

In a previous introductory article, The software defined programmable logic controller (PLC), our colleague Daniel Fröhlich introduces the concept of "predictable low latency" and how it compares to strict real time.
This article explains how we extended the benchmarking of the Red Hat OpenShift Performance Addon Operator, and underlying Red Hat Enterprise Linux (RHEL), to OpenShift Virtualization to assess whether OpenShift can accommodate latency-sensitive VM workloads.
Investigating network latency
Our focus is on latency and jitter, but our tests also include the network's impact on latency. After all, the workload types we are investigating not only talk to other applications but may also control physical machinery, which makes a "predictable low latency"—with an emphasis on predictable—paramount.
Network latencies are as critical for manufacturing as the jitter introduced by an operating system. We run our test workloads in virtual machines (VMs) on OpenShift, leveraging OpenShift Virtualization, to show that this benchmarking is not limited to cloud-native applications running in containers and that it can also accommodate lift-and-shift use cases.
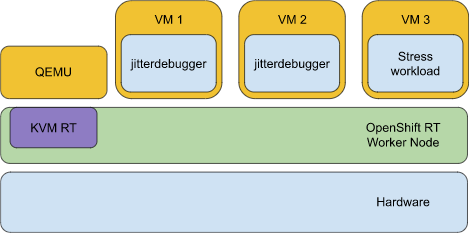
For the sake of cross-validation and to ensure consistency of results with the benchmarking demonstrated in the software-defined PLC article (linked at the top of this article), we started with a jitter test of the system. We deployed two jitterdebugger instances in VMs on a real-time capable worker node within an OpenShift cluster (shown in the figure above). A real-time capable worker node in OpenShift runs RHEL with an optimized kernel designed to maintain low latency, consistent response time, and determinism. We applied performance tuning using the OpenShift Performance Addon Operator.
We deployed an additional stress workload on our OpenShift real-time worker node as noise to make the results more relevant for real-world scenarios. The jitterdebugger measurement was executed for three days to prove that we could achieve and maintain this low latency.
[ Get the eBook Hybrid cloud and Kubernetes: A guide to successful architecture ]
Both jitterdebugger instances demonstrated similar values resulting in maximal latencies of 54 and 55µs, which is consistent with the previous observations when running those workloads directly in containers. That consistency allows us proceed with the goal of this demo: investigating network latencies.
We modified the test setup to assess the networking capabilities. Measuring instances requires access to two independent networking interfaces (NICs). To achieve the maximal performance, both NICs were mounted to guest VMs using PCI passthrough (shown in the figure below).
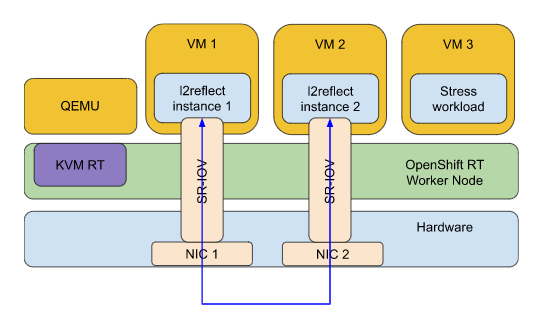
For the measurement, we used the l2reflect test. The l2reflect test is a DPDK application that implements a ping-pong benchmark to estimate latency on the L2 level between two networking devices. The benchmark leader sends a packet to the second instance, and a timestamp is taken. The second instance returns the packet, and a second timestamp is taken. The difference between the first and second timestamps is recorded as the latency.
We executed the l2reflect test for five days to replicate a realistic scenario of a 24/7 deployment, resulting in a maximum latency of 65µs. Compared to 55µs latency measured with the jitterdebugger test, communication over the network caused only 10µs overhead, which is still an acceptable level.
[ Cheat sheet: Kubernetes glossary ]
Wrap up
This benchmarking demonstrates that OpenShift can accommodate latency-sensitive workloads using OpenShift Virtualization in conjunction with the OpenShift Performance Addon Operator. Organizations can expect their latency-sensitive applications to be free from interruptions and suitable for various manufacturing use cases. At the same time, they gain access to all advantages of a modern cloud-native deployment, scaling, and management system such as OpenShift.
About the authors
Marcelo works as a Principal Sofware Engineer at Red Hat,
in the areas of virtualization and real-time.
Alexander studied theoretical physics. After receiving his Ph.D. in Medical Imaging, he switched to software development and worked for the automotive industry for almost seven years at Tier 1 and Tier 2 suppliers. Today, Alexander's role as a software engineering manager has evolved into different aspects of virtualization, including but not limited to Real-Time and ARM.
Max works as Senior Solution Architect in manufacturing, making things better by bringing the Cloud, Kubernetes, OpenShift, and Linux together to generate business value.
More like this
Announcing Red Hat OpenShift Platform Plus for Red Hat OpenShift Service on AWS on AWS Marketplace
Red Hat Ansible All-Stars: Driving the future of network and infrastructure automation
Scaling with Orchestrators | Compiler
Container Roundup | Compiler
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds