
In this article, I cover what I've learned about backing up data stored in a Red Hat Enterprise Linux (RHEL) virtual machine (VM). During my first year of working with Linux, I had the idea of backing up data on a Linux VM deployed in the cloud.
Backing up data is a major business issue. With an increasing number of cyber threats, user errors, and system failures, your data is not safe. Backing up data prevents the loss of important files and folders when there is a security breach, accidental deletion, or in the event of a system failure. Individuals and small-to-medium-sized businesses can backup data to external hard discs, or to backup servers, but for large enterprises where the amount of data is huge (Petabyte scale), data backup is complex and is often done, at least partially, on some form of cloud architecture.
[ You might also like: Taming the tar command: Tips for managing backups in Linux ]
Even though there are many ways to back up data, like backing up to on-premises data centers, some businesses choose the cloud for backup as it provides multiple ways to optimize storage. Using cloud features, you can select any location from around the globe for backing up the data. This feature is essential because if any single region faces a system crash or a localized natural disaster, you still have your data backed up successfully in another location.
Creation of RHEL virtual machines
First, you need to create a RHEL virtual machine. You can choose any cloud platform for that. The purpose of this article is to demonstrate a general technique, not the specifics unique to a given cloud provider. This virtual machine contains all your data.

After creating the VM, create another Red Hat virtual machine but in a different zone (geographic location). You'll use this virtual machine to store backed-up data.
You created two virtual machines in different zones because if one zone faces a failure or disaster, the virtual machine in that zone will be unavailable, but the remote duplicate VM is available.

Creating a volume
After creating the instances, create a volume and attach it to the instance you need to back up. A volume is a virtual hard disk attached to a virtual machine (VM) to increase its performance and reduce latency. Volumes are generally attached when you need to take a backup of the data stored in the VM.
You can create the volume in the cloud platform itself.

To create the volume, you must specify details like the size of the volume required and select the zone of the Red Hat instance of which you are creating the backup.
Attaching the volume to the Red Hat instance
After successfully creating the volume, you will now attach the volume to the Red Hat virtual machine.

Creating an SSH connection using PuTTY
Now, you will create a secure connection of the Red Hat instance with the local system by using PuTTY. PuTTY is an open source software that supports various network protocols like SCP, Telnet, SSH, etc. The connection is established using the public IP address of the Red Hat instance.
Mounting the volume on the VM
The volume that you created is just attached and not mounted on your Red Hat virtual machine.
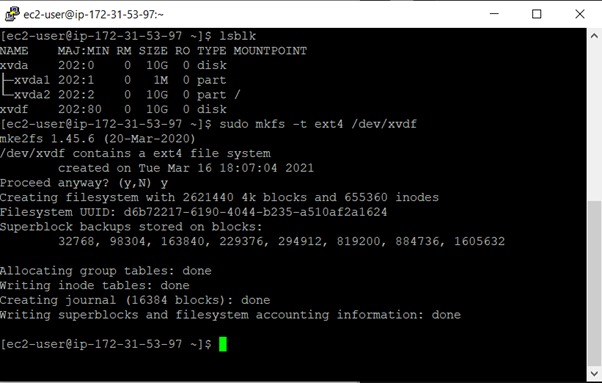
To find out the name of the attached volume, you can use the command lsblk. The lsblk command lists information for all the block devices present.

You will now format the volume using the command sudo mkfs -t ext4 /dev/xvdf, where xvdf is the name of your volume.
After formatting the volume, mount the volume on your Red Hat virtual machine.
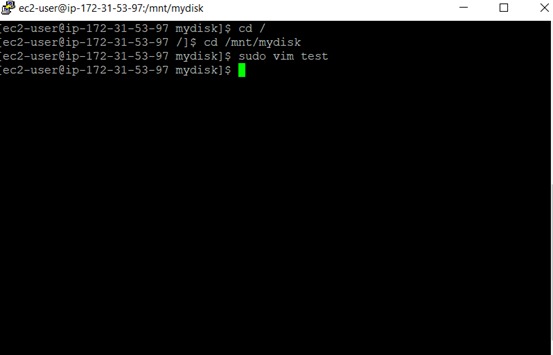
First, create a directory in your instance. You can do this by using the following command:
$ sudo mkdir /mnt/mydisk
You will now mount the volume in the directory named mydisk using this command:
$ sudo mount /dev/xvdf /mnt/mydisk

Creating a file inside the volume
Create a sample file in the volume which is present in the directory mydisk.
The command to create a file in the volume is sudo vim test, where test is the name of the file. Write something onto the file and store it as the data which you want to back up.
To summarize, a volume was created and then attached to the instance. You then mounted the volume on the instance. Next, you created a sample file in the volume that contained the data.
Now, unmount the volume from the instance.
The command to unmount a volume from an instance is:
$ sudo umount /mnt/mydisk
Creating a data backup
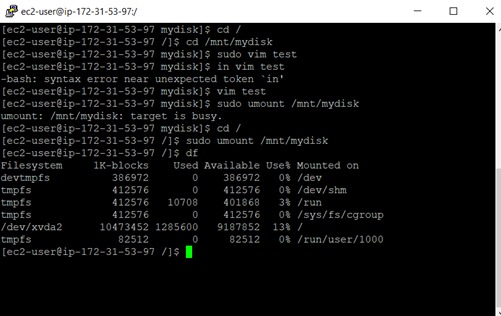
The main thing here to note is that the volume is still attached to the instance but not mounted on the instance.
The next task is to attach the volume to the backup instance. But the volume cannot be detached directly from the current instance and attached to the backup instance as both the virtual machines are present in different zones.
First, create a snapshot that will be associated with the volume created previously.
Snapshots are the storage used to back up the data stored in the volumes. You can create snapshots through the cloud portal used by the user.
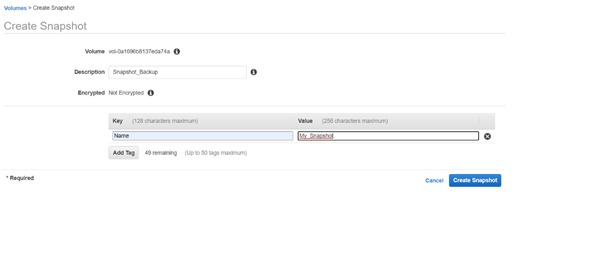
After creating the snapshot, you will detach the volume. After that, it is deleted from the instance, as volumes are much costlier than snapshots. This is because snapshots are simple storage services. Also, a volume can easily be created from the snapshot whenever required.
Now, create a volume from the snapshot that you created previously. You will attach this volume to the instance that would back up the data.
The steps for creating and attaching a volume to an instance will be the same as mentioned above.
Next, connect PuTTY with the backup instance using the public IP of the instance.
Using the lsblk command, you can check that a volume is attached to the instance but not mounted on the instance.
Before mounting the volume on the instance, you need to format it as it did not have a filesystem. There is a need for formatting as the volume is created from the snapshot, which already has a filesystem.
Finally, mount the volume on the instance.
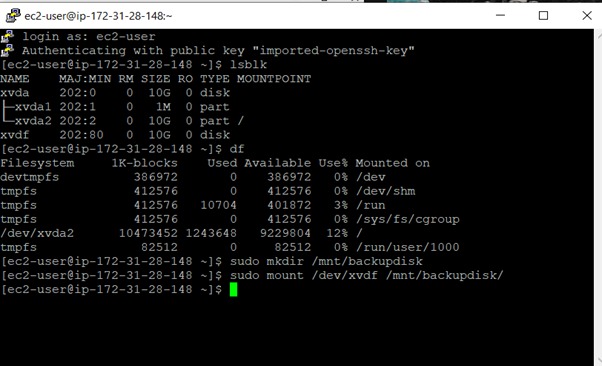
This volume is mounted onto the directory named backupdisk.
Go inside the backupdisk directory and check whether your test file is present. This is the file you created earlier in the volume attached to the Red Hat instance.
You need to check whether the sample test file that you created earlier in the volume attached to the Red Hat instance was successfully backed up to the backupdisk directory present in the backup instance. The command to do so is:
$ ls -ltr
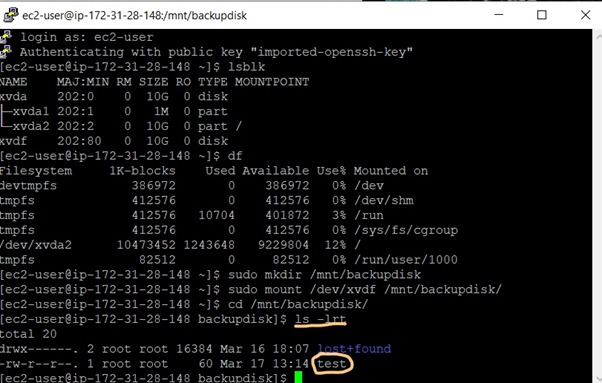
Thus, you can see that the test file is still present and was backed up successfully.
To check whether the file's contents were also backed up successfully, type the following command to display the file contents:
$ cat test
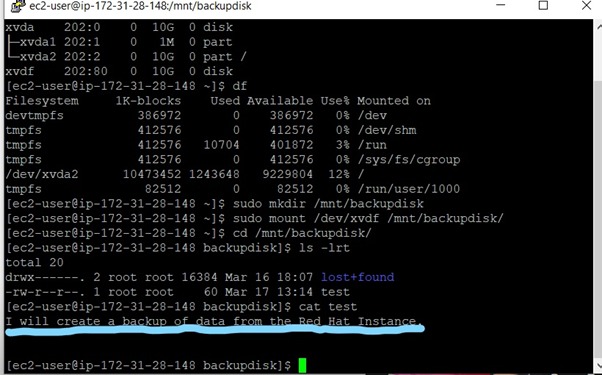
The data was also backed up.
[ Getting started with containers? Check out this free course. Deploying containerized applications: A technical overview.
Wrap up
This article explains why backing up data is essential to business continuity. Some businesses and organizations with a huge amount of data back up their data to a cloud platform as it provides multiple options for optimization such as deduplication, compression, encryption, and geographic diversity.
I provided steps for backing up the data stored in a VM in one zone to a second instance in a different zone. This ensures data redundancy, and if one system fails or there is a disaster in one zone, the user's data is safe and available in the other zone.
About the author
Saksham is currently pursuing his Computer Science undergraduate degree from the University of Petroleum and Energy Studies, Dehradun, Uttarakhand. He loves exploring new technologies and he believes that practical knowledge is the best form of learning. He has a keen interest in Cloud Computing.
Saksham loves to code and has good knowledge of C, C++, and Java programming languages. Other than this, he has also given tech talks and has mentored more than 800 students.
More like this
Provide access to Red Hat documentation in environments with limited connectivity
BackendTLSPolicy expands Gateway API transport security
Infrastructure At The Edge | Compiler
Operating System Management | Compiler
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds