
[ Editor's note: There are known limitations to CPU pinning in some environments, so be sure to read about the details of your environment before following this tutorial. ]
CPUs run all applications and it's best if you understand how it works and how you can tune CPU usage to increase the performance of your applications.
Modern systems typically have multiple CPUs and cores, which are shared among all running software by the kernel scheduler. So normally, you're not bothered about which CPU/core your application or process runs, as long as it runs.
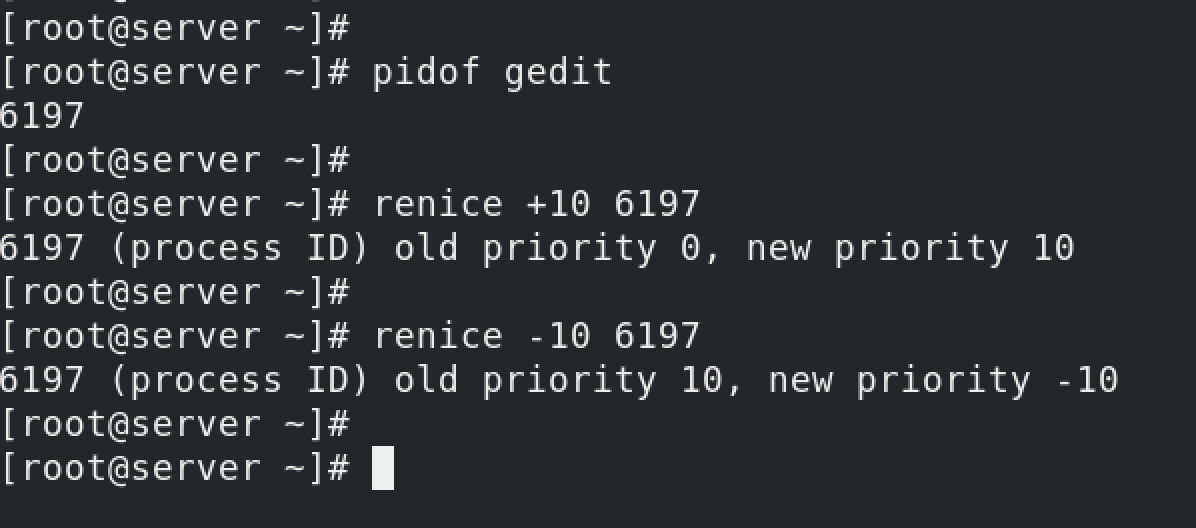
There are multiple ways to get more CPU and make your application work better and run more efficiently. One way is to use priority tuning using the nice/renice command.
[ You might also like: The central processing unit (CPU): Its components and functionality ]
The second way is to bind the application to one or more CPUs, called “CPU pinning” or “CPU affinity.” Binding the application to a specific CPU or CPUs makes all the threads or child processes related to the application running on defined CPU/CPUs. This way, limiting the process/application to one or more CPUs results in more "cache warmth" or "cache hits, " thus increasing overall performance. The first benefit of CPU affinity is optimizing cache performance. The second benefit of CPU affinity is if multiple threads are accessing the same data, it makes sense to run them all on the same processor—helping us minimize cache misses.
Method 1 - priority tuning
Changing the priority of the process using a nice command. This is perhaps the most common way known to improve application/process CPU usage.
Unix has always provided a nice() system call for adjusting process priority, which sets a nice-ness value. Positive nice values result in lower process priority (nicer), and negative values—which can be set only by the superuser (root)—result in higher priority.
The nice value is still useful today for adjusting process priority. Your task is to identify low-priority work, which may include monitoring agents and scheduled backups, which you modify to start with a nice value. You can also perform analysis to check that the tuning is effective and that the scheduler latency remains low for high-priority work.
How does it work?
Every process is given a specified amount of time to run on the CPU. The actual time for which the process is running on the CPU is called the virtual runtime of the process. By the way, the CPU tends to act like a father and has a habit of dividing time equally among all children (the processes).

The total time a process spends “on CPU” is the virtual runtime of the process. The operating system (OS) keeps a record of this virtual runtime and tries to give equal time to all processes in the run queue.
The nice and renice utilities manipulate this virtual runtime.
When you feed positive values with renice/nice commands, for example - renice +10 PID, you're manually adding more virtual runtime to the process. The OS thinks that the process has taken more virtual runtime time than other processes in the run queue. So in the next cycle, the CPU gives less time to the process. The process finishes late as it’s getting less time “on CPU” now, after the renice command.
But when you feed negative values with renice/nice commands, for example - renice -10 PID, you're manually reducing the virtual runtime of the process. The OS thinks that the process hasn’t got enough “on CPU” time than other processes in the run queue. So in the next cycle, the CPU gives more “on CPU” time to that process as compared to other processes in the run queue. The process will finish fast.
Method 2 - process binding
A process may be bound to one or more CPUs, which may increase its performance by improving cache warmth or cache hits and memory locality. On Linux, this is performed using the taskset command, which can use a CPU mask or ranges to set CPU affinity.
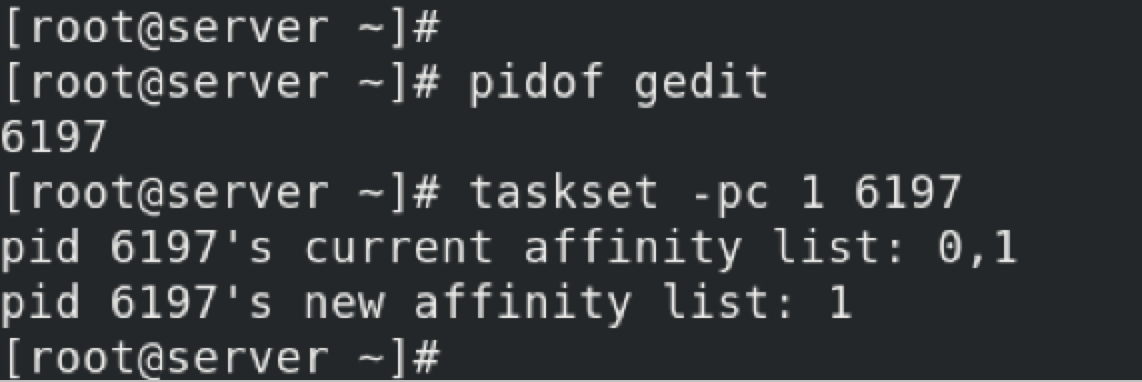
Using the taskset, you had bound the process 6197 to run only on CPU 1. This will result in more cache warmth/cache hits. Other processes can also run on CPU 1, but the process runs only on CPU 1 and CPU 2. This configuration is not permanent. If the server gets a reboot or the process is restarted, the PID will change. So this configuration is lost.
A better way is to use a “drop-in” file.
Method 3 - CPU affinity via drop-in file
As per Wikipedia, Processor affinity, or CPU pinning or “cache affinity”, enables the binding and unbinding of a process or a thread to a central processing unit (CPU) or a range of CPUs, so that the process or thread will execute only on the designated CPU or CPUs rather than any CPU.
Normally, it’s the kernel that determines the CPUs a process runs. Every time the scheduler reschedules a process, it can go to any of the available CPUs. While this is fine for most workloads, sometimes it's desirable to limit which CPU(s) a process is allowed to run. For example, limiting a memory-intensive process to just one or two CPUs increases the chances of a cache hit, thus increasing overall performance.
How does it work?
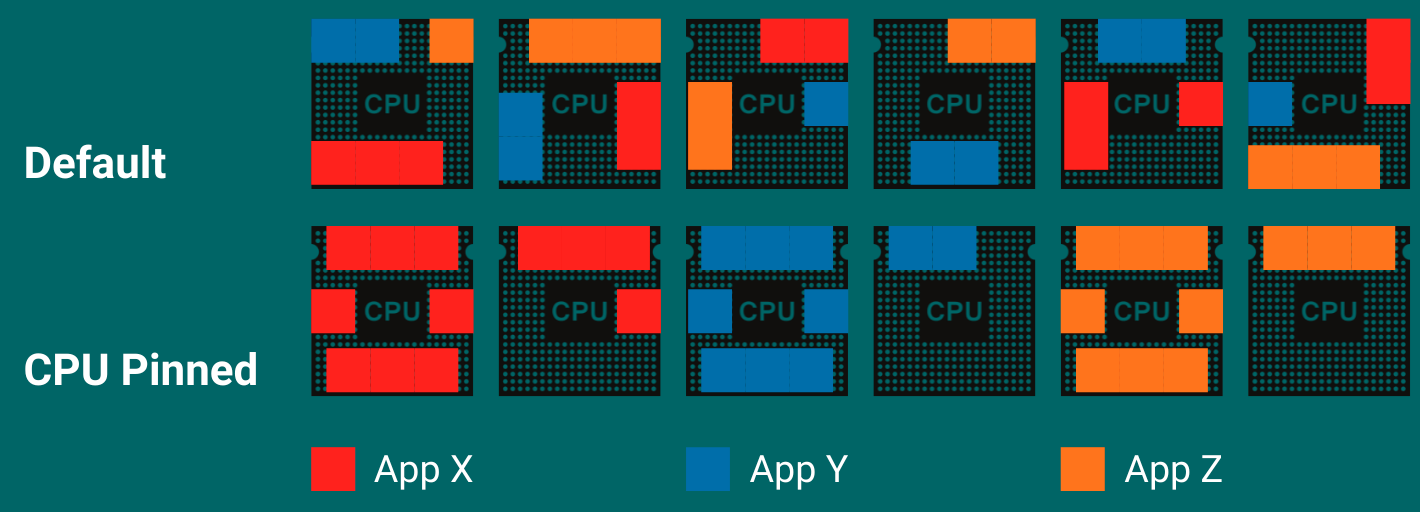
Pictured here, you have three applications: X, Y & Z. The default behavior of the scheduler is to use all the available CPUs to run the threads of applications X, Y & Z. Using the default settings, you can see that you'll get a good number of cache misses as the application is spread across all CPUs. Which leads to fewer cache hits and more cache misses.
When the applications are pinned to specific CPUs, they're forced to run on specific CPUs thus using CPU cache more effectively—more code on the same CPU. Doing so results in more cache warmth/cache hits and thus a better performing application.
To explore how you can use CPU pinning/CPU affinity to bind a process to certain processors, pin the sshd process to CPU 0.
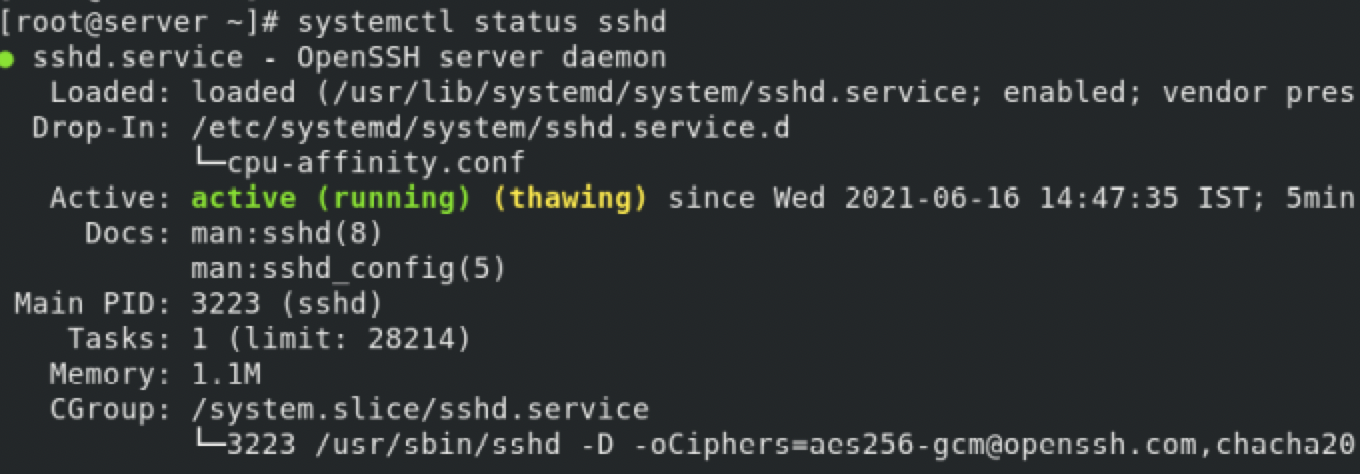
Check the current status of the sshd service. You're checking which CPU it binds to.
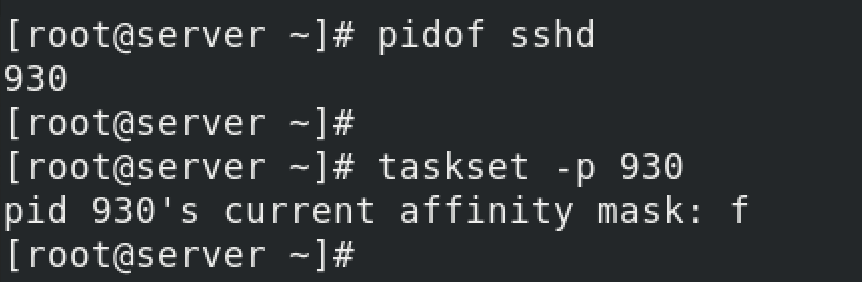
According to the taskset command man pages, value f means "any CPU." So there's no CPU pinning or binding configured for sshd service.
Bind the sshd service to CPU 0—creating a drop-in file that you'll use to control the behavior of the sshd service. The drop-in file controls many things related to a process, but currently, you're limiting yourself to CPU pinning/affinity.

You can see how the taskset command is showing the CPU as "1", which according to the taskset man page is the first CPU available.
You can further confirm the drop-in file by checking the status of sshd service.
Wrap up
You can use either nice or renice to change a process's priority. Both the nice and renice commands can manipulate the “virtual runtime” of the process. So, based on the values, the process spends either more or less time on the CPU.
You can bind/pin a process to one or more CPUs. This increases the chances of more cache warmth/cache hits thus resulting in a much better performance. You can use the taskset command-line tool for this purpose. But the effect is only temporary. If you want the configuration to be persistent, you have to use a "drop-in" file.
[ Free online course: Red Hat Enterprise Linux technical overview. ]
About the author
Alok Srivastava is a founder member of Network Nuts, a Red Hat training and certification partner in India. He is a RHCA/RHCI and specializes in Red Hat Linux, Ansible, Openshift, Kubernetes, cloud platforms, and IaC tools like Terraform.
He has over 25 years of experience in Linux consultancy. He also has a youtube channel - networknutsdotnet (networknutsdotnet), where he loves to share technical stuff in Red Hat Linux, Automation, Cloud, and Containers.
When he's not working, he can be seen riding his Harley Davidson.
More like this
How Red Hat solves the toughest challenges in agentless infrastructure scanning
An introduction to the vi editor
Infrastructure At The Edge | Compiler
Operating System Management | Compiler
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds