
This article is the fourth of a four-part series about the emergence of the modern data center. The previous installment discussed the evolution of the data center from dedicated server rooms to shared facilities powered by ethernet and TCP/IP networking.
This installment looks at how the development of distributed applications running in colocation facilities gave rise to the modern data center and, eventually, the cloud.
Distributed applications push the data center forward
As described in previous installments in this series, the notion of the central data center has been around since the mainframe could support multi-user sessions on a single machine. A mainframe allowed a group of employees to use compute en masse. However, the employees needed to be near each other due to the physical limitations imposed by the length of wire used to connect keyboards, printers, and monitors to the mainframe. The room in which they worked was called the data processing center. That room was an early form of what would become known as a data center.
But, given the cost, mainframe computing was only viable for big companies with big IT budgets. However, the PC made computing affordable to a larger customer base than the mainframe could ever hope for. The little machines were turning up everywhere. People could do the computing they wanted as they wanted. Every person in a company's Accounting Department ran their own instance of Excel. Every student in college ran their own word processor. Every marketing person ran their own version of PowerPoint. And, because the machines were networked together, users could easily share the data each application used. However, for the most part, PC applications were still monolithic programs that were installed on each user's computer. The notion of a PC application architecture that was made up of parts hosted over many computers and distributed over the network was an idea that had yet to evolve.
However, there was one type of technology where the idea of the distributed application was taking hold. That technology was databases.
Databases leverage the benefits of distributed computing
At the enterprise level, database applications are storage hogs. While the actual program that makes up a database's logic (a.k.a the database server) can fit on a single computer's hard-drive, the data that the database stores can easily exceed a computer's storage capacity. To address this problem, database administrators separate database logic from database storage. The technique is to host the database program on one machine's disk and store its data on other computers. The locations of the disks on the storage computers are declared in the database program's setup configuration file. As the storage drives fill up, additional computers are added to provide more storage capacity before the current limits are reached. (See Figure 1, below.)

Figure 1: Databases were one of the first distributed applications separating logic from storage among a variety of microcomputers
Distributing the components of a database over many machines not only addresses the risk of maxing out storage capacity, it also plays a critical role in ensuring the database is accessible on a 24/7 basis. There are various ways to ensure high availability, including load balancing against several identical database instances, as shown in Figure 2 below, or creating a cluster of machines in which replicas support the main database, as shown below in Figure 3.
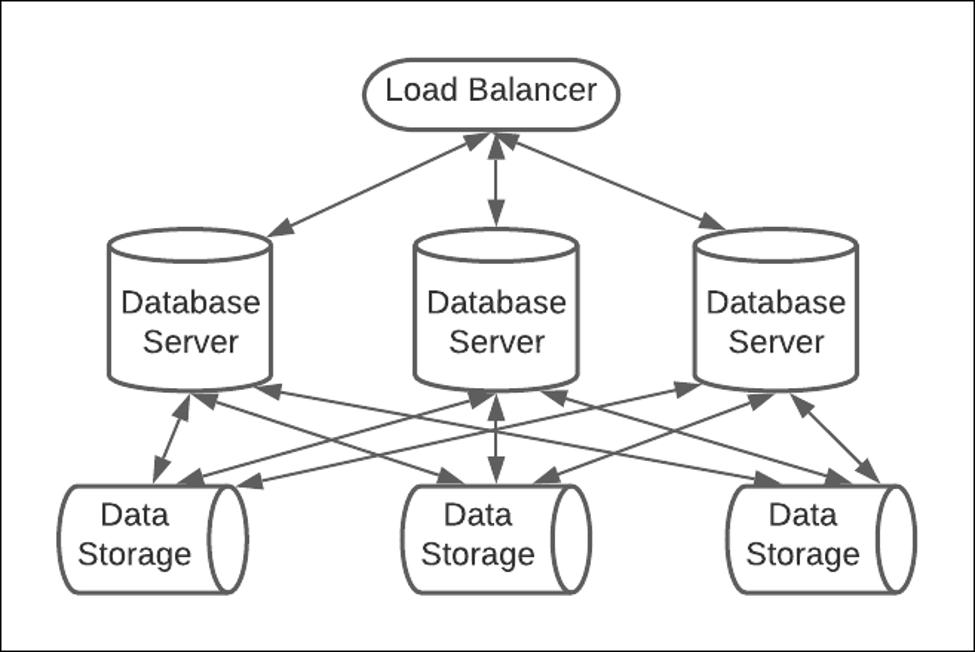
Figure 2: Load balancing ensures efficient and reliable database availability
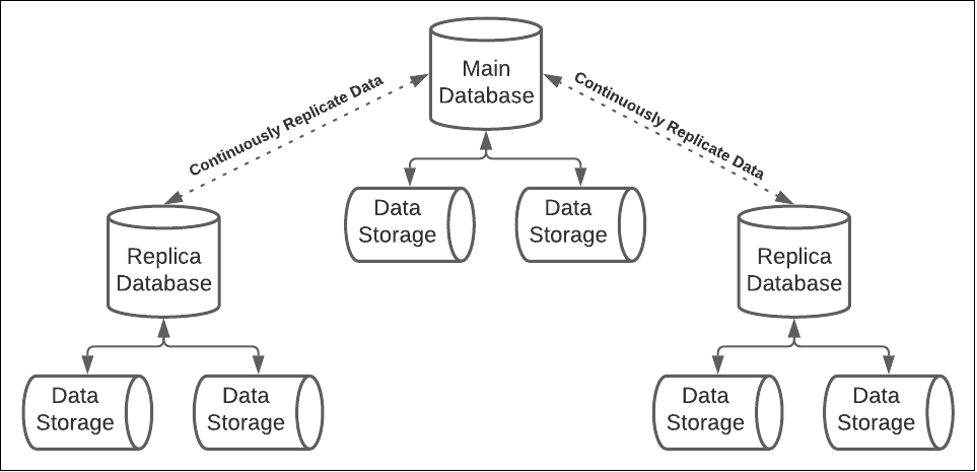
Figure 3: In a replication architecture, should the main database go down, one of the replicas will be elected to be the new main database
No matter which database architecture is used, the important thing to understand in terms of the evolution of the data center is that using multi-machine configurations to store data safely and ensure 24/7 availability are database design principles that have been around since the early days of running enterprise databases on x86 machines.
At first, many of these databases were hosted in a business's server closets. Eventually, they made their way into server rooms and then finally to off-site hosting facilities. Given the inherently distributed nature of database technology, migration was easy. Administrators were accustomed to working with databases remotely, as were the client-server programs that accessed the databases, using nothing more than credentials in a connection string hidden from the end-user. The database's location didn't matter as long as the computer that hosted it was discoverable on the network. As time went on, fewer people knew where the data was, and fewer people cared. Such information was confined to a few network administrators and to the network itself. Thus, at the conceptual level, given the opacity of the database's physical architecture, the data center itself eventually became the computer on which the database application ran. This way of thinking was an omen of things to come.
Distributed logic catches on
Eventually, the distribution of computing, as exemplified in database storage and instance redundancy, moved onto application logic. Architectural frameworks based on distributed technologies such as Remote Procedure Call (RPC), the Distributed Component Object Model (DCOM), and Java's Remote Method Invocation (JavaRMI) made it possible for developers to create small components of logic that could be aggregated into a variety of larger applications. While a component might live on a particular computer, from the view of an enterprise architect focused on creating a distributed application, the components "lived on the network."
Just as databases had started out in the server closet, then moved to the server room, and finally to computers hosted at a remote location, so too did distributed applications. The correlation between the growth in distributed application development activity and the proliferation of data centers might have coincidental, but the interdependency is hard to ignore. It wasn't exactly a chicken and egg situation, but there were many omelets being made in the form of distributed applications, and the data center was the frying pan in which they all ran.
From the rack to the cloud
All the pieces for a unified, remote data center were coming together. The single microcomputer server had evolved into a multitude of x86 machines that could be added to or removed from a central hosting facility on demand. Networking was ubiquitous and standardized. Any company with the technical know-how could lease space in a building and set up a rack of networked x86 machines. As long as the space had enough air-conditioning capacity to keep the servers cool and the building had a cable that connected back to a larger network, a business could have its own remote data center in a matter of months, if not weeks.
Creating your own data center made sense if you were a major enterprise that had to support large-scale applications such as those found in heavy manufacturing and finance. Still, for many smaller companies, the economy of scale just wasn't enough to justify the expense. It was easier to stay with an on-premises server room.
Yet, while financing your own data center was out of reach for many businesses, paying a fee to lease rack space in existing public data centers was another matter, if only they existed. By the end of 1990, they did. They were called colocation facilities.
The commercial success of colocated ISPs
A colocation facility provides the racks, electricity, air conditioning, and network connection typical of server rooms found on site. Also, they provide physical security, thus ensuring that only authorized personnel have access to the physical machines. In return, customers pay a monthly fee.
Colocation facilities proliferated as they proved to be a win-win situation for all. And, when the Internet became a "thing" in the mid-1990s, "colos," as they came to be known, provided the operational foundation from which Internet Service Providers (ISP) grew. ISPs would prove to play an important part in making the Internet available to small businesses and individuals who wanted to have a presence on the Internet.
The Internet was not only a technical game-changer, it was a commercial and cultural one as well. The Internet transformed networking from a technically boutique specialty to a global commodity. Whereas in the past large-scale networking was the province of big business, major universities, and government, the Internet made the benefits and opportunities provided by global networking available to everyone. Many of the companies that today are Internet powerhouses started as racks of servers in an ISP's data center. Amazon went online in 1994. Netscape's Mosaic browser, the first of many browsers to come, and the server-side Netscape Enterprise Server appeared that same year. Bill Gates wrote his famous memo, The Internet Tidal Wave, in 1995 in which he stated that "the Internet is the most important single development to come along since the IBM PC was introduced in 1981…. Amazingly it is easier to find information on the Web than it is to find information on the Microsoft Corporate Network." Interestingly, a little over two years later, on September 15, 1997, Sergey Brin and Larry Page, Ph.D. students at Stanford University, registered the domain name google.com. To say they saw writing on the wall is an understatement.
Yet, while big companies could afford the enormous expense of establishing a direct connection to the infrastructure that made up the Internet, those that couldn't used an ISP. Some ISPs had their own data centers, but many did not. Instead, they purchased hardware, which they then colocated in an independent data center. As the Internet grew, so did ISPs, and in turn, so did data centers.
Everybody was buying hardware and putting it in data centers, either wholly-owned or collocated in a shared space. Then something amazing happened. Businesses that were spending hundreds of thousands, maybe millions of dollars buying hardware that they hosted in a remote data center, asked two simple questions. The first was, Why are we paying all this money to purchase and support computer hardware that is not core to our business? The second was, Isn't it possible to pay for the computing power we need when we need it? To use a historical analogy, the lightbulb went off. Cloud computing was about to become a reality.
Virtualization paves the way to the cloud
Virtualization made computing as a service possible. Computer virtualization has been possible on mainframes since 1967. The mainframe is, by nature, a very expensive computer. Breaking one mainframe up into several smaller logical machines creates greater operational efficiency. However, in terms of PCs, virtualization didn't make sense. PCs were already considered microcomputers. They offered cost-effective computing on an individual basis. Why reinvent the wheel? But for the folks in finance, it was a different story.
As the PC went mainstream, companies were spending a small fortune on them, and that investment wasn't being fully realized. One box might be operating at 10% capability, doing nothing more than hosting a mail server. Another one might be hosting an FTP server also running at 10%. In such scenarios, companies were paying the full cost of a computer yet utilizing only a fraction of its capacity. You could mix and match applications on a single box, for example, running the mail server and the FTP server on the same computer, but, this was a hazard. If the mail server went down and you had to reboot the box, you lost the FTP server, too. Computer virtualization made it possible for one physical computer to represent any number of logical computers that ran independently and at a better capacity-to-use ratio.
Adding the power of x86 virtualization to the remote data center made computing as a service possible. Throw in virtualization orchestration, which allows virtual machines to be created using automation scripts, and then add in application orchestration technologies such as Kubernetes that enable companies to use data centers to create large scale, highly distributed applications on-demand, and you end up with the modern cloud.
Today the cloud, which has its roots as a collection of PCs installed in a rack in a company's server closet, is becoming the centerpiece of modern application architecture. And, powering it all are thousands of data centers distributed throughout the world. The impact is profound. As Kubernetes evangelist Kelsey Hightower says, "the data center is the computer."
This article is the last installment of the series, The Rise of the Data Center: From Mainframes to The Cloud. We navigated from the first connected mainframe through to today's modern data center. Read other articles from this series:
- A brief history of network connectivity: Connected mainframes
- The rise of connected PCs
- Servers move from the server closet to everywhere
What history of IT architects and system architecture do you want to read about next? Let us know by filling out this form.
About the author
Bob Reselman is a nationally known software developer, system architect, industry analyst, and technical writer/journalist. Over a career that spans 30 years, Bob has worked for companies such as Gateway, Cap Gemini, The Los Angeles Weekly, Edmunds.com and the Academy of Recording Arts and Sciences, to name a few. He has held roles with significant responsibility, including but not limited to, Platform Architect (Consumer) at Gateway, Principal Consultant with Cap Gemini and CTO at the international trade finance company, ItFex.
More like this
Architecting for maintainability: Lessons from a global multicluster platform blueprint
Sovereign by design: Lessons from Red Hat Summit
Container Roundup | Compiler
Untangling Networks | Compiler
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds