
When deploying an application to the cloud (whether public, private, or on-premises), it's important for cloud architecture teams to know the application's CPU and memory resource requirements. Often, teams get an application to production before realizing its resource needs were either under or overestimated, leading to firefighting in the production environment. Many operational challenges faced in production happen because this process was overlooked.
Some of the benefits of properly estimating an application's resource needs before getting it to production include:
- Understanding the application's CPU and memory requirements
- Knowing whether an application is more CPU- or memory-intensive
- Making it simpler to carve resources on OpenShift or Kubernetes, which in turn makes creating quotas and limits for the application namespace easier
- Allowing capacity planning from an operations perspective; for instance, helping a cluster administrator determine how many worker nodes are required to run workloads in the cluster
- Decreasing cost substantially, especially if the Kubernetes cluster is in public cloud infrastructure
Estimating an application's resource needs is very challenging. To be honest, it involves some trial and error. Accurately identifying a container's resource requirements and how many replicas a service needs at a given time to meet service-level agreements takes time and effort; hence the process is more of an art than a science.
You'll first want to identify a good starting point for the application, aiming for a balance of CPU and memory. After you've decided on a suitable resource size for the application, establish a process to constantly monitor the application's resource actual usage over a period of time.
This article defines some utilization concepts, definitions, and practices that cloud architects can use to develop their architectures. My companion article 8 steps for estimating a cloud application's resource requirements on Enable Sysadmin explains how to estimate resource requirements.
[ Download the O’Reilly eBook Kubernetes patterns for designing cloud-native apps for detailed, reusable Kubernetes patterns for container deployment and orchestration. ]
Types of compute resources
Compute resources are measurable quantities that can be requested, allocated, and consumed. They are different from API resources such as pods, services, and routes that are accessible and modified through the Kubernetes/OpenShift API server.
There are two types of compute resources:
- Compressible resources: These resources are available in limited quality in a given time slice; however, there is an unlimited amount of them (if you can wait). Examples of this resource type are CPU, block I/O, and network I/O. For estimating application resources, focus on the CPU. Once an application hits the CPU limits allocated, the application starts throttling, adversely leading to performance degradation. OpenShift/Kubernetes will not terminate those applications.
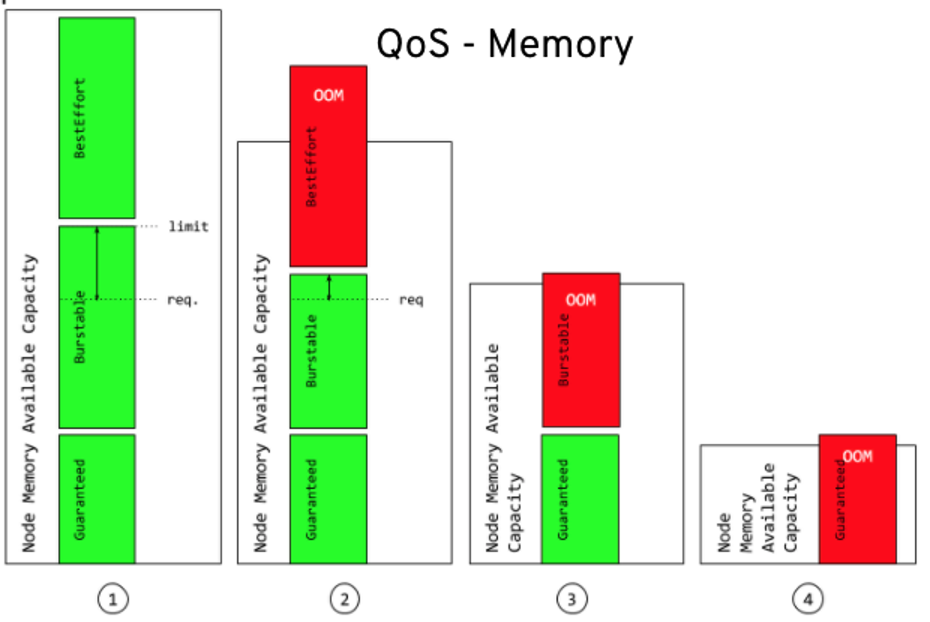
- Incompressible resources: These are limited resources; once you run out of them, your application will not get more. Examples include memory and disk space. Unlike CPU, you can't make memory run slower. Instead, OpenShift/Kubernetes automatically restarts or terminates the applications once it reaches the memory limit.
Factors to consider in resource planning
An architect needs to consider the following factors during the application resource planning process to avoid issues in production.
[ Achieve transformative automation with Ansible Automation Platform. Learn more in the IT executive's guide to automation eBook. ]
1. Resource units
There are two resource unit types to understand:
- CPU: CPU resources are measured in millicores. If a node has two cores, the node's CPU capacity would be represented as 2000m. The unit suffix m stands for "thousandth of a core."
- Memory: Memory is measured in bytes. However, you can express memory with various suffixes (E, P, T, G, M, K and Ei, Pi, Ti, Gi, Mi, Ki) to express measures including mebibytes (Mi) and petabytes (Pi). Most people simply use Mi.
The following shows a container with a request of 30m CPU and 128MiB of memory. The container has a limit of 60m CPU and 512MiB of memory.
spec:
containers:
- image: quay.io/ooteniya/todo-spring:v1.3.6
imagePullPolicy: Always
name: todo-spring
resources:
limits:
memory: "512Mi"
cpu: "60m"
requests:
memory: "128Mi"
cpu: "30m"2. Resource quotas
A resource quota provides constraints that limit aggregate resource consumption per project. It limits the number of objects that can be created in a project by type, as well as the total amount of compute resources and storage the project might consume. It is defined by a ResourceQuota object.
The following defines a resource quota object on CPU and memory:
apiVersion: v1
kind: ResourceQuota
metadata:
name: compute-resources
spec:
hard:
pods: "4"
requests.cpu: "1"
requests.memory: 1Gi
requests.ephemeral-storage: 2Gi
limits.cpu: "2"
limits.memory: 2Gi
limits.ephemeral-storage: 4GiThis is usually defined by limiting how many resources a single tenant in a multitenant environment can request so as not to take over the cluster. This is evaluated at Request Time.
3. Requests and limits
Requests are evaluated at Scheduling Time and count towards the quota. Limits, in turn, are evaluated at Run Time and are not counted towards the quota:
containers:
- image: quay.io/ooteniya/todo-spring:v1.3.6
imagePullPolicy: Always
name: todo-spring
resources:
limits:
memory: "512Mi"
cpu: "60m"
requests:
memory: "128Mi"
cpu: "30m"4. Limit range
A limit range restricts resource consumption in a project. You can set specific resource limits for a pod, container, image, image stream, or persistent volume claim (PVC) in the project. It is defined by a LimitRange object:
apiVersion: "v1"
kind: "LimitRange"
metadata:
name: "resource-limits"
spec:
limits:
- type: "Container"
max:
cpu: "2"
memory: "1Gi"
min:
cpu: "100m"
memory: "4Mi"
default:
cpu: "300m"
memory: "200Mi"
defaultRequest:
cpu: "200m"
memory: "100Mi"
maxLimitRequestRatio:
cpu: "10"
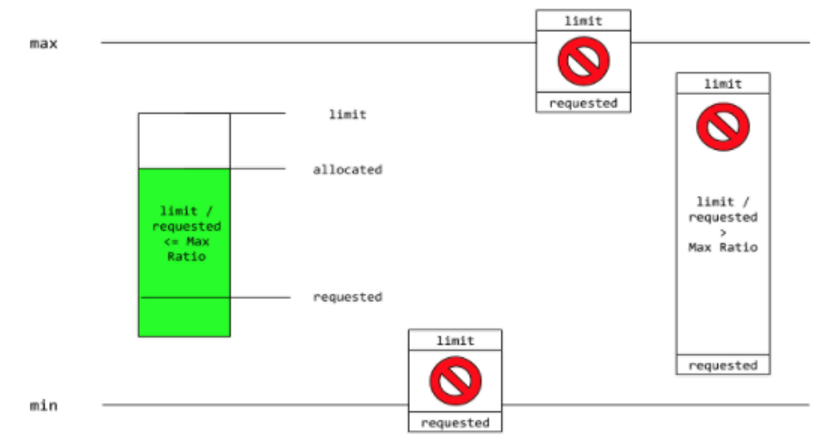
When the Request and Limit are not set for a container, whatever the namespace administrator defines is the default. It is strongly recommended that application architects and developers always specify resource requests and limits for their pods.
[ You might also be interested in reading Migrating 3,000 applications from another cloud platform to Kubernetes: Keys to success. ]
5. Quality of Service (QoS)
In an overcommitted environment, for example, a situation where the scheduled pod has no request or the sum of limits across all pods on that node exceeds available machine capacity, the node must prioritize one pod over another. The mechanism used to determine which pod to prioritize is the Quality of Service (QoS) class.
There are three classes:
- A BestEffort QoS is provided when a request and limit are not specified.
- A Burstable QoS is provided when a request is specified that is less than an optionally specified limit
- A Guaranteed QoS is provided when a specified limit is equal to an optionally specified request.
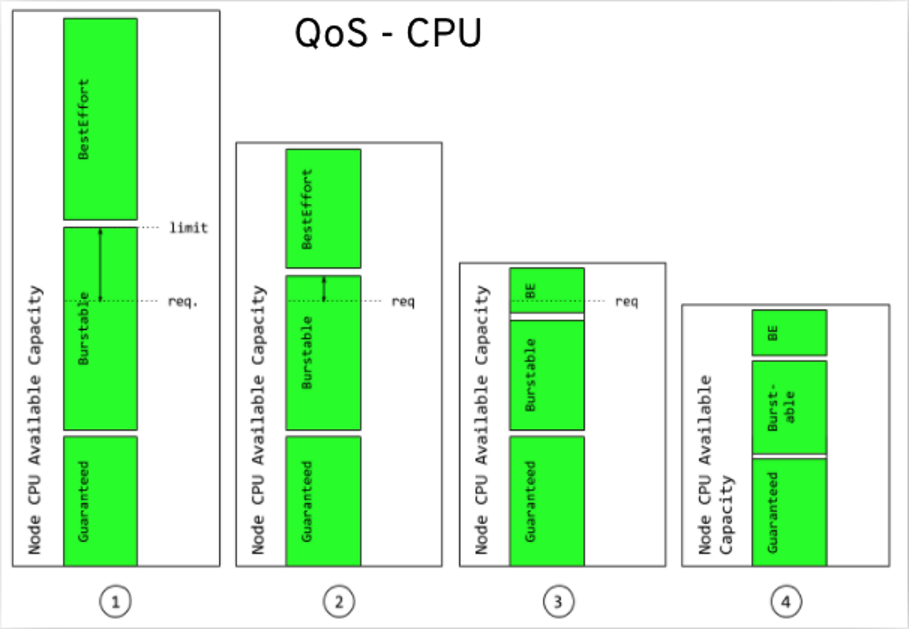
In terms of priority, the Guaranteed, Burstable, and BestEffort have priority 1 (highest), priority 2, and priority 3 (lowest), respectively.
Resource estimation
As mentioned, the request set on a pod counts towards the quota. Determining whether an application is well estimated, underestimated, or overestimated depends on comparing resource requests and the actual resource consumption.
Generally, a certain threshold is set above and below the request to determine resource-related application performance. For example, assume a certain percentage threshold, say 20% of the request, is set above and below the request. In a well-estimated application, resource usage stays above the overestimated threshold and below the underestimated threshold. If actual resource use is below the overestimated threshold, the application is considered overestimated. If the actual use is above the underestimated threshold, it is underestimated. You can learn more about this in Raffaele Spazzoli's article on capacity management.
General advice
Performance tuning, load testing, and scaling are all part of the process for ensuring your applications are using resources well. Each of these approaches has several components to consider.
1. Use performance tuning good practices
I find some of consultant Thorben Janssen's tips for good performance tuning helpful:
- Don't optimize before you know it's necessary: Define how fast your application code must be. For example, specify a maximum response time for all API calls or the number of records you want to import within a specified time frame, and then measure which parts of your application are too slow and need to be improved.
- Use a profiler to find the real bottleneck: There are two ways of doing this: Manually try to identify suspicious code, or use a profiler:
- Manually look at your code and start with the part that looks suspicious or where you feel that it might create problems.
- Use a profiler for detailed information about each part of your code's behavior and performance, giving you a better understanding of the performance implications of your code so you can focus on the most critical parts.
- Use lightweight frameworks and avoid heavy application server overhead: For instance, use frameworks based on microprofiles instead of heavy JEE-compliant application servers.
- Create a performance test suite for the whole application: It's essential to do performance or load tests on an application to determine its breaking point. Based on the test results, work on the most significant performance problem first.
- Work on the most significant bottleneck first: It might be tempting to start with the quick wins because you can show the first results soon. Sometimes, that might be necessary to convince other team members or management that performance analysis was worth the effort. In general, I recommend starting at the top and working on the most significant performance problem first.
- Use efficient serialization techniques: Use efficient serialization formats like protocol buffers, commonly used in gRPC. For example, if you have a request that operates on only a few fields in a large message payload, put those fields into headers before passing the request to a downstream service to avoid deserializing or reserializing the payload.
2. Do load testing
Perform application load testing to determine the right amount of CPU and memory for an application to function properly at all times. Several tools are available to aid this process, such as WebLOAD, Apache JMeter, LoadNinja, Smart Meter, k6, and Locust.
Load testing identifies the following:
- Maximum operating capacity
- Ability of an application to run in the real environment
- Sustainability of the application during peak user load
- Maximum concurrent users the application can support
Load testing is an essential step in the process.
3. Use scaling
OpenShift/Kubernetes scaling capabilities provide a mechanism to adjust to user workloads dynamically. Scaling can be manual or automatic.
For static workloads or when you have insight into when an application experiences spikes, manual scaling can be used to provide an optimal configuration for the workload. Also, it provides an avenue to discover and apply the optimal settings to handle the workload. You can do this imperatively using the oc or kubectl commands. You could also do it declaratively on the application's deployment or deploymentConfig objects.
For workloads that experience sudden spikes, automatic scaling is the best choice, as you can not readily predict the spike periods.
Scaling can be horizontal, changing the replica of a pod, or vertical, changing the resource constraints for the containers in the pod.
Wrap up
Now that you have an idea of the concepts and terms involved with estimating cloud resources for new applications, it's time to delve into how to make such estimations. Read 8 steps for estimating a cloud application's resource requirements on Enable Sysadmin to learn the specific steps for making accurate estimations.
About the author
Olu is a Senior Architect at Red Hat, working with various customers in the last few years to formulate their digital transformation strategy to respond to the constantly changing business environments. He's a TOGAF 9 certified Enterprise Architect with deep experience helping organizations align their business goals and objectives to their IT execution plans. He's happily married to Funmi, and they have two boys and a girl.
More like this
Introducing Red Hat build of Karpenter
Why Operational Resilience and Digital Sovereignty Top the CIO Agenda
Container Roundup | Compiler
Untangling Networks | Compiler
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds