
In a companion article on Enable Architect, Estimating cloud application resource requirements: 5 considerations for architects, I explained the concepts and terms involved with estimating cloud resources needed for new applications. In this article, I'll provide a practical example of estimating what resources an application needs. This example aims to determine the resource requirements of a Todo-spring-quarkus application Eric Deandrea initially set up that's customized to fit this how-to.
This architecture diagram highlights the key components used in the estimation process.
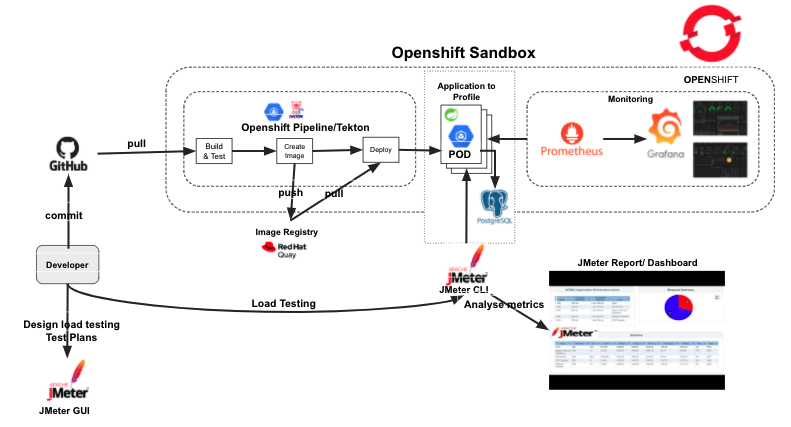
Get started
Before you can start estimating resource requirements, you need to do some setup.
Get the prerequisites
To follow along with this example, you need to:
- Have access to an OpenShift cluster
- Install the OpenShift Pipelines Operator
- Install a PostgreSQL database for the To-do application
- Install the Vertical Pod Autoscaler Operator
- Have access to an external image registry (I use Quay.io in this example)
- Create a secret for pulling images from the image registry
- Create a secret for GitHub
- Add the registry and GitHub secret to the OpenShift Pipelines service account
- Download Apache JMeter for performance testing
Set up the environment
I use a script to configure the environment. To run the script, you need the following tools preinstalled:
- Helm:
helmversion - Git :
gitversion - OpenShift CLI oc :
ocversion download - Optional Tekton CLI (tkn):
tknversion download Red Hat Build - envsubst (gettext):
envsubst--help
To get started, clone or fork the source code repository:
$ git clone https://github.com/ooteniya1/resource-estimation.gitOnce you have the environment set up, log in to your OpenShift cluster:
$ oc login --token=TOKEN --server=https://api.YOUR_CLUSTER_DOMAIN:6443Next, create the resource-estimation namespace:
$ oc new-project resource-estimationRun the setup scripts to install the openshift-pipelines, postgresql, and vertical pod autoscaler operators:
$ cd helm
$ ./setup-prereq.shYou should see output similar to this:
Installing openshift-pipelines operator
Release "openshift-pipelines" has been upgraded. Happy Helming!
NAME: openshift-pipelines
LAST DEPLOYED: Tue Mar 16 20:59:36 2021
NAMESPACE: resource-estimation
STATUS: deployed
REVISION: 1
TEST SUITE: None
Installing postgresql Operator
Release "postgresql" does not exist. Installing it now.
NAME: postgresql
LAST DEPLOYED: Tue Mar 16 20:59:42 2021
NAMESPACE: resource-estimation
STATUS: deployed
REVISION: 1
TEST SUITE: None
Installing vertical pod autoscler
Release "vertical-pod-autoscaler" does not exist. Installing it now.
NAME: vertical-pod-autoscaler
LAST DEPLOYED: Tue Mar 16 20:59:42 2021
NAMESPACE: resource-estimation
STATUS: deployed
REVISION: 1
TEST SUITE: NoneNow that you have the openshift-pipelines, postgresql, and vertical pod autoscaler operators installed, set up your GitHub and Quay.io secrets and add them to the Openshift Pipeline service account:
$ ./add-github-credentials.sh
$ ./add-quay-credentials.sh[ Start crafting code in OpenShift. Download the eBook OpenShift for Developers. ]
8 steps for estimating resources
Before I get deeper into the process, I want to outline the steps for estimating the resource requirements and determining the resource quota to use for the Todo-spring-quarkus namespace. They are:
- Define performance goals.
- Check the startup time. This is important for scaling in peak periods.
- Adjust for a fast initial startup time.
- Determine the best resource requirement for the startup time needed.
- This is not applicable to every use case.
- What is the breakpoint with one pod? Note the resource usage.
- Is the breakpoint lower than the desired performance target?
- How many replicas are needed initially to achieve the desired performance target?
- What is the resource requirement to achieve the desired throughput with a typical workload? (You need to run this for a period of time, say one day to one week.)
- What is the resource requirement to cope with spikes and "Black Friday" requests?
- Estimate the resource usage per pod and container.
- Use that result to determine the quota.
Set up the Todo application deployment and tools
Before you go through the processes outlined above, you need to prepare the application and the tools.
1. Install and deploy the Todo-spring application
These steps build on the previous environment setup steps. Make sure the commands below have completed successfully:
$ cd helm
$ ./setup-prereq.sh
$ ./add-github-credentials.sh
$ ./add-quay-credentials.shThe Todo application uses the tekton-pipeline/todo-pipeline.yaml file to build and deploy to OpenShift. The application can be deployed as a Quarkus or Spring Boot application. I am using the Spring Boot version for this example.
First, install the PostgreSQL database that the application uses:
$ oc apply -f ../todo-spring-quarkus/k8s/postgresql-instance.yaml
database.postgresql.dev4devs.com/postgresql createdNext, deploy the application:
$ cd tekton-pipeline
$ ./build-deploy-todo-spring v1.3.8This process builds the application, tags the created image as v1.3.8, pushes it to Quay.io, and deploys it to OpenShift.


The application may fail the readiness check if it does not have enough processing units to complete the initialization process. I'll provide more information about this later. To meet the required startup time for the readiness probe, update the deployment as follows:
...
spec:
containers:
- resources:
limits:
cpu: 600m
memory: 512Mi
requests:
cpu: 300m
memory: 128Mi
...The startup time should now be fast enough for the application to pass the readiness check.


2. Monitor the application's resource usage
The Vertical Pod Autoscaler Operator (VPA) automatically reviews the historical and current CPU and memory resources for containers in pods and can update the resource limits and requests based on the usage values it learns.
The VPA uses individual custom resources (CR) to update all of the pods associated with a workload object, such as a Deployment, Deployment Config, StatefulSet, Job, DaemonSet, ReplicaSet, or ReplicationController.
The VPA helps you understand the optimal CPU and memory usage for your pods and can automatically maintain pod resources through the pod lifecycle.
[ Looking for insight on DevSecOps? Download the checklist Considerations for implementing DevSecOps practices. ]
The VPA has three main components:
- Recommender monitors the current and past resource consumption and provides recommended values for the container's CPU and memory requests.
- Updater checks which of the pods have the correct resources set, and if they don't, kills them so that their controllers with the updated requests can re-create them.
- Admission plugin sets the correct resource requests on new pods.
Here is the vpa.yaml file:
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: todo-recommender-vpa
spec:
targetRef:
apiVersion: "apps/v1"
kind: Deployment
name: todo-spring
updatePolicy:
updateMode: "Off"The VPA recommendations are stored in the status. As you can see in vpa.yaml, the updateMode: "Off" means no changes to the selected resources are performed based on the recommended values in the status. There are two other types: updateMode: "Initial" and updateMode: "Auto".
- Initial means recommendations are applied during pod creation, and they influence scheduling decisions.
- Auto means pods are automatically restarted with the updated resources based on recommendations.
The VPA is not currently recommended for production environments, but it is an excellent tool to deploy in the development environment for estimating resource usage.
It's time to create the CR:
$ oc apply -f ..//todo-spring-quarkus/k8s/vpa.yaml
verticalpodautoscaler.autoscaling.k8s.io/todo-recommender-vpa created3. Record test plans using Apache JMeter
Now that you have the Todo application up and running, the next step is to create the test plans based on the Todo endpoints. For this example, the endpoints to profile are:
$ curl -X GET "http://todo-spring-resource-estimation.apps.cluster-5a89.sandbox1752.opentlc.com/todo/1" -H "accept: */*"
$ curl -X PUT "http://todo-spring-resource-estimation.apps.cluster-5a89.sandbox1752.opentlc.com/todo" -H "accept: */*" -H "Content-Type: application/json" -d "{\"id\":0,\"title\":\"Test Resource Estimation\",\"completed\":true}"
$ curl -X POST "http://todo-spring-resource-estimation.apps.cluster-5a89.sandbox1752.opentlc.com/todo" -H "accept: */*" -H "Content-Type: application/json" -d "{\"id\":0,\"title\":\"string\",\"completed\":true}"First, download Apache JMeter, extract it in a directory, and start the application:
$ unzip apache-jmeter-5.4.1.zip
$ cd apache-jmeter-5.4.1
$ ./bin/jmeter.sh
================================================================================
Don't use GUI mode for load testing !, only for Test creation and Test debugging.
For load testing, use CLI Mode (was NON GUI):
jmeter -n -t [jmx file] -l [results file] -e -o [Path to web report folder]
& increase Java Heap to meet your test requirements:
Modify current env variable HEAP="-Xms1g -Xmx1g -XX:MaxMetaspaceSize=256m" in the jmeter batch file
Check : https://jmeter.apache.org/usermanual/best-practices.html
================================================================================
Design the load-testing plan
The first step in designing a load-testing plan is to understand the system's performance goal or target from a business perspective.
Here are the performance requirements for the Todo application:
- Throughput: It must be able to process a minimum of 1,000 transactions per second.
- Error rate: It has a 0.06% error rate, meaning the application must perform at a minimum of 99.94%.
- Boot-up time: It has relatively fast boot time <= 40sec. This is necessary in case there is a need for scaling.
- Concurrent users: It must be able to handle up to 2,000 users or requests per second.
- Peak/Black Friday period users: It must be able to handle up to 4,000 users or requests per second within one minute windows.
One way to set up your test script is using JMeter's Test Script Recorder. See this step-by-step guide for more information.
Once you have test scripts that mimic the type of user interaction you would like to perform, the next step is to configure the Thread Group, which defines a pool of virtual users that will execute the test case against the system. See Elements of a Test Plan for more information.
[ Are you moving workloads to the cloud but having issues with legacy processes and organizational structures? O'Reilly's eBook Accelerating cloud adoption might help. ]
I have designed two test scripts to execute against the Todo application:
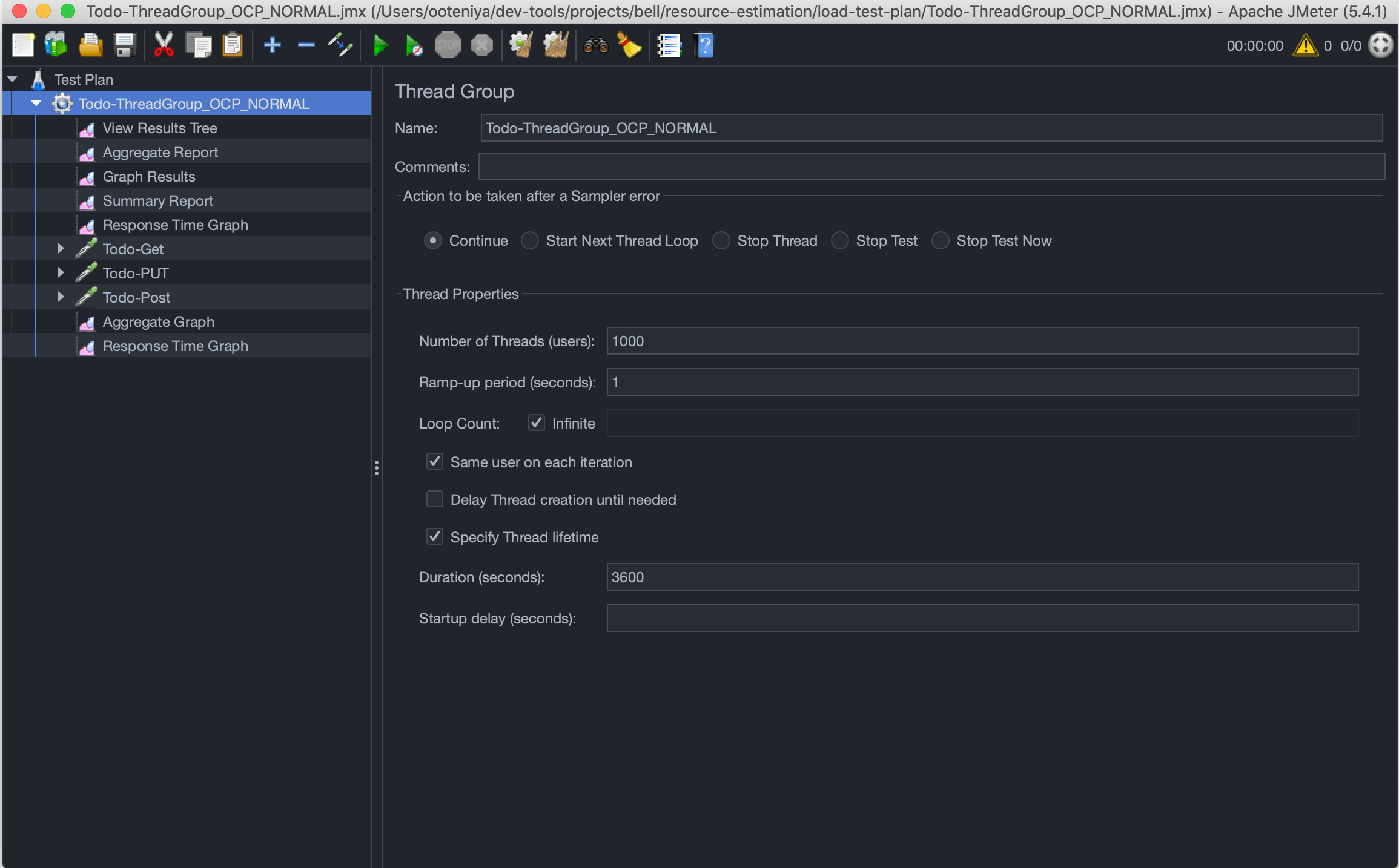
1. Normal load: At any given point in time, there will be 2,000 concurrent users on the system per second. For this example, you will run the normal load for one hour while monitoring the performance and the configuration's ability to handle such requests.
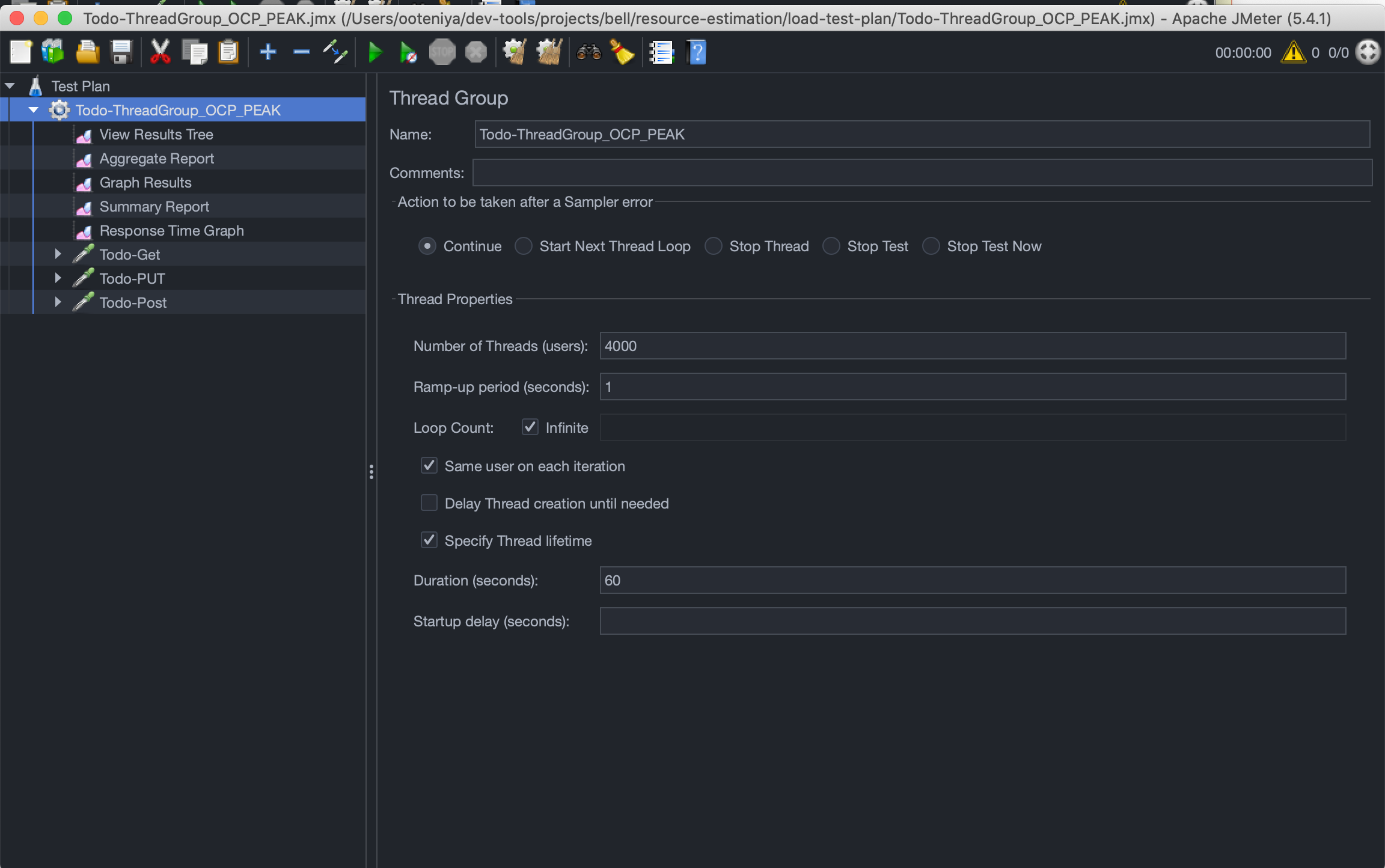
2. Peak/Black Friday load: For a peak load, you expect 4,000 additional concurrent users to be on the system for several cycles within a second for a total of one minute. This is in addition to the 2,000 concurrent users on the system per second in a normal load scenario, making a total of 6,000 concurrent users per second.
Execute the test script and monitor performance and resources
I recommend using the Apache JMeter command-line interface (CLI) to execute the test scripts. The main benefit of the CLI over the graphical user interface (GUI) for load testing is that it consumes fewer resources and gives more reliable results than the GUI. This is a recommended approach for running a load test as it avoids the overhead of the JMeter GUI. The CLI also generates several reports you can use to analyze the application's performance.
NOTE: Use JMeter GUI only to create, maintain, and validate the scripts. Once the script is validated, use the CLI to run the load test.
OpenShift Monitoring and the installed VPA CR will monitor the resource usage.
Previously I listed the eight steps for estimating resources to fulfill the performance requirements, and I'll repeat them for clarity:
- Define performance goals.
- Check the startup time. This is important for scaling in peak periods.
- Adjust for a fast initial startup time:
- Determine the best resource requirement for the startup time needed.
- This is not applicable to every use case.
- What is the breakpoint with one pod? Note the resource usage.
- Is the breakpoint lower than the desired performance target?
- How many replicas are needed initially to achieve the desired performance target?
- What is the resource requirement to achieve the desired throughput with a typical workload? (You need to run this for a period of time, say one day to one week.)
- What is the resource requirement to cope with spikes and "Black Friday" requests?
- Estimate the resource usage per pod/container.
- Use that result to determine the quota.
1. Determine the right resources to achieve the required startup time
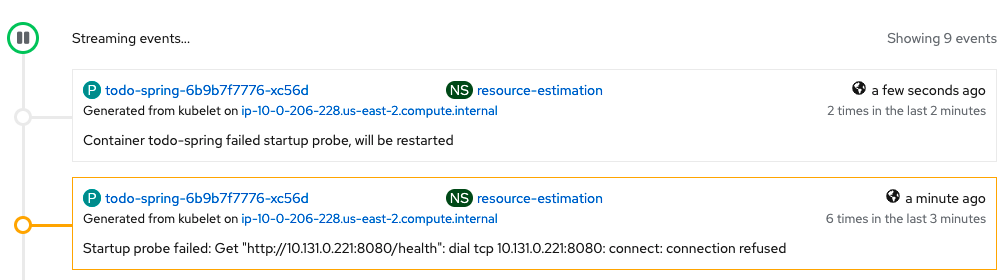
The application's startup time requirement is <= 40sec. This is important because you may want to scale during peak periods (such as Black Friday) by adding more pod replicas to cater to the load. The current configuration fails the Startup probe because the application takes a long time to initialize. The CPU is throttled based on the current CPU request and limit configurations.
...
spec:
containers:
- image: 'quay.io/ooteniya/todo-spring:v1.3.8'
imagePullPolicy: Always
name: todo-spring
resources:
limits:
memory: "512Mi"
cpu: "60m"
requests:
memory: "128Mi"
cpu: "30m"
ports:
- containerPort: 8080
protocol: TCP
...
startupProbe:
httpGet:
path: /health
port: 8080
failureThreshold: 3
periodSeconds: 40
... The pod will be killed and restarted based on its restartPolicy.

The solution is to bump up the CPU resources to give it enough processing power to start at the required target of less than 40 seconds. The new configuration is below:
...
resources:
limits:
memory: "768Mi"
cpu: "240m"
requests:
memory: "512Mi"
cpu: "200m"
...With a CPU resource request of 200m and 240m (20% of request value) limit, the startup time of 73.902 seconds does not meet the startup performance target. The pod will be restarted because it's lower than the startup probe.

To achieve that target, play around with the request and limit (20% of request).
...
resources:
limits:
memory: "768Mi"
cpu: "480m"
requests:
memory: "512Mi"
cpu: "400m"
...This new configuration meets the startup target of less than 40 seconds:
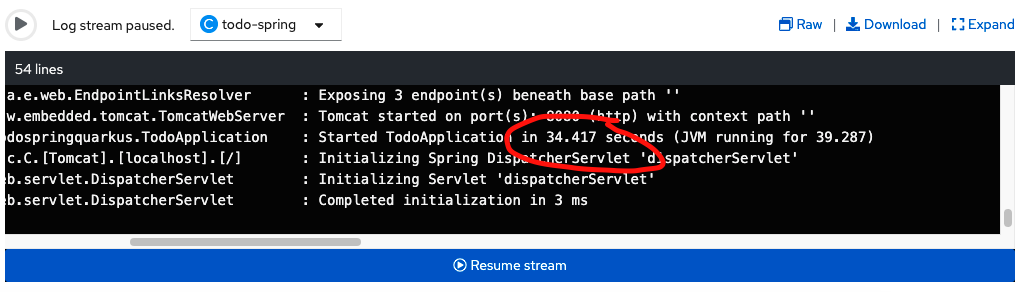
To achieve optimal performance, do not forget to tune the runtime parameters, such as the JVM parameters for Java.
2. Determine the resource requirement for a normal load
Now that you have achieved the required startup time, the next step is to determine the number of resources required to achieve the target throughput under a normal workload. It is also important to note that the Todo application is more CPU intensive than memory. For example, it does not require any data transformation.
The table below highlights the resource estimation for a normal load of 2,000 virtual users per second for two minutes. For a more accurate result, run the workload for at least five hours up to two weeks.
With CPU request of 400m and limit of 480m:

Based on Table 1, to achieve the performance target of a minimum of 1,000tps and a maximum 0.06% allowed error rate, you need four pods with memory limits of 512mi and 480m of CPU. If you were to request a quota based on this, it would require two cores of CPU and 2Gi of memory in the namespace. The configuration used for the table above is shown below.
For a Burstable configuration (one that can exceed normal bandwidths for a short time):
...
resources:
limits:
memory: "768Mi"
cpu: "480m"
requests:
memory: "512Mi"
cpu: "400m"
...For a Guaranteed configuration (where CPU and memory are the same for every container):
...
resources:
limits:
memory: "768Mi"
cpu: "480m"
requests:
memory: "768Mi"
cpu: "480m"
...With CPU request of 480m and limit of 576m (a 20% increase):
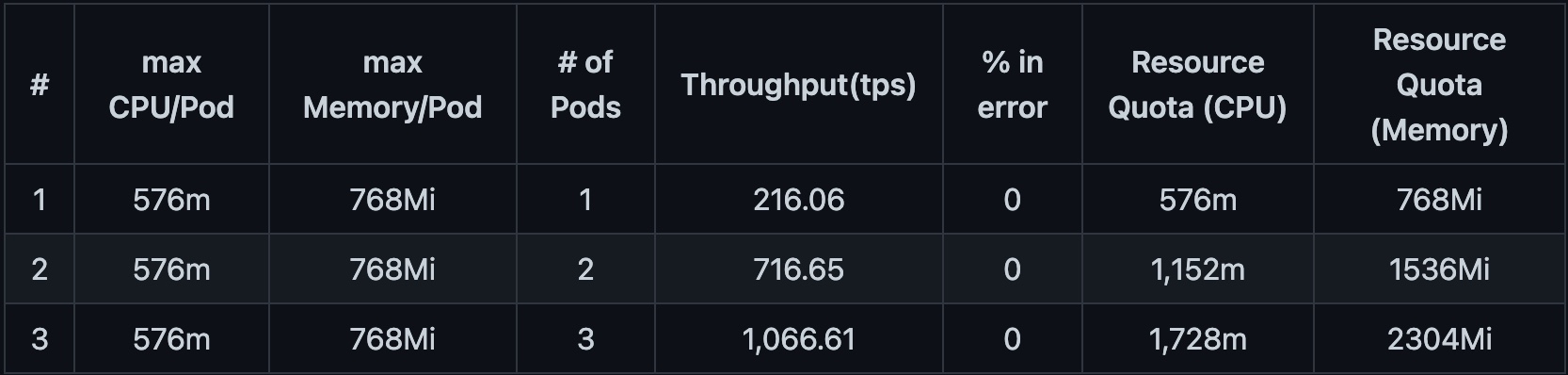
Table 2 shows that three pod replicas are required to meet the performance target with memory limits of 512Mi and 576m of CPU limit, which is a 20% CPU resource increase over the configuration from Table 1. If you were to request a quota based on this, it would require 1.7 cores of CPU and 1.5Gi of memory in the namespace.
With CPU request of 576m and limit of 692m (an additional 20% increase):

In Table 3, you see that two pod replicas are required to meet the performance target with memory limits of 768Mi and 692m of CPU limit, which is a 20% CPU resource increase over the configuration from Table 2. If you were to request a quota based on this, it would require 1384m of CPU and 1536Mi of memory in the namespace.
The application gets killed if you reduce the memory by 20% to optimize the resources. This indicates that the memory requirement set for the application is optimal since it can sustain the normal load, but the pods get killed once reduced by 20% of the current value.
With CPU request of 692m and limit of 830m (20% increase):

Table 4 indicates that a further CPU increase of 20% improved the throughput, but the error rate increased above the allowed threshold.
Therefore, the optimal configuration for the performance target is what you see in Table 3, which is a memory limit of 768Mi and 692m of CPU limit with two pod replicas.
3. Determine the resource requirement for a peak load
Starting with the optimal resource requirement for a normal workload, put a peak workload on the system and determine how many replicas you need to handle the load and still achieve the performance target.

4. Calculate the resource quota for the application namespace
Based on the normal and peak "Black Friday" workloads, Table 6 indicates the number of resources required to run the application successfully.
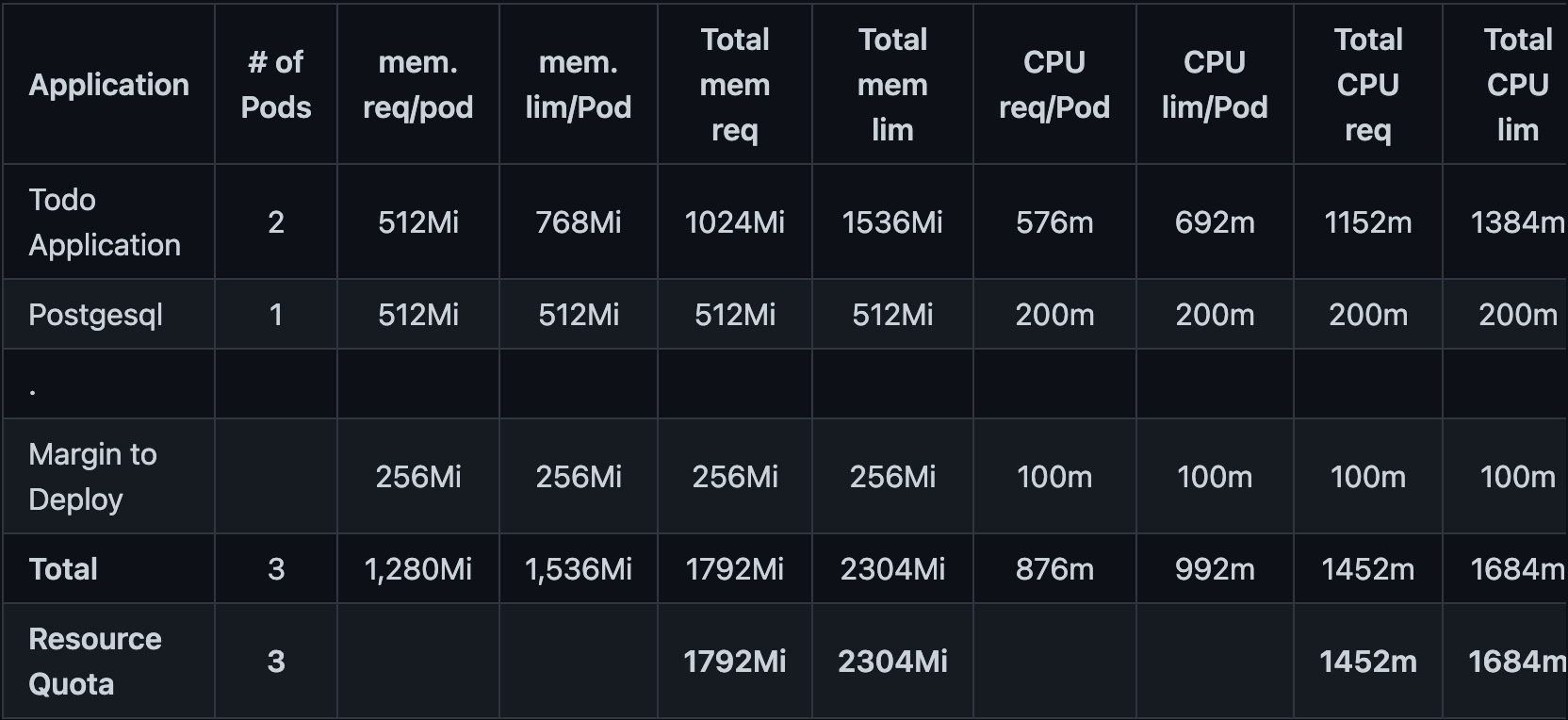
kind: ResourceQuota
apiVersion: v1
metadata:
name: resource-estimation-rq
namespace: resource-estimation
spec:
hard:
limits.cpu: 1684m
limits.memory: 2304Mi
pods: '3'
requests.cpu: 1452m
requests.memory: 1792Mi
scopes:
- NotTerminatingWrap up
Estimating the resources an application needs is very challenging. It takes time and effort; hence the process is more art than science. First, identify a good starting point, aiming for a balance of CPU and memory. After you've decided on a suitable resource size for the application, you also need to set up a process to monitor the application's resource actual usage constantly over a period of time. The Deploying Vertical Pod Autoscaler and other monitoring tools such as OpenShift Monitoring console help with this.
In summary, to estimate the resources an application needs, you must first determine the performance target of the application, profile and tune the application, perform load testing to simulate the typical and peak loads, monitor the application over a period of time, and then review the estimated and actual resource usage.
About the author
Olu is a Senior Architect at Red Hat, working with various customers in the last few years to formulate their digital transformation strategy to respond to the constantly changing business environments. He's a TOGAF 9 certified Enterprise Architect with deep experience helping organizations align their business goals and objectives to their IT execution plans. He's happily married to Funmi, and they have two boys and a girl.
More like this
Debunking IT automation myths: A strategic blueprint for healthcare payers
Introducing Red Hat build of Karpenter
Untangling Networks | Compiler
Infrastructure At The Edge | Compiler
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds