
Before containers, deploying applications often included a series of library and binary file dependencies. These application dependencies had to be managed on each machine. If any system had a slightly different PATH setting or required different versions of dependencies, it could spell disaster. If you have ever deployed an application that was dependent on a particular version of Java or relied on a specific library, you know ensuring that those libraries are consistent across your development, QA, and staging environments is difficult. With containers, while different applications share the same host and even the same kernel, your application ships with all of the specific binaries and libraries that are required. This greatly simplifies the deployment process and prevents you from running into the "it worked on my machine" problem of application deployment. In addition, the reduced overhead of container deployment compared to that of a virtual machine (VM) speeds the automated testing workflow.
With that in mind, it is important for architects to learn the nuances of container ecosystems. Kubernetes is the most prominent container orchestration system. Orchestration is somewhat analogous to a virtual machine hypervisor, but in practice, it is very different. With Kubernetes, there are key differences with storage, networking, and security that you need to understand to have successful deployments.
1. Reimagine storage needs
Storage is the first thing I like to talk about with customers when discussing Kubernetes architecture. A frequent comment is that containers are cattle and not pets. Unlike VMs (or pets), which are named and actively managed, containers come and go as needed by application deployment cycles. Containers are ephemeral, which means they are disposable. Containers may be recreated due to software or hardware faults or by design, such as part of a deployment process. This type of architecture works wonderfully with stateless applications like web servers and cache servers. However, it can be a challenge for stateful applications like database containers that require their storage and state information. Kubernetes does provide persistent volumes (PV), which allow you to mount volumes as container storage. Typically these volumes are presented in the form of NFS shares to the cluster.
In addition to persistent volumes, Kubernetes allows you to define storage classes. These classes delineate solid-state and hard disk tiers or different types of cloud storage. Note that many traditional enterprise storage features, such as disaster recovery and backup, are not built into the Kubernetes cloud offering. That is not to say they cannot be implemented, but you may benefit from complete solutions like OpenShift to manage those functions.
2. A shift in the network topology
Networking is a second architectural challenge for an architect unfamiliar with Kubernetes because they risk comparing it to traditional networking paradigms. Networks in Kubernetes are different and require a new perspective to take full architectural advantage of them.
If we step back and think of the basic architecture of Kubernetes, we start with the deployment of pods, which are the smallest unit of measure. Pods consist of one or more containers. This all seems simple until you reach the crux: Each pod gets its own IP address. That means containers share an IP across the pod, which can have fantastic benefits as we design for side-cars and other architectural additions.
Kubernetes does impose the following network requirements:
- All pods on a given node can communicate without the use of Network Address Translation (NAT).
- Agents running on a node (system daemons, kubelet) can communicate with all pods on a node.
- Pods in the host network of a node can communicate with all pods on all nodes without NAT.
- You can use networking tools to segregate network traffic as needed for security purposes.
Conceptually, this maintains the same model to allow for easy transitions of workloads from virtual machines—if your application connected to an IP address in a VM, it still connects to an IP address for your pod. Additionally, you can define services that will provide a persistent IP address for a specific service. Services can act like a software load balancer, which provide a constant service name and target port for a pod or set of pods.
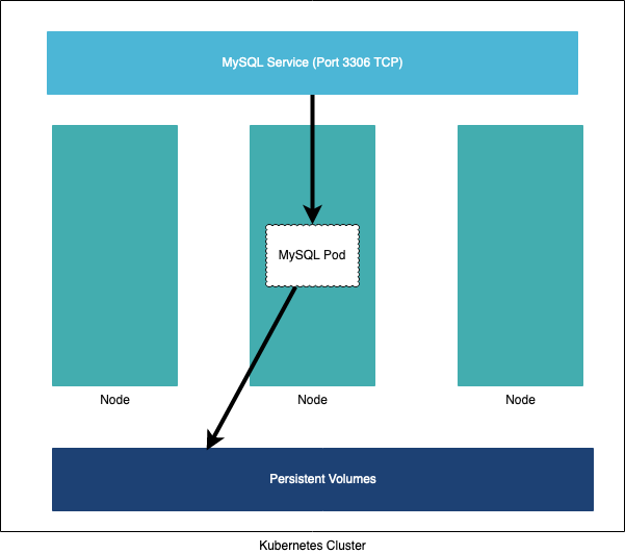
You can see a sample architecture using persistent volumes in the above diagram. A service is defined for MySQL—that is a persistent IP address used to connect to the MySQL pod over port 3306. The MySQL pod is defined with a persistent volume where its database and log files are stored. If the pod fails for whatever reason, the service will allow you to connect to the newly-created pod, which will also start with storage attached so that the database stays in a consistent state.
3. New ways of thinking about security
Kubernetes has a four-layer, defense-in-depth security model. The four layers are:
- The physical servers (at a data center)
- The Kubernetes cluster itself
- The individual container
- The source code running in a container
The first layer is the base of the security model—if your data center is unsecured or your cloud service is configured in an insecure way, all of the layers below that cannot be trusted. This means your Kubernetes API Server (also known as the control plane) should not be accessible to the Internet, or at the most only to the specific IP addresses
that need to access. Kubernetes stores its data in etcd key value store—this data store should only be accessed by the control plane, and you should encrypt the disk of the data store at rest and in transit using TLS.
Within Kubernetes, there is a role-based access control (RBAC) model for managing access to the API. You can set the scope of this RBAC to the cluster level or scope them to namespaces. Namespaces are used as a grouping mechanism but can also be a security boundary. It is also important to limit what privileges your containers run with—many containers run as root and can allow for dangerous host access with malicious code. You can also control what kernel modules are loaded—Kubernetes allows for a deny list to be created to prevent specific modules from being loaded into a container. Furthermore, just like any other system, you must ensure that you have proper network segmentation in place. For example, only application pods can talk to database pods to reduce the surface area for a malicious attack. Finally, you should ensure that your source code does not contain any secrets that could be found and abused.
New ways of thinking
Containers provide many benefits, the biggest being an increase in development velocity. There is much to consider at all layers from an infrastructure perspective due to how much changes with Kubernetes. Storage and networking are reworked in important ways, as detailed above. However, security becomes far more complex, in my opinion, and has many, many layers. Perhaps the most critical part of this is that all of your infrastructure is defined in code, which is a good and bad thing. Good because it's easier to change, bad because changes can easily slip in. Like any good development team, it is important to have code review and automated testing to ensure your environment's desired state.
Keep learning Kubernetes as it continues to evolve, and I would be interested in reading your architectural considerations in the future.
About the author
Joseph D'Antoni is an Architect and Microsoft Data Platform MVP with over two decades of experience working in both Fortune 500 and smaller firms. He is currently Principal Consultant for Denny Cherry and Associates Consulting. He holds a BS in Computer Information Systems from Louisiana Tech University and an MBA from North Carolina State University. He is a frequent speaker at PASS Summit, TechEd, Code Camps, and SQLSaturday events.
More like this
Why Operational Resilience and Digital Sovereignty Top the CIO Agenda
How Red Hat OpenShift 4.22 impacts enterprise AI’s bottom line
Crack the Cloud_Open | Command Line Heroes
Edge computing covered and diced | Technically Speaking
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds