
Kubernetes enables you to do a lot of productive work without having to understand a lot about the underlying details. The kubectl command-line interface (CLI) tool and dashboards from OpenShift and other service providers help. However, once you go beyond the high level and look underneath the covers, things can quickly get complex. That complexity can be daunting, even if you're accustomed to working with large-scale business systems.
Still, understanding how the underlying pieces fit together is important knowledge for enterprise architects who use Kubernetes in their designs. Using a building architect analogy, if you're designing a skyscraper, it's useful to know the tensile strength of rebar-reinforced concrete vs. pure steel girders. It's also useful to understand how heating, ventilation, and air conditioning (HVAC) systems work.
The same is true for working with Kubernetes. Just saying, "we'll leave it up to the developers" isn't enough, any more than leaving the choice of an HVAC system up to the construction workers at a building site. Behind every great system design is both a plethora of details and an architect who understands the implications of those details.
For an IT systems architect, one of the more critical details to understand is how Kubernetes creates and runs containers. Understanding container orchestration proves important for two reasons. First, it's good general knowledge for an enterprise architect to have (on the order of construction architects understanding how HVAC systems work). Second, understanding the mechanisms behind how Kubernetes creates and runs containers allows you to create custom configurations for implementing Kubernetes clusters to address special use cases. But, in order to create custom configurations, you need to understand the basics.
This article explains the basics of how Kubernetes creates and runs containers. First, I'll describe Kubernetes' overall architecture for creating and running containers. I'll also discuss kubelet, the piece of software that controls container activities on a Kubernetes worker node. I'll follow up by describing how kubelet works with the container manager to retrieve container images from a container image repository. Finally, I'll discuss how the container runtime gets a container up and running.
This article assumes you have high-level knowledge of Kubernetes as a container orchestration framework and that you understand the basic concepts behind Linux containers. If you want to brush up on the basics of containers, read Red Hat's Getting started with containers documentation. For a fast review of Kubernetes, read Learning Kubernetes basics.
[ You might also be interested in reading An introduction to enterprise Kubernetes. ]
Also, be advised that the terms container manager and container runtime have been used in different ways over the years. I use the two terms in a very specific way, as I'll explain.
Understanding Kubernetes architecture and Kubelet
Kubernetes is a container orchestration framework. The Kubernetes architecture has a control plane made up of one or more computers, virtual or real. The control plane acts as an intermediary between the world outside the cluster and the internal cluster. (A cluster is a collection of one or many computers, virtual or real.) The control plane coordinates the activities of worker computers (virtual or real). These worker computers are called worker nodes. The worker nodes host the containers that make up an application.
Each worker node has a piece of software named kubelet. Kubelet coordinates the work of creating and destroying containers according to configuration information stored in the cluster's control plane. (See the figure below.) The operational sequence is broken into three phases. First, the control plane determines that some containers need to be made. Next, the control plane figures out which worker nodes have the capacity to host the required containers. Finally, the control plane notifies the instance of kubelet running on the relevant worker node(s) to make the containers.
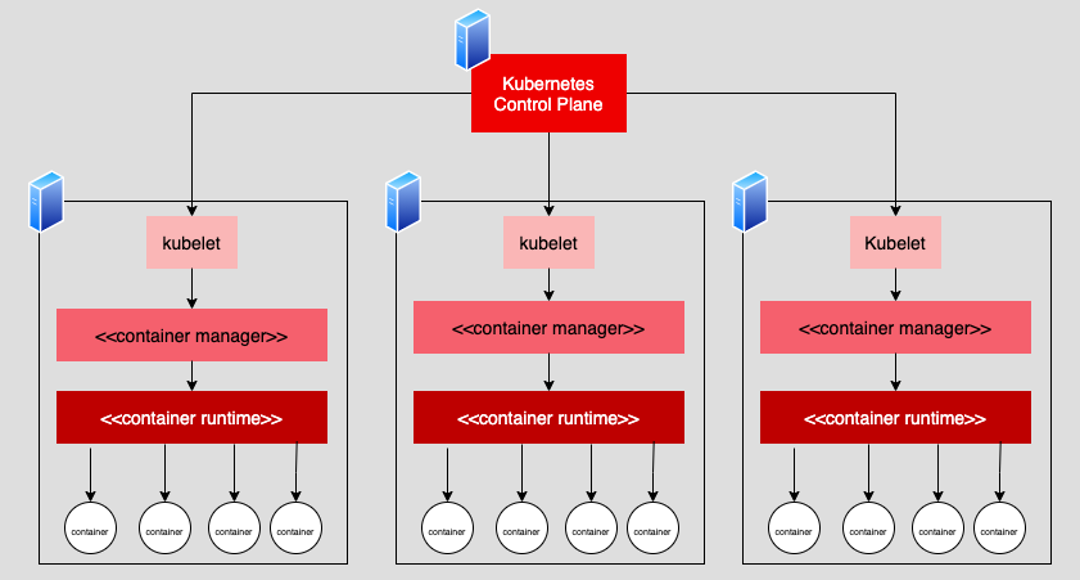
You can think of kubelet as the worker node's supervisor for creating and running a container. It's responsible for making sure the work gets done, but kubelet does not do any of the work itself. The container manager and the container runtime do that work.
Understanding the difference between a container manager and a container runtime
Container creation is divided into two types of tasks. The first involves getting container images out of a container repository such as Red Hat's Quay.io or Docker Hub. The other task is creating and running containers based on a particular container image.
The container manager handles tasks associated with retrieving and storing container images. Examples of container managers are containerd and CRI-O. Creating and running containers is done by the container runtime, for instance, runc or Clear Containers. Early on, the container manager and container runtime were shipped in a single component. But, over time, they were separated according to a standard set of specifications published by the Open Container Initiative (OCI). The OCI is an open-governance organization that has "the express purpose of creating open industry standards around container formats and runtimes."
Standardizing the container infrastructure with the OCI
Container managers and container runtimes have been around for a while. FreeBSD jail was an early container manager and container runtime that first appeared around the year 2000. Others followed. Each had its own special way of working, which limited interoperability among the various systems.
Early versions of Kubernetes used Docker container technology by default. Initially, Docker had a monolithic architecture that combined the container manager and container runtime. However, for a variety of reasons, companies manufacturing container technology began to separate the container manager from the container runtime. Docker was making the separation, too. Separating the container manager and the container runtime was done according to standards established by the OCI in 2017.
The OCI publishes three specifications: image, distribution, and runtime. The image specification defines the structure and representation of a container image. The distribution specification defines how container managers are supposed to get container images to repositories and then onto target environments. The runtime specification describes how container runtimes take a container image and realize it as a running container.

Standardizing these three aspects of container activity into a generic specification makes transportability and interoperability between platforms and environments possible. A developer creates an OCI-compliant container image that's stored on any OCI-compliant repository, such as Red Hat's Quay.io or Docker Hub. Then that container image can be pulled down by a container manager, such as containerd, onto a target destination and run by any OCI-compliant container runtime, for example, runc or gVisor.
The OCI specification puts container technologies on a level playing field. The nature of the specification makes innovation easier. Any new project that supports the OCI spec can be absorbed into the container ecosystem in a standardized manner. An analogy is the railway system. Standardizing the width between rails in a railway system (the rail gauge) makes it so that any manufacturer that supports the standard gauge can run its trains on the system. It doesn't matter if the train is driven by a steam-powered locomotive or an electric one. The specification makes variety possible.
Standardizing container technology opens the door that allows any of a variety of container managers and container runtimes to be used by Kubernetes. The interoperation between the container manager and the container runtime is specified according to the OCI. This is good. But, in terms of the evolution of Kubernetes, there was still an outstanding issue: creating a generic way for Kubernetes to interoperate with container managers. The Container Runtime Interface (CRI) solves this problem.
Understanding the Container Runtime Interface
The CRI is a generic model for creating container managers that can run under Kubernetes. It appeared in Kubernetes with version 1.5 in 2015. The CRI is more than a specification. It is a programming interface written for protocol buffers and gRPC. The CRI is separated into two parts. One part is the ImageService. The other part is the RuntimeService.

The ImageService is the interface that applies to the concerns of the container manager. The RuntimeService is the interface that applies to the concerns of the container runtime.
As with any programming interface, the CRI describes the methods for working with container managers and container runtimes, but not how this is supposed to happen. The "how" is in the programmer's domain and the programming language. Sometimes the "how" in a real-world implementation under Kubernetes can get fairly complex, particularly when adding Kubernetes networking, which is defined by yet another specification: the Container Networking Interface (CNI).
The figure below illustrates the implementation of a Kubernetes worker node using the container manager, containerd, and the container runtime, runc.

As you can see, Kubernetes has complexity that's required to make things easier at the higher levels. But there is a significant benefit to it all.
The benefit of understanding the details
Putting the CRI and the OCI specifications together makes it so that Kubernetes can support exactly the container manager and runtime you want to use in your Kubernetes cluster designs. Also, the CRI and the OCI make it so that you can run many different types of container managers and container runtimes across a single cluster.
The benefit of it all is that the flexibility that the CRI and OCI provide allows architects to create Kubernetes architectures designed for specific use cases. Needs vary, and thus, so too do the container manager and runtime best suited to meet the need at hand. For example, using a native container runtime such as runc is a good choice for an application with containerized processes that executes in milliseconds and needs to load and exit fast. runc uses the host machine's kernel, thus yielding optimal performance.
On the other hand, an application that needs to support a security policy requiring that a container can never get access to the host machine's kernel will do well running on a Kubernetes node with Kata Containers installed. Kata Containers is an open source container runtime that fires up the container in its own quasi virtual machine, thus isolating it from the host VM.
Again, the nice thing about the standardization that OCI and CRI specifications provide is that they enable a good deal of flexibility around container-manager and container-runtime configuration under Kubernetes. This is a significant benefit. Note that more than one runtime can be used within the same cluster. For example, OpenShift uses the default runc, but when sandboxed containers are enabled, Kata Containers can be run in the same cluster.
Putting it all together
When it comes to designing a Kubernetes infrastructure to support today's modern applications, choice matters. Fortunately, choice exists due to the benefits provided by the OCI and CRI specifications. The tradeoff is the need to understand many details of Kubernetes and container technology to get it all to work for your benefit.
From an architectural perspective, the important thing to recognize about this complexity is that the time it takes to understand the details of how containers are created and run under Kubernetes is worth it. You need to know a lot, but the payoff is that you get to do a lot in a very flexible manner.
About the author
Bob Reselman is a nationally known software developer, system architect, industry analyst, and technical writer/journalist. Over a career that spans 30 years, Bob has worked for companies such as Gateway, Cap Gemini, The Los Angeles Weekly, Edmunds.com and the Academy of Recording Arts and Sciences, to name a few. He has held roles with significant responsibility, including but not limited to, Platform Architect (Consumer) at Gateway, Principal Consultant with Cap Gemini and CTO at the international trade finance company, ItFex.
More like this
Can't patch fast enough? Zero trust as a last line of defense
What's new with image builder for Red Hat Enterprise Linux 10.2 and 9.8
Container Roundup | Compiler
The Containers_Derby | Command Line Heroes
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds