
The IBM CIO Hybrid Cloud Platform team is working on a major cloud transformation project. The team is building a hybrid cloud platform for the entire internal infrastructure using Red Hat technology, aiming to have a modern platform promoting agility, innovation, and efficiency while reducing operational costs.
Implementing a hybrid cloud platform has clear benefits, but operating this new platform creates new complexities. Virtual machines can become hundreds of pods and containers. Monolithic applications can transform into a complicated set of smaller independent components. And you can no longer troubleshoot a small number of servers and components to diagnose performance problems. In this more complex scenario, the answer to finding root causes and identifying how components flow across different regions and clusters is observability.
[ Discover ways enterprise architects can map and implement modern IT strategy with a hybrid cloud strategy. ]
This article discusses how we developed an observability strategy to support the organization's hybrid cloud journey, some lessons learned, and the results of the platform adoption from an observability perspective.
Designing an observability strategy
The first step in designing an observability strategy for this new hybrid cloud platform was to evaluate the size of the task. After this evaluation, we could decide the best way to implement the design.
After defining the organization's strategy, main requirements, resources, and budget for the project, the team organized to develop the hybrid cloud transformation's observability strategy.
The observability target is to support the IBM CIO Hybrid Cloud organization in its hybrid cloud transformation. Specifically, it's to help the organization manage the new, complex infrastructure; reduce operations efforts; improve application and infrastructure reliability, performance, efficiency; and contribute data-driven strategies.
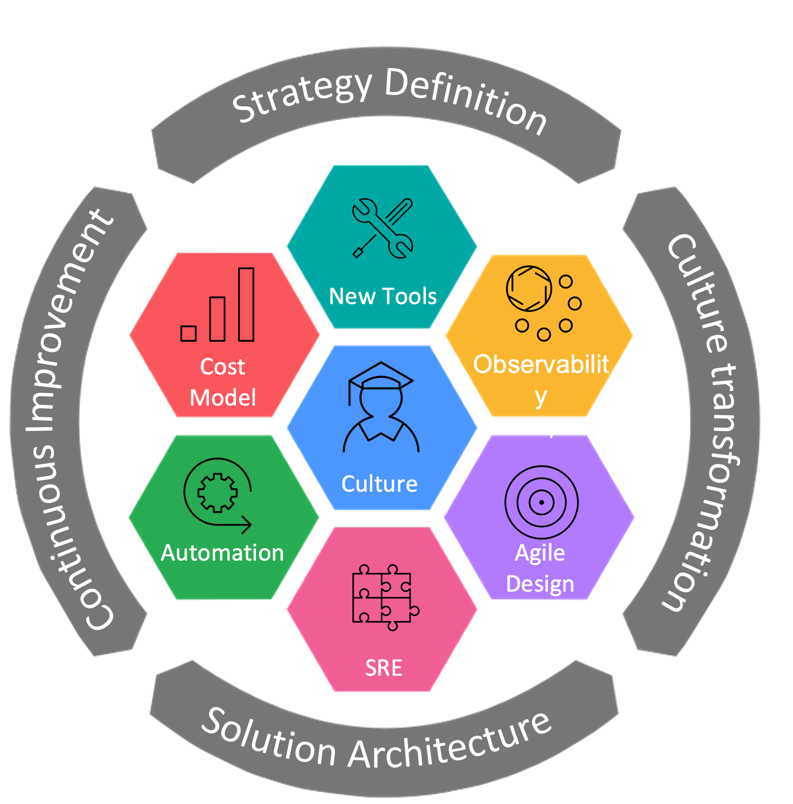
We based our definitions on the following functional requirements:
- Define observability targets for all applications using Site Reliability Engineering (SRE) four golden signals. This helps designate monitoring maturity levels to assess how well the team is doing.
- Use existing tools to reduce internal development as much as possible. The wisdom of this early decision was reinforced after some frustrating attempts to develop internal solutions.
- The observability solutions must cover the new hybrid cloud and existing legacy platforms. This provides full observability for applications that, for example, are on the hybrid cloud but access data on mainframe systems.
- Funding comes from the organization rather than using internal cost recovery. Initially, funding was through cost recovery by charging teams for the new tools. But this proved to be a poor way to expand observability because some teams declined due to the cost.
- There are two observability solution options: self-service and consumption-as-a-service. This was another important decision because some teams prefer to take care of their own monitoring configuration while others don't have sufficient knowledge and want another team do it for them.
Supporting cultural transformation
Observability is not only about using tools to provide more visibility into systems. It can also completely change how teams work. Observability puts more focus on the application layer than infrastructure, which changes the perception of urgency. Sometimes it's not critical when an infrastructure component is down, but high latency on a system is always important. If this happens, the team shouldn't need to go server by server to investigate a problem. They can check the observability solution and extract all the information they need.
For this reason, we invested significant time creating documentation, videos, knowledge-transfer sessions, training, and quickstarts to help teams reach their observability targets.
[ Create an organizational culture that fosters innovation and keeps teams unified. Download The IT executive's guide to building open teams. ]
Defining the solution design and architecture
To have an open and live architecture to promote innovation and best practices, we update the architecture based on new market offerings and customer needs.
As the architecture reference diagram below shows, the target is to have an environment that merges proprietary agents with generic agents (OpenTelemetry) or manual instrumentation to avoid vendor lock-in. Another important idea here is to have a solution to manage the API calls to tools and to add a security layer for external entities to access data. We also want to provide a workflow solution to orchestrate all interactions and a database to maintain the important static external data required to create dashboards.
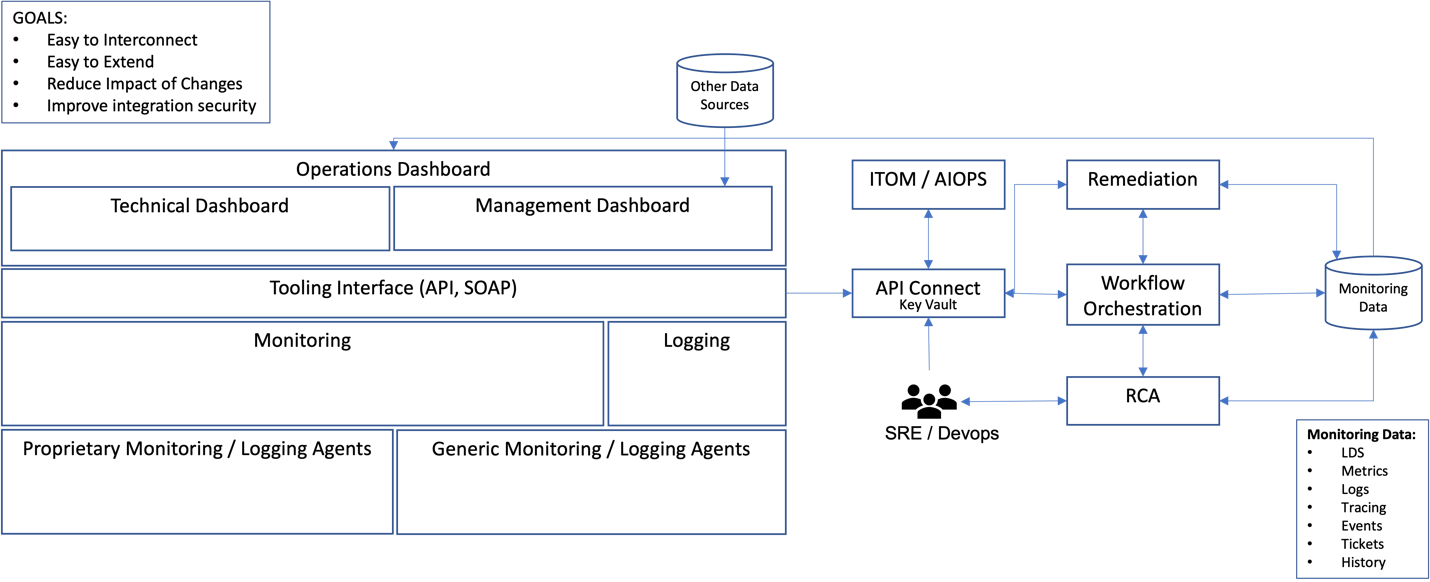
[ Check out Red Hat's Portfolio Architecture Center for a wide variety of reference architectures you can use. ]
Functional requirements
The solution must:
- Define all tools required to cover the requirements
- Provide application performance management (APM), synthetic performance monitoring, real-user monitoring (RUM), and logging solutions for heterogeneous environments
- Integrate all tools as a single observability solution
- Notify the relevant teams when a problem happens
- Automate infrastructure issues as much as possible
- Manage infrastructure resources efficiently
Important architecture decisions
The solution will:
- Implement hybrid solutions (SaaS and on-premises) but prioritize SaaS solutions where it fits
- Balance multitenant and single-tenant use with role-based access controls
- Avoid creating new infrastructure components as much as possible, and set any that must be created to be highly available
- Not migrate legacy components or tools that will be decommissioned soon
Summarizing our observability solution
The following diagram summarizes the observability solution. It starts with onboarding the application and passes through application data collection. It then makes infrastructure optimization suggestions, and finally, delivers all the observability benefits.
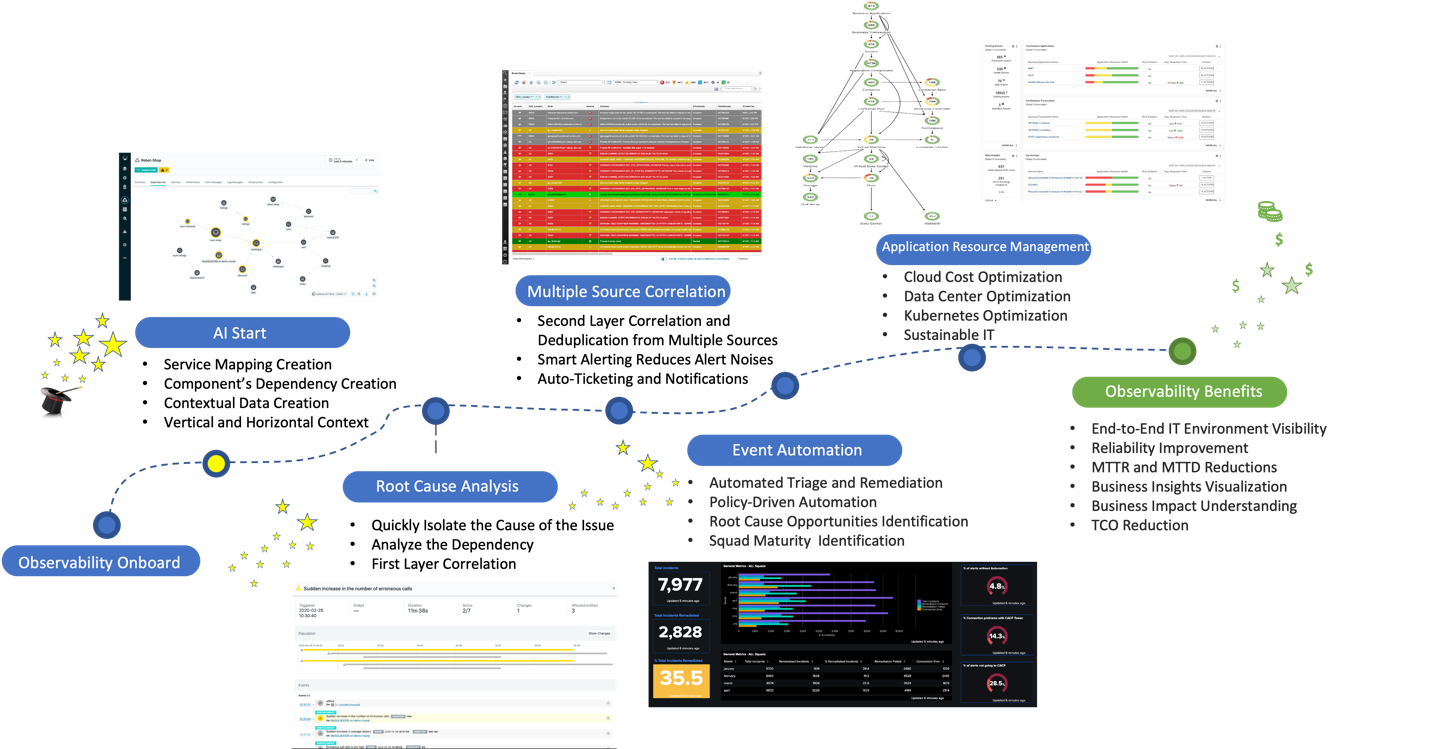
The workflow below shows the observability solution interactions. APM tools (Instana) get all the application and infrastructure data. Each tool processes all the data to create topologies and tracings, improve root-cause analysis (RCA), identify issues, and send data to the logging tool for dashboarding. It also sends alerts to IT operations management and IT service management tools for event correlation, ticketing, event automation (Ansible), and user notification. Finally, it sends data to the ARM solution (Turbonomic), and supports the application and platform teams to use the infrastructure with greater efficiency and lower hosting costs.

Reviewing our results
We reduced operational effort by providing:
- An easy way to identify dependencies
- Automation with RCA details where required
- Automatic diagnoses and RCA through artificial intelligence (AI)
- Fewer tickets by correlating and contextualizing them
We improved customer experience by:
- Resolving critical business issues faster
- Delivering better applications by analyzing their performance
- Supporting the need to implement new features and find problems in real-time
- Identifying and fixing performance problems before the user experience is impacted
We improved business visibility with:
- Centralizing information about application dependencies
- Centralizing information for dashboards and reports
- Identifying and quantifying issues with high business impact
[ Learn how to build a flexible foundation for your organization. Download An architect's guide to multicloud infrastructure. ]
Evolving the observability solution
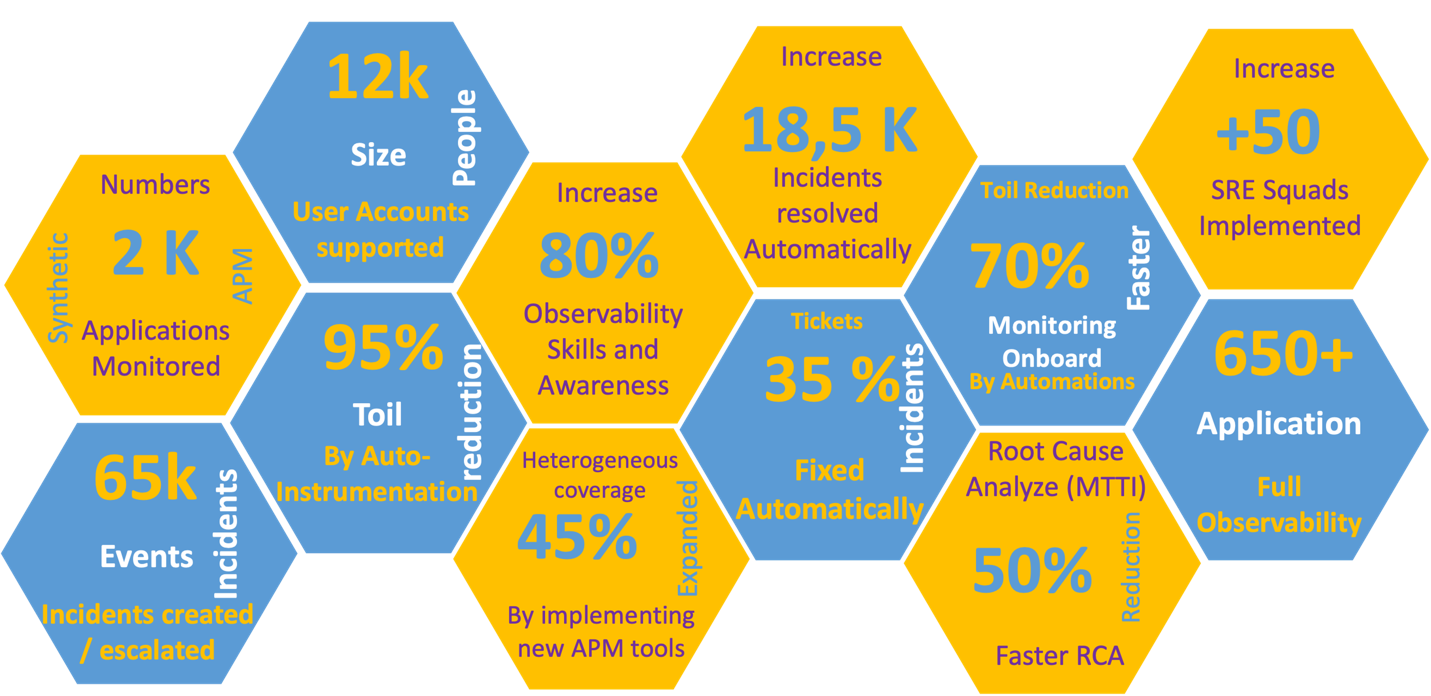
Rather than deploying the entire observability solution at once, it evolved incrementally. As the image below shows, it started with infrastructure monitoring, then added application availability monitoring, heterogeneous application monitoring, SRE, and finally SRE + AIOps.

The observability solution was very successful. The team is monitoring 2,000 applications, supports 12,000 user accounts, resolved 18,500 incidents automatically, and has full observability into more than 650 applications.
Conclusion
Observability is an important piece of hybrid cloud strategy and can make the journey into improving services easier and more exciting. It helps connect the dots of complex hybrid solutions, providing intelligence, visibility, and efficiency for infrastructure and applications spread across different technologies and platforms.
Having a good understanding of the organization's strategy, main requirements, and operational models can guide you to create a well-designed architecture with the best tools and solutions. Building an excellent technical solution and having organizational support to transform the culture are necessary ingredients for a successful observability project.
This originally appeared as Producing observability design to support a hybrid cloud strategy on Hybrid Cloud How-Tos and is republished with permission.
About the author
Tiago is a Distinguished IT Architect | Senior SRE | IBM Master Inventor specializing in Observability Strategy and Solution Design with 20+ years of experience helping organizations strategize complex IT solutions.
More like this
Debunking IT automation myths: A strategic blueprint for healthcare payers
Introducing Red Hat build of Karpenter
Untangling Networks | Compiler
Operating System Management | Compiler
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds