedTotalCapacity,SubstanceStored,LastUsed,ClosureType,ConstructionType,Details,ConstructionType,PipingDetails,InstallationDate,SpillProtection,OverfillProtection,Latitude,Longitude,CollectionMethod,ReferencePointType,USTLatitude,USTLongitude,CollectionMethod,ReferencePointTypeThe full command would look something like this (import_ust.sh):
$ /usr/bin/podman run --interactive --tty --volume "$header_file:/data/headers.csv" --volume "$csv_file:/data/tanks.csv" influxdb influx write "$dryrun" --bucket $BUCKET --org $ORG --format csv --skipHeader=1 --url "$url" --file "/data/headers.csv" --file "/data/tanks.csv"If you run it in dry mode, you will be able to see the line protocol used to import the data:
fuel_tanks,City=BRISTOL,ConstructionType=Flexible\ Plastic,OverfillProtection=Audible\ Alarm,SpillProtection=Spill\ Bucket,Status=Currently\ In\ Use,SubstanceStored=Gasoline EstimatedTotalCapacity=15000i,Latitude=41.65641,Longitude=-72.91408
fuel_tanks,City=Hartford,ConstructionType=Flexible\ Plastic,OverfillProtection=Audible\ Alarm,SpillProtection=Spill\ Bucket,Status=Currently\ In\ Use,SubstanceStored=Diesel EstimatedTotalCapacity=1000i,Latitude=41.75538,Longitude=-72.680618
fuel_tanks,City=BERLIN,ConstructionType=Flexible\ Plastic,OverfillProtection=Audible\ Alarm,SpillProtection=Spill\ Bucket,Status=Currently\ In\ Use,SubstanceStored=Gasoline EstimatedTotalCapacity=10000i,Latitude=41.646417,Longitude=-72.729937
...But even with this flexibility, there are times when you have to write a custom importer.
When the CSV annotation falls short
InfluxDB's write command is pretty flexible, but the data presents a few challenges that the tool cannot solve:
- The data in this set is not sorted by installation date. This will affect the performance of the queries, so you need to sort the data before inserting it. The Influx
writecommand assumes (rightfully) that the data comes in an ordered fashion. - The city is sometimes written in all caps but it's not consistent.
- Last-used date is missing in some data points. For this exercise, assume the last-used date equals the current date if the tank is still in use.
- Some decommissioned tanks only have the zip code but no coordinates. No problem; you will use uszipcode to get the latitude and longitude.
I wrote a custom importer script called import_ust.py to handle those cases with grace.
[ Want to test your sysadmin skills? Take a skills assessment today. ]
Run some queries
Finally, it's time to run a few queries.
Total number of tanks reported (active, inactive)
from(bucket: "USTS")
|> range(start: -100y)
|> filter(fn: (r) => r["_measurement"] == "fuel_tanks")
|> filter(fn: (r) => r._field == "estimated_total_capacity")
|> group(columns: ["status"])
|> count(column: "_value")
|> group(columns: ["_value", "status"], mode: "except")
|> sort(columns: ["_value"], desc: true)The result in the image below shows there are three categories: permanently closed, currently in use, and temporarily closed, and 25,831 permanently closed tanks in Connecticut.
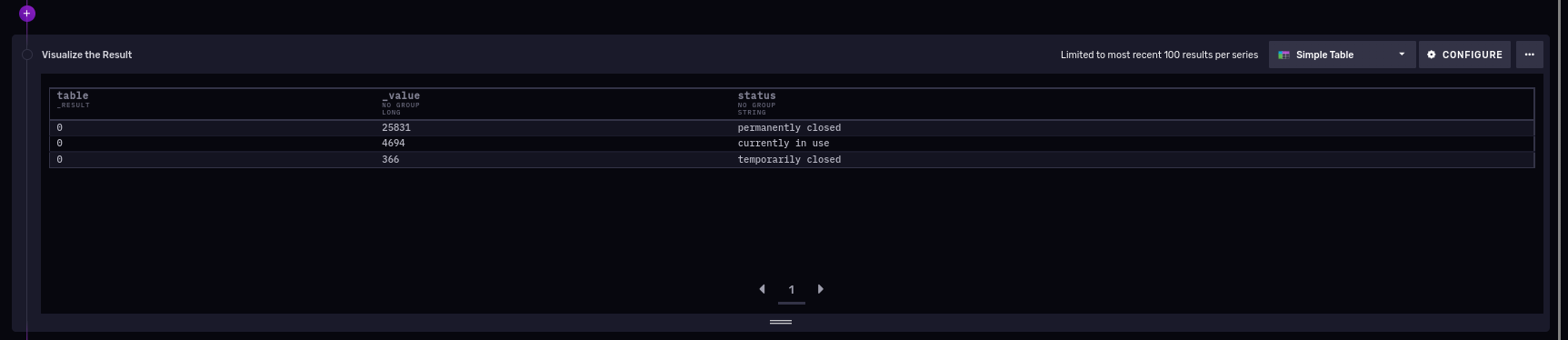
Number of closed fuel tanks all time, per city
So there are quite a lot of permanently closed tanks. Are they distributed differently over time?
from(bucket: "USTS")
|> range(start: -100y)
|> filter(fn: (r) => r._measurement == "fuel_tanks" and r._field == "estimated_total_capacity" and r.status == "permanently closed")
|> truncateTimeColumn(unit: 1y)
|> group(columns: ["city", "_time"])
|> count(column: "_value")
|> drop(columns: ["closure_time", "construction_type", "overfill_protection", "substance_stored", "s2_cell_id_token", "lat", "lon"])
|> group(columns: ["city"])This will generate a group of tables (towns) over time (use the truncateTimeColumn to drop the date and time granularity in the series data):
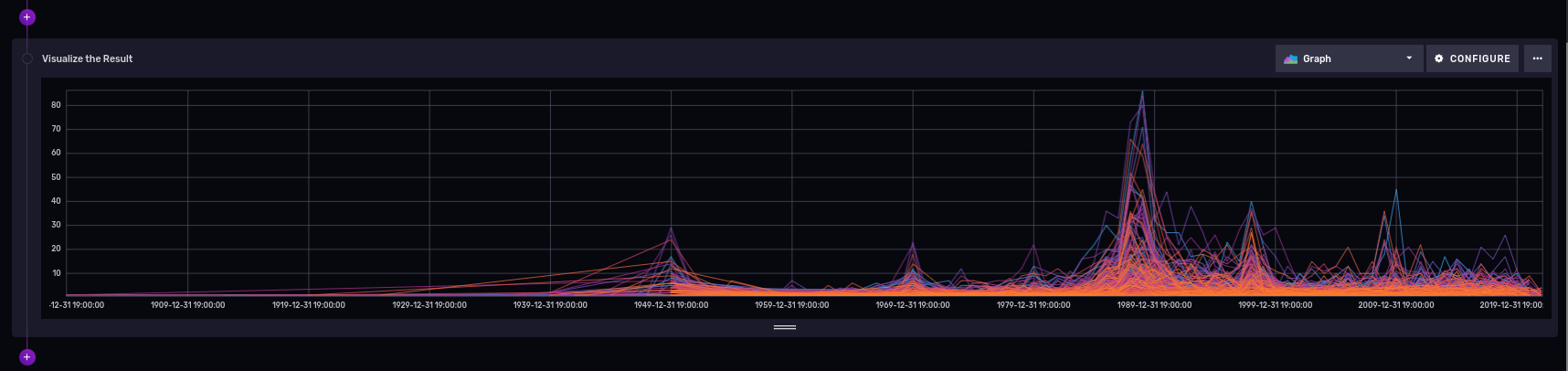
The graphic shows that the "winner" has 80 tanks.
[ Learn how to manage your Linux environment for success. ]
Number of tanks, grouped by substance type
Gasoline? Oil? Investigate what is currently in use over the last five years:
from(bucket: "USTS")
|> range(start: -5y)
|> filter(fn: (r) => r._measurement == "fuel_tanks" and r._field == "estimated_total_capacity" and r.status == "currently in use")
|> group(columns: ["substance_stored"])
|> count(column: "_value")
|> drop(columns: ["city", "closure_tipe", "construction_type", "overfill_protection", "s2_cell_id", "lat", "lon", "_time", "spill_protection", "status"])
|> group()
|> sort(columns: ["_value"], desc: true)And the results:

The results show that most tanks stored gasoline, followed by heating oil for onsite consumption, diesel, a nonspecified type, kerosene for resale, other petroleum, used oil, E15 fuel, heating oil for resale, hazardous substances, biodiesel, E85 fuel, and kerosene for onsite consumption.
Number of tanks close to Hartford, Connecticut
I'm using Influx 2.4.0, which labels native support of geolocation capabilities inside the database "experimental." But it is a very useful feature, so I'll explore it next.
If you want to take a quick look at the geolocation capabilities, you could run the following on a notebook:
import "influxdata/influxdb/sample"
import "experimental/geo"
sampleGeoData = sample.data(set: "birdMigration")
sampleGeoData
|> geo.filterRows(region: {lat: 30.04, lon: 31.23, radius: 200.0}, strict: true)First, a bit of geography. The Hartford, Connecticut, USA, latitude and longitude coordinates are 41.763710, -72.685097.
Count the tanks within a 30-mile (48.28 kilometer) radius of the Hartford coordinates over the previous five years:
import "experimental/geo"
from(bucket: "USTS")
|> range(start: -5y)
|> filter(fn: (r) => r._measurement == "fuel_tanks" or r._field == "lat" or r.field == "lon" and r.status == "currently in use")
|> geo.filterRows(region: {lat: 41.763710, lon: -72.685097, radius: 48.28032}, strict: false)
|> drop(columns: ["closure_time", "construction_type", "overfill_protection", "substance_stored", "s2_cell_id_token", "lat", "lon", "spill_protection", "s2_cell_id", "_time", "status", "closure_type"])
|> count(column: "estimated_total_capacity")
|> group(columns: ["city"])
|> group()
|> sort(columns: ["estimated_total_capacity"], desc: true)Here are the partial results:

This shows the number of tanks in the cities and towns within 30 miles of Hartford; there are 173 in Hartford itself.
Use other languages
You can also query the data using your favorite programming language. For example, here's the Python query I used to determine how many tanks per substance type are available for a given period:
from influxdb_client import InfluxDBClient
# You can generate a Token from the "Tokens Tab" in the UI
token = "pP25Y9broJWTPfj_nPpSnGtFsoUtutOKsxP-AynRXJAz6fZzdhLCD4NqJC0eg_ImKDczbMQxMSTuhmsJHN7ikA=="
org = "Kodegeek"
bucket = "USTS"
with InfluxDBClient(url="http://raspberrypi:8086", token=token, org=org) as client:
query = """from(bucket: "USTS")
|> range(start: -15y)
|> filter(fn: (r) => r._measurement == "fuel_tanks" and r._field == "estimated_total_capacity" and r.status == "currently in use")
|> group(columns: ["substance_stored"])
|> count(column: "_value")
|> drop(
columns: [
"city",
"closure_type",
"construction_type",
"overfill_protection",
"s2_cell_id",
"lat",
"lon",
"_time",
"spill_protection",
"status",
],
)
|> group()
|> sort(columns: ["_value"], desc: true)"""
tables = client.query_api().query(query, org=org)
for table in tables:
for record in table.records:
print(record)I'll tweak the Python code and make it better:
Not so bad. You can do the same thing in other languages, such as Java.
[ Get the guide to installing applications on Linux. ]
What is next?
- The Connecticut Open Data portal has many more interesting datasets you can download for free to learn about the state. You likely have similar portals with public data where you live.
- The Flux language is a more interesting choice than plain SQL for analyzing time-series data. I found it intuitive to use, but I'm still learning a few specifics.
- How fast is InfluxDB compared to other offerings? You need to decide for yourself. I haven't spent much time tuning settings. My initial interest was how easy it is to use and integrate with other applications, like Grafana.
- If you write scripts in Python, you should definitely take a look at the examples from the Git repository.
- And of course, check the source code in the repository for this tutorial.
About the author
Proud dad and husband, software developer and sysadmin. Recreational runner and geek.
More like this
Why platform engineering fails to scale: Product and adoption design in practice
The new reality of supply chain trust: Why platform-native security is non-negotiable
Heroes in a Bash Shell | Command Line Heroes
Open source for climate finance | Technically Speaking
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds