


Network latency is the time it takes for a data packet to traverse from source to destination. In Gandalf-level wisdom, that is the time between now (where you are) and then (the inevitable end that will serve you).
[ Learn more about edge computing for telecommunications. ]
Certain factors impact latency on the network fabric, such as the physical distance between the source and the destination or the number of hops and their contributions to time passing. The network fabric has algorithms in place to find the most optimal data paths that will overcome (or at least minimize) the overhead brought by intermediaries. However, there's no way to overcome the physics of nature to shorten the actual distance or increase the speed of communication beyond certain limits (such as the speed of light).
Therefore, the location of the consumer who initiates the transmission is critically important. Fortunately, 5G provides better control over where you deploy applications (edge computing) and how consumers can reach them (edge applications) for better and more performant ways of achieving low latency.
This article presents a way to observe network latency on variable points of origin due to changing consumer-service locations. This knowledge can guide where you place workloads based on traffic demand and varying traffic origin locations to deliver better consumer experiences.
[ Ensure consistency and scalability at the edge by automating the last mile. ]
How latency affects consumer experience
Due to the 3rd Generation Partnership Project's (3GPP's) introduction of service-based architecture (SBA) and selection and enablement of local breakouts, consumer traffic can be routed from general packet radio service (GPRS) tunneling protocol (GTP) overlay fabric and reach the desired destination (such as consumer or enterprise applications) in practical ways. This approach enables you to realize low-latency communications in the real world with edge computing.
There are several reasons consumer experience from changing latency can vary over time:
- Nomadic access, or users changing their locations, causes mobile coverage to vary for signal strength, network load, and physical distance to the consumed application location.
- Ever-changing traffic patterns due to location-specific factors such as nature (rain, storms), increasing population (more users per cell), physical environments (more buildings), network fabric loads, and availability.

Enterprise architects encounter dynamic latency measurements in application schedulers and assigned user service locations. Architects are in charge of the user experience and can manage it based on continuously collected data. Data provides information about latency and can help create insights into the state of an end-to-end 5G solution for scalability, availability, and resiliency.
[ Learn why open source and 5G are a perfect partnership. ]
Measure latency
Our solution gathers latency metrics for each 5G platform with two views:
- Picking the right serving location based on the user's actual or predicted geolocation at a given time
- Creating an alternative serving location list based on changing underlying platform conditions
We partnered with Ddosify, a platform built for measuring the distributed computing latency on a global scale and load-testing the API endpoints. Ddosify offers three options for various use cases:
- Ddosify Engine is an open source, lightweight, high-performance load generator designed for single-pane-of-view load testing.
- Ddosify Checker is a DevOps tool capable of measuring the latency of an API endpoint across 25 countries.
- Ddosify Cloud combines these two tools (Engine and Checker) on the same platform. It is a distributed observability platform created for geotargeted latency and load testing of the API endpoints with continent-, country-, state-, and city-level breakdowns.
We leveraged Ddosify Cloud to dynamically (with variable points of origin) measure latencies across multiple 5G edge platform locations for programmable edge (API) endpoints, observing their state of availability.
How to use latency data
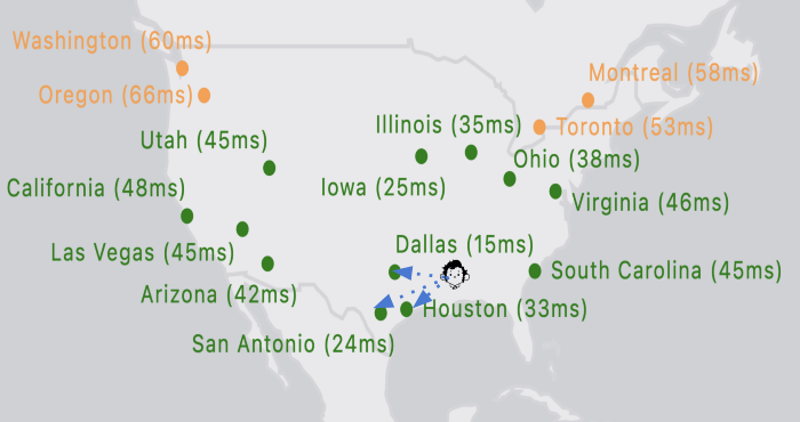
We measure 5G edge platform API access latency with respect to the request origination's location versus the servicing locations. Based on the observed measurements above and the users' current locations, we see they will be better served with low latency in the following locations (in order):
- Dallas: 15ms
- San Antonio: 24ms
- Houston: 33ms
As traffic origination point(s) get close to the 5G edge platform, the 5G experience will get better. As they go away from 5G edge platforms, latency will increase. However, users might get better latency from other 5G edge platforms depending on the direction of their journey and their speed.
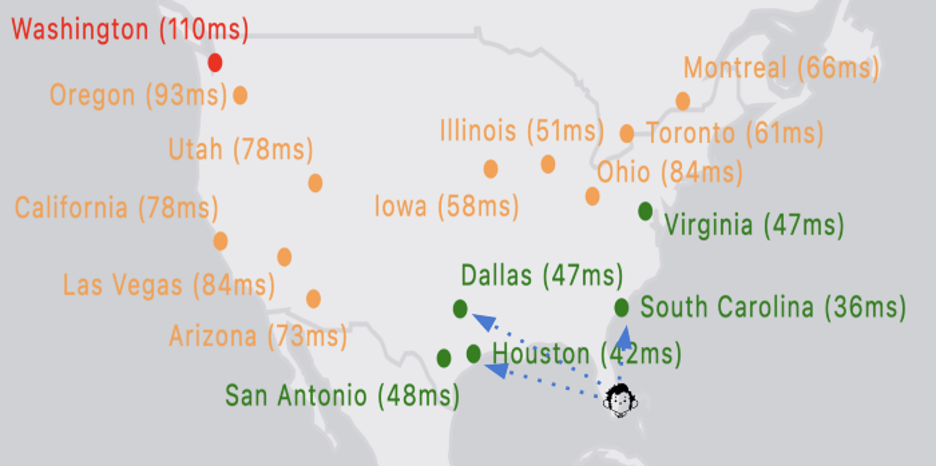
Without a 5G infrastructure, you can still be served by the closest edge location with a possible low latency thanks to the fiber backbone between states.

Latency grows based on distance, right? Yes and no. Yes, it does, but you aren't necessarily jailed by that limitation. You can create a molecular edge platform replicator (a "hub cluster to rule 'em all") that can clone your edge infrastructure. You can also use it with a single entry point by combining the power of Red Hat Advanced Cluster Management (RH-ACM) with the strength of Anycast IP for your distributed edge platforms.
You say, "But our favorite cloud provider offers load balancing as a service (LBaaS) with geo-aware traffic distribution." This might be true in a statically programmed fashion, where there are no continuous measurements in place to monitor active platform latencies. For static routing, the most you can get are health checks to see if your platform(s) has a heartbeat while having a heart attack. It does not necessarily tell you your platform will fulfill your needs at that given time.
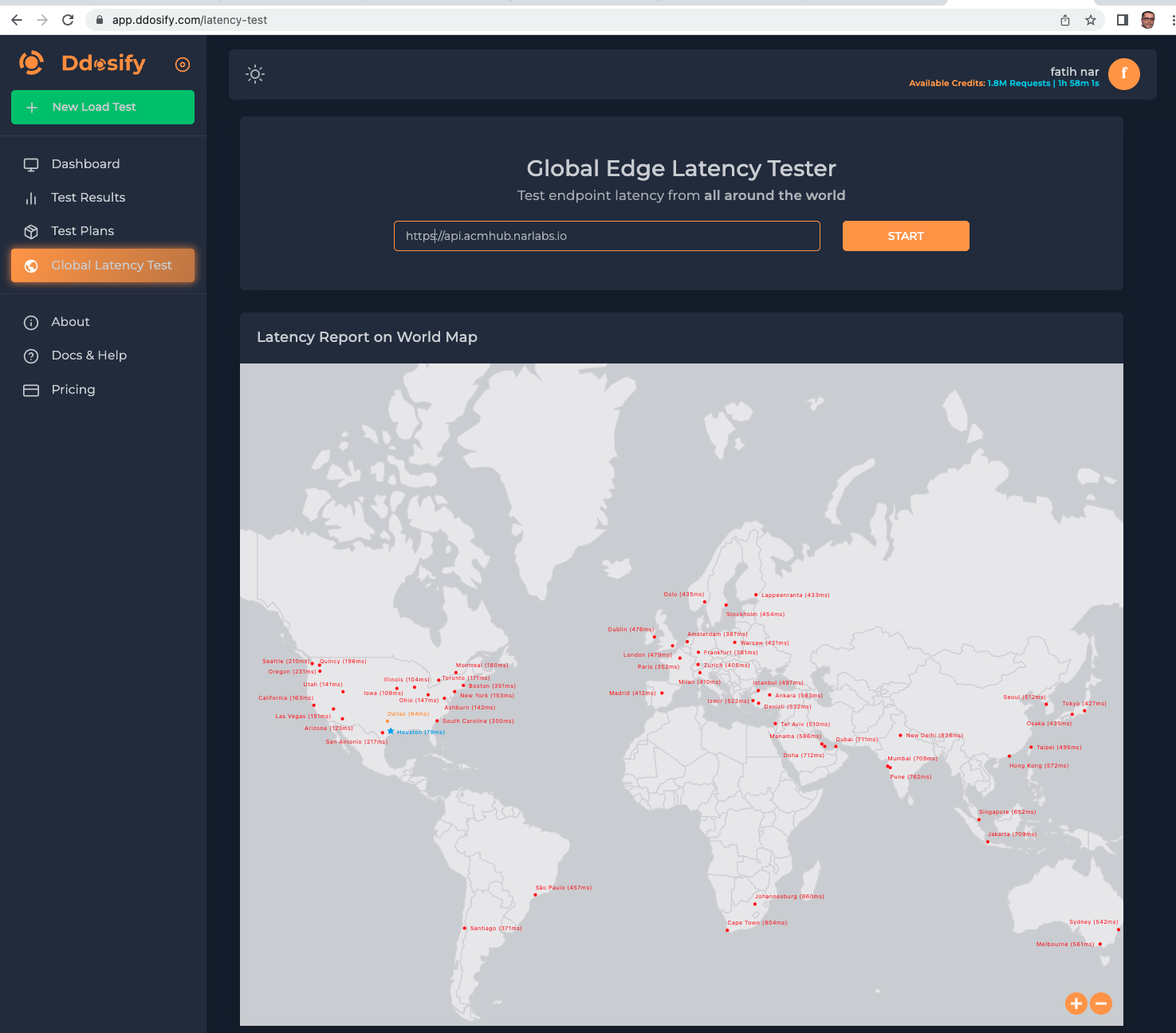
If you would like to try to see the latency to your edge infrastructure around the world, Ddosify's Global Edge Latency Tester is available (log in required).
Key findings
- Observability of latency is not a one-time job. It is a continuous effort.
- In case of a service outage or performance degradation that impacts user experience and may conflict with approved service-level agreements, it's wise to have a good fallback or redundancy plan.
- Nature is unpredictable. It's best to have a distributed infrastructure with coverage of operational observability and excellence.
Wrap up
"All we have to decide is what to do with the latency that is given us." — Gandalf, paraphrased.
It is time to incorporate this "precious" knowledge ring into workload placement policies with a wizard (coming soon).
This originally appeared as Episode X: Lord of the Latencies on Medium and is republished with permission.
About the authors
Fatih E. Nar, has built a career by solving complex challenges in various domains including telecom, entertainment, media, and others.
With experiences at Google, Verizon Wireless, Canonical Ubuntu, Ericsson, and now Red Hat, he specializes in cloud native and data- and AI-driven solutions for enterprises and service providers.
His work blends AI, cloud, and high performance networked computing to create efficient and scalable software-driven solutions.
He holds an MSc in Information Technology and a BSc in Electronics Engineering, along with completed AI studies at MIT and Stanford, and has been admitted to Purdue University for a doctorate program for Spring 2026.
Fatih is also a recognized writer, sharing insights through his Open xG HyperCore series on Medium and contributing to AI/ML projects on GitHub and Hugging Face.
In 2025, Fatih was elected as a subject matter expert on AI/ML within Linux Foundation Networking (LFN) organization to steer and lead AI initiatives.
When not working, he’s likely exploring new datasets and AI models, ctl’ing with k8s, or sneaking dad jokes into tech discussions.
Fatih is the co-founder and CTO of Ddosify and an open source lover. He holds MSc and BSc degrees in computer science. He mainly focuses on DevOps, containerization, and microservices in the Unix ecosystem. In his previous job, he managed a computer-vision team that specialized in real-time and distributed object-detection systems.
More like this
Sit, stay, deploy: Lessons from a real-world robotic blueprint on scaling edge computer vision
Lessons from an autonomous computer vision system on the air-gapped edge
Infrastructure At The Edge | Compiler
Open Curiosity | Command Line Heroes
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds