
A network flow is the accumulated metrics (such as the number of packets or bytes) of the packets that pass a given observation point and share common properties (protocol, source/destination address, and port). OpenShift Network Observability is a tool that allows collecting, storing, and visualizing OpenShift clusters' network flows.
[ Want more on this topic? Watch the full session, Use of eBPF in OpenShift network observability, on-demand from Red Hat Summit. ]
Initially, we relied on the OVN-Kubernetes Container Network Interface (CNI) that can export flows in the IPFIX format (a binary format to efficiently export flow data). We provided a flow collector that ingests IPFIX data and decorates it with metadata from OpenShift (such as Names and Namespaces). Finally, the collector stored the flows as JSON in Grafana Loki so that we could retrieve and visualize them from our OpenShift Console plugin (or directly from Grafana).
However, requiring OVN-Kubernetes as the OpenShift cluster CNI limits the size of our potential user base. In addition, the asynchronous deployment of the flow senders and collectors could lead to synchronization problems with how IPFIX shares the templates.
To overcome such limitations, we are implementing our own portable network-flow exporter that is designed to be ubiquitous and optimized for Kubernetes observability use cases.
The network observability eBPF Agent
Our goal is to create an alternative to IPFIX that is portable, usable by most CNIs, and fits better into OpenShift's operational specifics. We chose eBPF because it is available in any recent Linux kernel (version 4.18 or higher).
eBPF provides a virtual machine that can be attached to different places on the Linux kernel and safely executes sandboxed programs to extend or observe its functionalities. eBPF also provides mechanisms to communicate kernel space with user-space programs.
[ Get this free eBook: Managing your Kubernetes clusters for dummies. ]
For example, our agent loads a small eBPF traffic control program attached at the ingress and egress of all the network devices (physical and virtual). This kernel-space program inspects the headers of all received and submitted packets, then forwards them serially to the user-space code through a ring buffer. This operation is performed with safety guarantees due to the pre-verification steps of the eBPF virtual machine.

The user space agent aggregates in memory the quantitative information of each packet to compose the actual flows and periodically forwards them to the flow collector, as defined in the IPFIX scenario.
Now, users can choose between OVN-Kubernetes or eBPF traffic inspection with no differences in the overall functionality.
Implementation and performance considerations
Communication between the kernel and the user space is relatively slow, as each packet message wakes up the user-space program. However, using the ring buffer and implementing all the aggregation logic in the user space (using Cilium's Go eBPF library) provides a quick implementation to start validating the feasibility of eBPF in diverse scenarios.
[ Try this learning path to understand how to create a cluster in Red Hat OpenShift Service on AWS with STS. ]
To test the performance, we ran multiple traffic generators sending small User Datagram Protocol (UDP) packets to a 16-vCPU AWS instance running the following components:
- The eBPF Agent
- A dummy flow collector that reports the total number of processed packets
- Several UDP traffic receivers
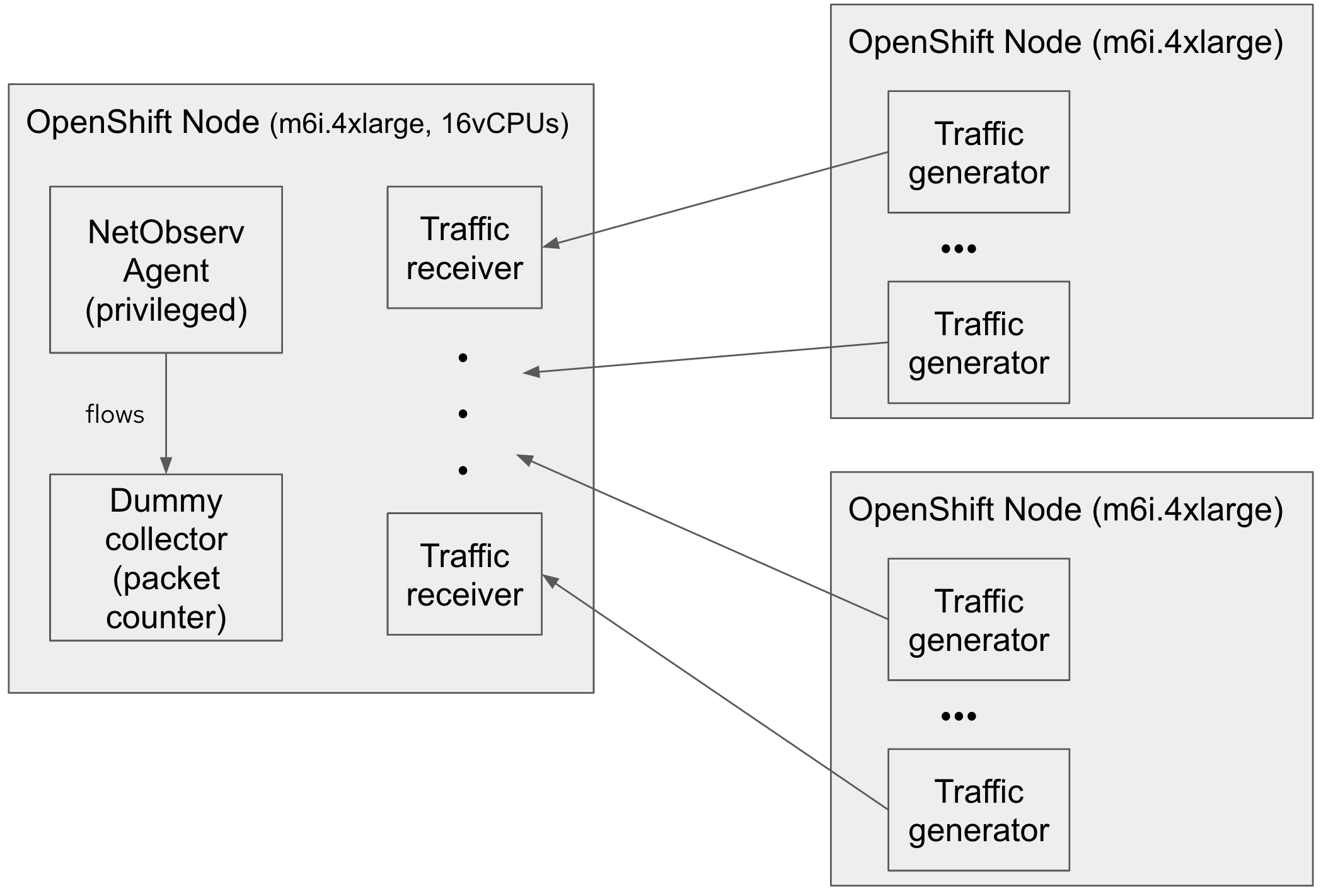
The eBPF Agent is able to process up to 1 million packets per second at an almost-linear cost of around 200,000 packets per second per half CPU.
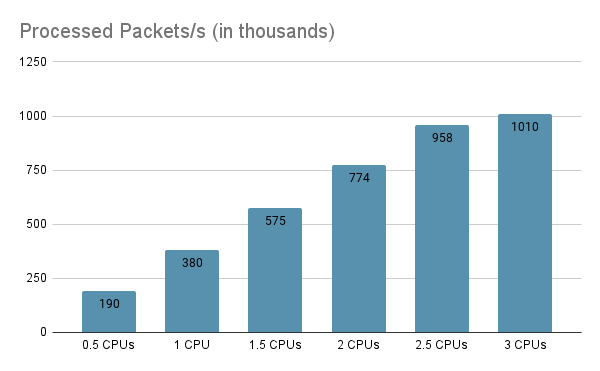
Tuning the Go garbage collector allowed us to increase the number of processed packets by 20%.
Future work
The first release of the eBPF Agent focused on correctness, portability, and time to market.
However, despite the eBPF Agent working well in environments with low-to-average network load, it might consume too many CPU resources in environments with very high traffic.
[ Free download: Advanced Linux commands cheat sheet. ]
Consequently, we spotted some future work lines to minimize the agent's footprint.
One candidate for evaluation is sampling the ratio of wakeup events in user space. Ideally, instead of waking up the user space for each packet, it would allow a set of packets to accumulate and then wake the user space. Some reports claim a five-fold performance improvement using an eBPF perf buffer (we use a ring buffer, which is slightly different).
During the upcoming months, we will work on moving the aggregation of the flows from the user space to the kernel space and communicate both user and kernel space with hash maps:
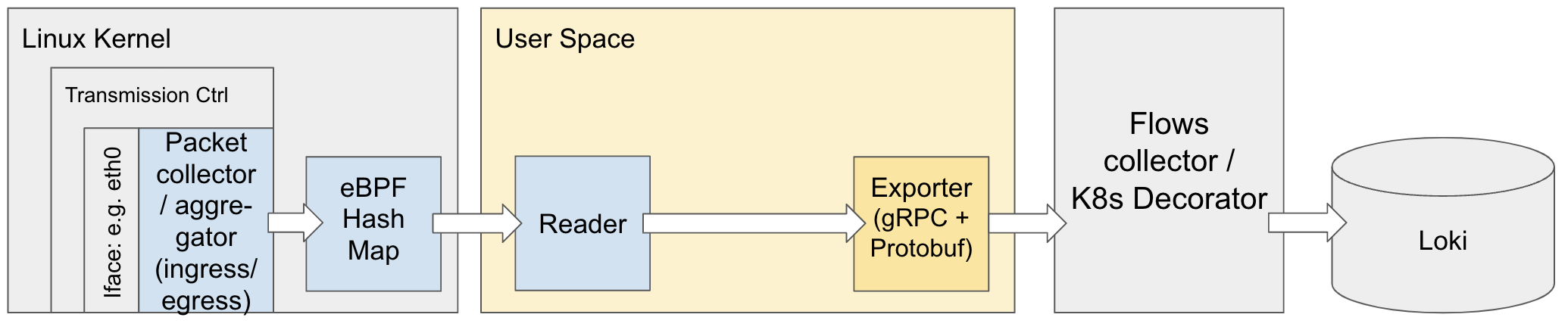
Some initial experiments show that the number of processed packets could increase by around 20% to 30% and the CPU consumption could be reduced by 90%.
Related work
There are many other open source eBPF Agent implementations freely available, like Cilium, Pixie, and Skydive. Instead of reusing them, we decided to start our own implementation from scratch because the previous agents are part of larger solutions, and it is complex to isolate the code and only reuse the eBPF flow extraction parts. Also, many of them rely on old or outdated eBPF tools that are difficult to compile or port to current operating system distributions.
Wrap up
The eBPF Agent is demonstrated to be a feasible alternative to the OVN IPFIX collection, as it keeps the full functionality of OpenShift Network Observability for users not yet using OVN-Kubernetes.
We created an initial test eBPF Agent with the following principles in mind:
- Ubiquity: The agent can be executed inside pods but also as a Linux process.
- Portability: We target the latest Compile-Once Run Everywhere (CO-RE) implementations of eBPF, so the agent is distributed as a binary file.
- Flexibility: The eBPF Agent can run standalone. Its export protocol (based on GRPC+Protocol buffers) is open, and we provide example implementations so others can use it in their systems.
The agent was able to validate multiple scenarios but at the cost of high performance. Despite this, performance would likely be satisfactory on OpenShift clusters with a moderate workload. According to our initial investigations, we expect to reduce the CPU load of the eBPF Agent by one order of magnitude.
For more insight on this topic, watch our presentation from Red Hat Summit 2022, Use of eBPF in OpenShift network observability (video available until December 2022).
About the author
Mario is a Senior Software Engineer at Red Hat. After working 10 years as a researcher and teacher in academia, Mario started to work in the observability field and has spent most of that time creating agents for the extraction of monitoring data from operating systems and service platforms.
More like this
Gain stronger pod isolation on Microsoft Azure Red Hat OpenShift with OpenShift sandboxed containers
Achieve high scalability using Red Hat Satellite Capsule Server
Scaling with Orchestrators | Compiler
Container Roundup | Compiler
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds