
Kubernetes (K8s) is a popular technology for running distributed, container-based internet applications. Many companies that have experienced success with Kubernetes are expanding their utilization of it.
The adoption path for K8s is familiar: A company starts by experimenting with a cluster containing a small number of nodes. Then it takes on some projects that are a bit bigger, requiring a cluster with more nodes. Eventually, the company goes all-in and spins up a web-scale cluster that might have hundreds (if not thousands) of nodes in a single datacenter.
But the adoption path doesn't stop there. As a company's Kubernetes use matures, the next step is a multi-cluster implementation. Instead of running an application on a single cluster, the company expands and unifies its distributed architecture across multiple clusters. Sometimes those clusters are hosted in the same datacenter. Sometimes they're not. And, in such cases, not only will the clusters be distributed over multiple datacenters, but those datacenters can be located anywhere on the planet.
Yet, as powerful and versatile as multi-cluster Kubernetes architectures are, they come with complexity and tradeoffs. You need to know a thing or two about the details of implementing a multi-cluster Kubernetes infrastructure to create an enterprise architecture that's going to work for the business.
To walk in blind is a risk.
Thus, in this article, I explain some high-level details for how a multi-cluster Kubernetes installation works. Also, I'll discuss a typical use case and examine some of the tradeoffs that the use cases present. I'll do this by answering three questions:
- What is a multi-cluster Kubernetes architecture?
- Why would I want to use a multi-cluster architecture?
- What are the challenges that go with using a multi-cluster architecture?
What is a multi-cluster Kubernetes architecture?
A multi-cluster Kubernetes infrastructure is, as the name implies, a collection of Kubernetes clusters that can work together to fulfill a set of business requirements. A cluster is a collection of nodes. A node can be a real or virtual computer. There are two types of nodes in a cluster: A central controller node and worker nodes. The control node manages the state of the cluster. The worker nodes do the actual computing work by running containers that execute the computational logic.
Users, either human or logical, interact with a cluster through Kubernetes services configured within the cluster. A service is represented by an IP address. You can think of a service as a representation of programming logic. You can think of a cluster as a very big computer. A term commonly used among those familiar with Kubernetes is that the cluster is the computer.
[ Compare Red Hat OpenShift and Kubernetes ... what's the difference? ]
Thus, you can think of a multi-cluster Kubernetes infrastructure as a collection of very big computers. And as with computers in the real world, a cluster has a security management system that enables access to authorized users and services. Typically (but not always), a cluster is located in a particular geography based on the datacenter hosting the physical servers.

Now, it gets interesting because there are various ways to design a multi-cluster Kubernetes architecture. For example, you can have cluster redundancy architecture in which clusters are exact replicas of each other. This is demonstrated in the figure above by the two US clusters on the left side of the diagram.
Another architectural design combines clusters over multiple geographies, such as the US-EU configuration shown above. Notice that services within the US-WEST and US-EAST clusters use a service published by the EU-WEST cluster.
There are other types of designs as well. The important thing to understand about a multi-cluster Kubernetes architecture is that each cluster is independent. The given cluster controls its internals distinctly in terms of container provisioning and service configuration. Also, each cluster has its own security schema in force. This type of independent segmentation brings a lot of versatility, but it also incurs a higher overhead in terms of management. I'll examine these tradeoffs below. First, though, I'll talk about the reasons for using a multi-cluster Kubernetes architecture.
Why would I want to use a multi-cluster architecture?
There are a variety of reasons for implementing a multi-cluster Kubernetes architecture. Some of the more common are:
- Efficient resource utilization
- Segmentation vs. replication architectural design
- Regulatory considerations
I'll look at the details of each:
Efficient resource utilization
The value of a multi-cluster Kubernetes architecture is that you can assign a cluster to a datacenter according to performance requirements. For example, suppose you have an application in which certain services need to support low latency and fast execution on the backend. In that case, you can deploy those services to a cluster in a datacenter nearby and host the code on high-performance machines.
However, if some of the application's services don't need to run lightning quick and you want to avoid the price premium that goes with using high-end machines, using a datacenter with machines with less horsepower is a viable option. You won't get neck-breaking performance, but you won't be incurring extraordinary costs either.
Of course, there is a good argument to be made that a single-cluster architecture can support both high-performance and low-performance machines using Kubernetes node affinity. But, taking a single-cluster approach using node affinity assumes that the datacenter has a wide variety of machines, either virtual or real, on hand. This is not always the case. On the other hand, in a multi-cluster architecture, you can choose the best environment for the need at hand without a lot of fiddling with node allocation configuration.
Segmentation vs. replication architectural design
Taking the notion of resource utilization a bit further, a multi-cluster Kubernetes infrastructure allows architects to choose between segmentation and replication architectures. In a segmentation architecture, an application gets separated into independent components, each typically represented as a Kubernetes service.
Services in a segmented architecture get allocated to clusters according to operational requirements. Then, the application architecture is such that services interact with each other across clusters.
The figure below (which is an excerpt of the first figure) is an example of a segmentation architecture. Notice that Service B in the US-EAST cluster on the left uses Service D in the EU-WEST cluster on the right. (Why you'd want to segment across transnational boundaries is discussed in Regulatory considerations.)

The segmentation approach to multi-cluster application architecture provides the loose coupling seen in microservice-oriented architectures. As with a microservice-oriented architecture, a multi-cluster architecture gives you the benefit of independence in terms of development and maintenance.
The other approach to multi-cluster architecture is replication. In a replication scenario, exact copies of a cluster are hosted in many datacenters. The figure below illustrates identical clusters hosted in two datacenters, one in US-WEST and the other in US-EAST. Traffic gets routed by a Load Balancer configured to redirect a request based on its originating location.
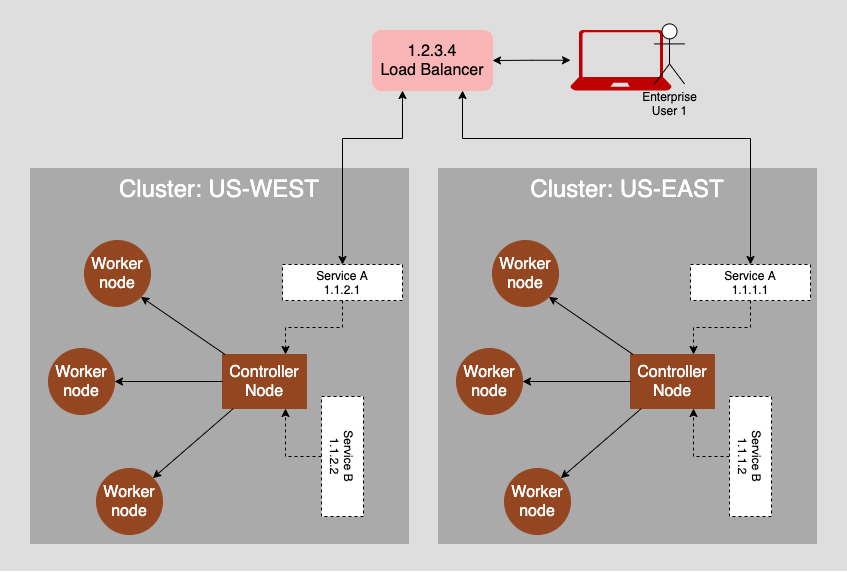
The benefits of using a multi-cluster Kubernetes architecture to replicate application instances across datacenters are performance and resiliency. Routing traffic in close proximity between user and application is an intrinsic performance benefit. The closer a user is to the datacenter, the faster the bits move back and forth.
[ For more insight, download An architect's guide to multicloud infrastructure. ]
In terms of resilience, it's a sad fact of life that datacenters do go offline. If the cable into the datacenter is severed, the solution is beyond the implementation capabilities. Kubernetes is powerful, but it's not magical. In such a catastrophic outage, having a replica of the cluster in another datacenter is a wise design choice.
Regulatory considerations
Another key benefit of a multi-cluster Kubernetes architecture is that it allows applications to enforce regulatory compliance over multinational domains.
One of the big challenges in distributed computing is ensuring that an application complies with the regulatory statutes where the application runs. For example, the European Union's General Data Protection Regulation (GDPR) requires that, by default, all the data for an EU customer remain physically in the European Union. For a company that is local to the EU alone, a single-cluster Kubernetes will do. But, if the company is a transnational company, for example, a website that shows movies to a worldwide base of subscribers, you must store the subscriber data in the country of origin. A multi-cluster Kubernetes architecture is well suited to this type of scenario.
What are the challenges that go with using a multi-cluster architecture?
The essential challenge that goes with using a multi-cluster Kubernetes architecture is managing the added complexity that goes with the architecture. The added complexity takes many forms. The sections below describe a few of them.
Security
In a multi-cluster Kubernetes architecture, the security considerations are daunting. Each cluster has its own set of roles and security certificates to support. These certificates need to be managed across datacenters and clusters. This means having some sort of multi-cluster certificate management system in force. It also means that system admins and security personnel will have to pay more attention to role and user creation on a cross-cluster basis. Doing this work is essential in order to support a secure, multi-cluster implementation of Kubernetes.
[Download this free whitepaper to learn how to take a layered approach to container and Kubernetes security. ]
Firewall configuration
Then there's the matter of firewalls. In a single-cluster setup, you only need to access a single Kubernetes API server at a particular address. In a multi-cluster setup, you're accessing a number of API servers. In such a case, it's not a matter of just spinning up a new cluster. You have to spin up a new cluster and ensure that access to the cluster's API server is available to other interested clusters through the firewall. It's added work, and it's ongoing work. Of course, you can add intelligence to the automation scripts to address the access issues, but that increases the complexity of the scripts. As they say in the trade, there's no such thing as a free lunch.
Deployment
Kubernetes architecture deployments become more complex in multi-clusters, particularly at the GitOps level. The "one ring to rule them all" pattern that is emblematic of GitOps enhances the speed and agility of deploying large-scale enterprise applications. But, in a multi-cluster Kubernetes, that one ring will have to be very smart and powerful.
Remember, in the GitOps way of life, the source code management (SCM) service becomes the central controller for all deployment activity. This means giving added attention to how you organize the various repositories within the SCM service. It also means keeping track of all those manifest files and ensuring you securely manage the required access credentials. The risks can be significant. One faulty check-in to the SCM by a developer can bring down a cluster, or where you've implemented replication across clusters, several clusters. The dangers are real.
However, even though the added complexity can be a challenge, it's a challenge worth accepting in many cases, given the benefits that a multi-cluster architecture can provide.
IT is a complex profession. IT professionals deal with a plethora of details every day. Complexity goes with the territory. It's not something to be shied away from. If there's a compelling benefit, addressing the inherent complexities of a multi-cluster Kubernetes architecture can be an acceptable cost of doing business. The key is that the benefits need to be compelling enough to outweigh the costs incurred.
Putting it all together
Multi-cluster architectures are important in the evolution of Kubernetes. They offer a way to design applications that can operate across a variety of datacenters in a versatile yet controlled manner. Also, they provide added resiliency for applications running at the enterprise level.
But, multi-cluster implementations come with a basic tradeoff: they're more complex. Thus, companies that want to take advantage of the benefits that a multi-cluster Kubernetes architecture offers will do well to anticipate added costs in terms of adoption and maintenance. However, you can offset these costs by taking the time to research tools, techniques, and services that make working with multi-cluster architectures easier.
A multi-cluster Kubernetes architecture has a lot to offer enterprise architects. They're complex, but the complexity provides the benefit of versatility and resiliency for large-scale enterprise applications that operate globally. Taking the time to learn more about the details of multi-cluster Kubernetes implementations is a good investment for architects that plan to take full advantage of all that Kubernetes has to offer.
About the author
Bob Reselman is a nationally known software developer, system architect, industry analyst, and technical writer/journalist. Over a career that spans 30 years, Bob has worked for companies such as Gateway, Cap Gemini, The Los Angeles Weekly, Edmunds.com and the Academy of Recording Arts and Sciences, to name a few. He has held roles with significant responsibility, including but not limited to, Platform Architect (Consumer) at Gateway, Principal Consultant with Cap Gemini and CTO at the international trade finance company, ItFex.
More like this
Gain stronger pod isolation on Microsoft Azure Red Hat OpenShift with OpenShift sandboxed containers
The value of unconventional experience: From sweeping hair to shaping careers
Scaling with Orchestrators | Compiler
Container Roundup | Compiler
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds