
To properly size a recently built Red Hat OpenShift Container Platform (OCP) cluster, you need to have information about your hardware components. These pieces of information should be gathered before you add any additional or custom workloads, such as base OCP components and OCP Operators such as ODF, Quay registry, Advanced Cluster Management (ACM), and Advanced Cluster Security (ACS). In this article, I'll demonstrate how to find this information.
[ Learn more about automating your container orchestration platform in the Kubernetes Operators eBook. ]
Key definitions
One of the first concepts to understand when measuring resources in Kubernetes and OCP is how CPU power is accounted for. CPU processing power in Kubernetes and OCP is measured in millicores. One thousand millicores is related to one thread. For example, I have a test server with four physical cores, or eight threads. OCP detects this server as having 7,500 millicores available (a little bit is subtracted for overhead).

Here are some related terms to understand:
- CPU requests: This is the minimum amount of CPU resources (in millicores) allocated to a pod or container.
- Memory requests: This is the minimum amount of memory allocated to a pod or container.
- CPU limits: This is the maximum amount of CPU resources (in millicores) allocated to a pod or container. This must be set to prevent a process from consuming too much CPU, which may cause another workload not to schedule or to fail.
- Memory limits: This is the minimum amount of memory resources allocated to a pod or container. This must be set to prevent a process from consuming too much memory, which may cause another workload not to schedule or to fail.
- Storage: In regard to node-level storage, enough storage must be available to account for ephemeral (non-permanent) storage. This isn't typically a problem.
How to view OCP usage data
There are multiple ways to view usage information, using various commands and tools.
oc adm top command
The oc adm top command has a few flags to help with capacity planning. The pod and node output is very useful. This command shows current utilization.
From the command line, try the following three commands:
oc adm top nodes
This output shows that I am running a single-node OpenShift (SNO) cluster. I am using 1,200 millicores (1.2 threads) which is approximately 16% of my total CPU processing power (for the total of eight threads on my node). Memory usage is 17.044GB, which is approximately 55% of my total cluster (32GB of RAM).
This command is scoped based on the current namespace or project you are in:
oc adm top podsTo run across all namespaces and do some sorting based on CPU utilization, run:
oc adm top pods -A|sort -n +2
In this output, the third column is CPU utilization. The bottom of the list shows the highest CPU usage among pods in all namespaces or projects. For example, the kube-apiserver pod is currently using 133 millicores (0.133 threads).
To observe across all namespaces and do some sorting based on memory utilization, run:
oc adm top pods -A|sort -n +3
The highest usage (by memory) in my environment is an Elasticsearch pod that runs as part of my drivetester website. It is currently using 3.170GB of memory.
Another neat way to view pod utilization in each namespace is to run:
for project in `oc get project|grep -v NAME`; \
do echo $project; \
oc project $project 2> /dev/null; \
oc adm top pods; \
done;This will go to each project and show the usage of all pods in that project. I'm using a project called Analyzer in this example.

[ Want Red Hat OpenShift Service on AWS (ROSA) explained? Watch this series of videos to get the most out of ROSA. ]
oc describe node command
This command will show some key pieces of information at the node level. I'll provide some relevant output based on the oc describe node command. For the sake of clarity, I will break this down into different sections and explain.
Capacity
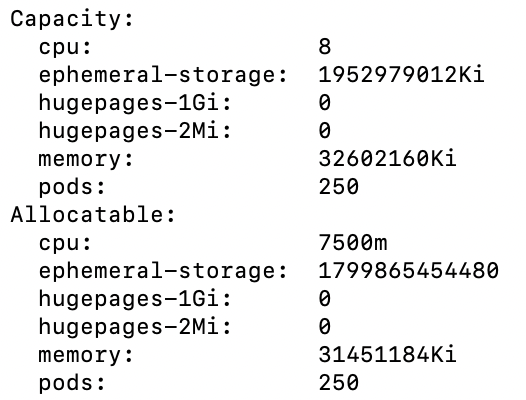
In the capacity section:
- The total amount of CPU power is 8 threads.
- The amount of ephemeral storage (
/var/lib/storage/containers) is approximately 195GB. - Hugepages is not enabled.
- Total memory is 32GB on the node.
- The maximum number of pods that are allowed to run by default on the node is 250. Changing this is possible but out of the scope of this article.
Allocation
The Allocatable section is similar to capacity, but there is a little overhead subtracted based on some system processes (mostly kubelet) that run on the node. This output shows the pods that are running on the node and lists the CPU, memory request, and limit information.

This is another view of similar information but based on the total node data.

[ Learn how to build a flexible foundation for your organization. Download An architect's guide to multicloud infrastructure ]
View metrics in Grafana
To visualize your data, on the OpenShift Web Console, go to the Observe > Dashboards menu.
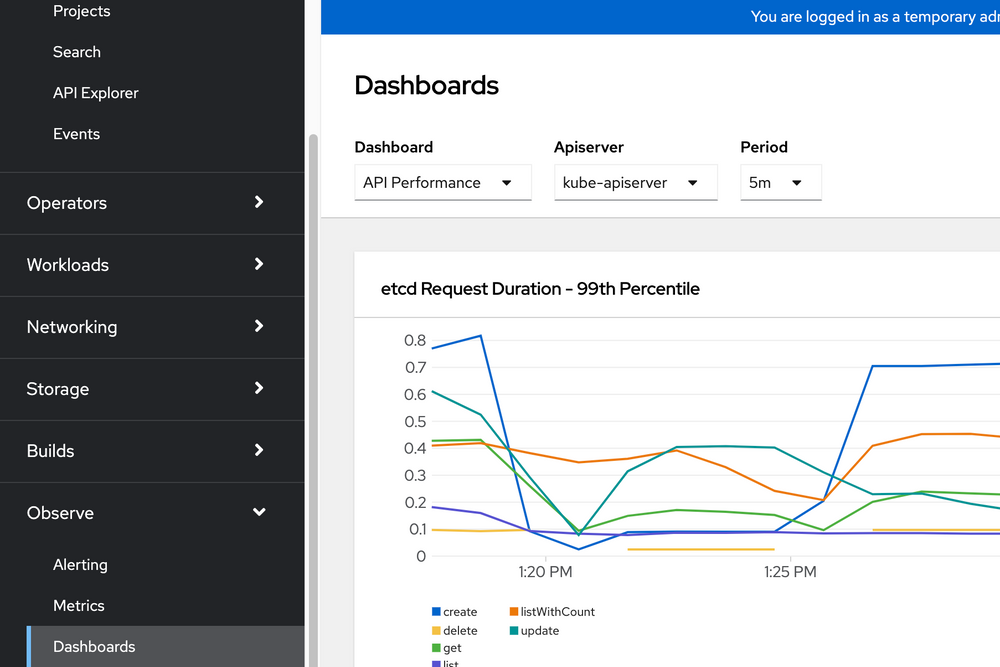
There are several default dashboards that show the information you need. For Dashboards (middle of the screen), select Kubernetes > Compute Resources > Cluster. The top of the screen shows a wealth of information at the cluster-wide level.

Under the CPU section, you can hover over the chart to see a breakdown of CPU usage by project.
Other dashboards will show a similar graph at the node level and also allow you to view data at a per-namespace level.
Visualize data in Prometheus
OpenShift includes built-in queries that you can run to visualize the output of the metrics in yet another way.
On the OpenShift Web Console, go to Metrics within the Observe menu. The drop-down menu Insert metric at cursor includes many prepopulated queries.
For demonstration purposes, this demo looks only at memory and CPU data. The drop-down menu allows you to search for queries that match a keyword.
Here's what happens when I type memory:
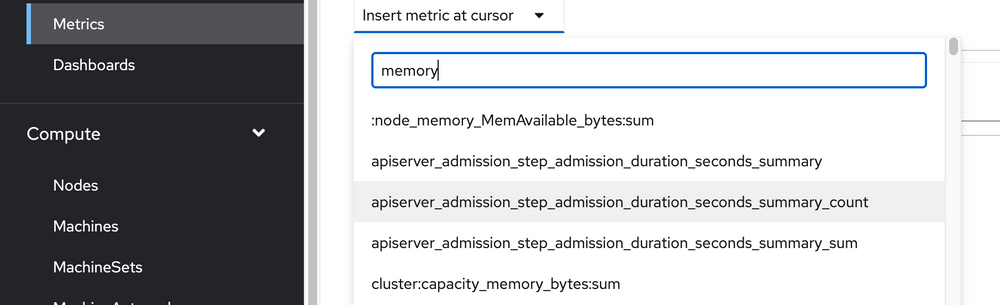
This shows all of the different queries that you can run based on that keyword. For this example, I'll use:
namespace:container_memory_usage_bytes:sum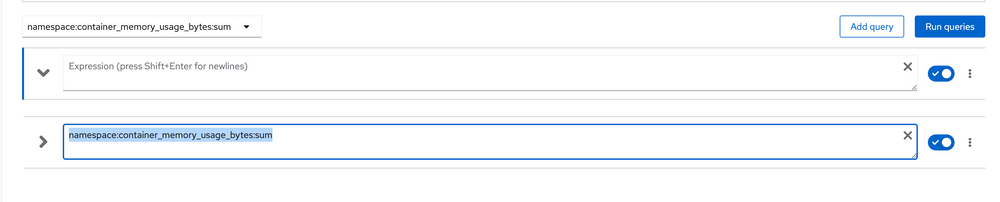
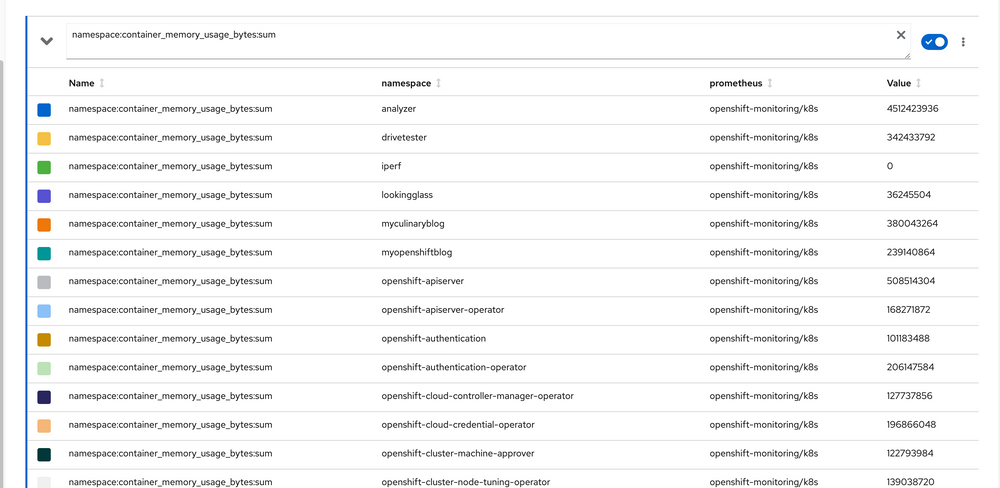
You can add this query to the window for frequent use, or you can just run the query. This presents the output by namespace in a table-like view:
Compute > Nodes
On the web console, Compute > Nodes provides a high-level view of each node's resource utilization. This is similar to the output from oc adm top nodes.
When a node is oversubscribed (based on current utilization or limits too high), clicking on the node name on this screen shows a breakdown of the pods causing the issue.

Put everything together
On my cluster, I have a few different workloads running along with the base OCP. Also, this is a SNO install. To calculate specific information on memory and CPU for OCP base components alone (including any Operators that are needed), I would use a combination of the processes above.
The namespaces for most base OCP components contain "openshift" in the name. Some exceptions are the default namespace and anything that starts with "kube."
To present this in a nice spreadsheet-style report, I need the following information to calculate the resources available to run any custom workloads.
- Current utilization for memory/CPU
- Memory/CPU requests
- Memory/CPU limits
Since this is a single-node cluster, I could just look at the current utilization and subtract this from the total resources available on the node. But this doesn't account for workloads or pods that can increase in memory or CPU utilization up to any limits that are set.
I use a combination of these methods to put info into a spreadsheet. It is a little messy but a good exercise.
First, I use the Prometheus query to gather all information. I used the following queries:
namespace:container_memory_usage_bytes:sum
namespace_memory:kube_pod_container_resource_limits:sum
namespace_memory:kube_pod_container_resource_requests:sum
namespace:container_cpu_usage:sum
namespace_memory:kube_cpu_container_resource_limits:sum
namespace_memory:kube_cpu_container_resource_requests:sumSince the Prometheus query presents the output in a table-like format, I can copy and paste this information into a text file. Assuming this was run before any workloads were added to the system, I can take all the output and massage it to a presentable format, such as the example below, which is based on a different cluster.
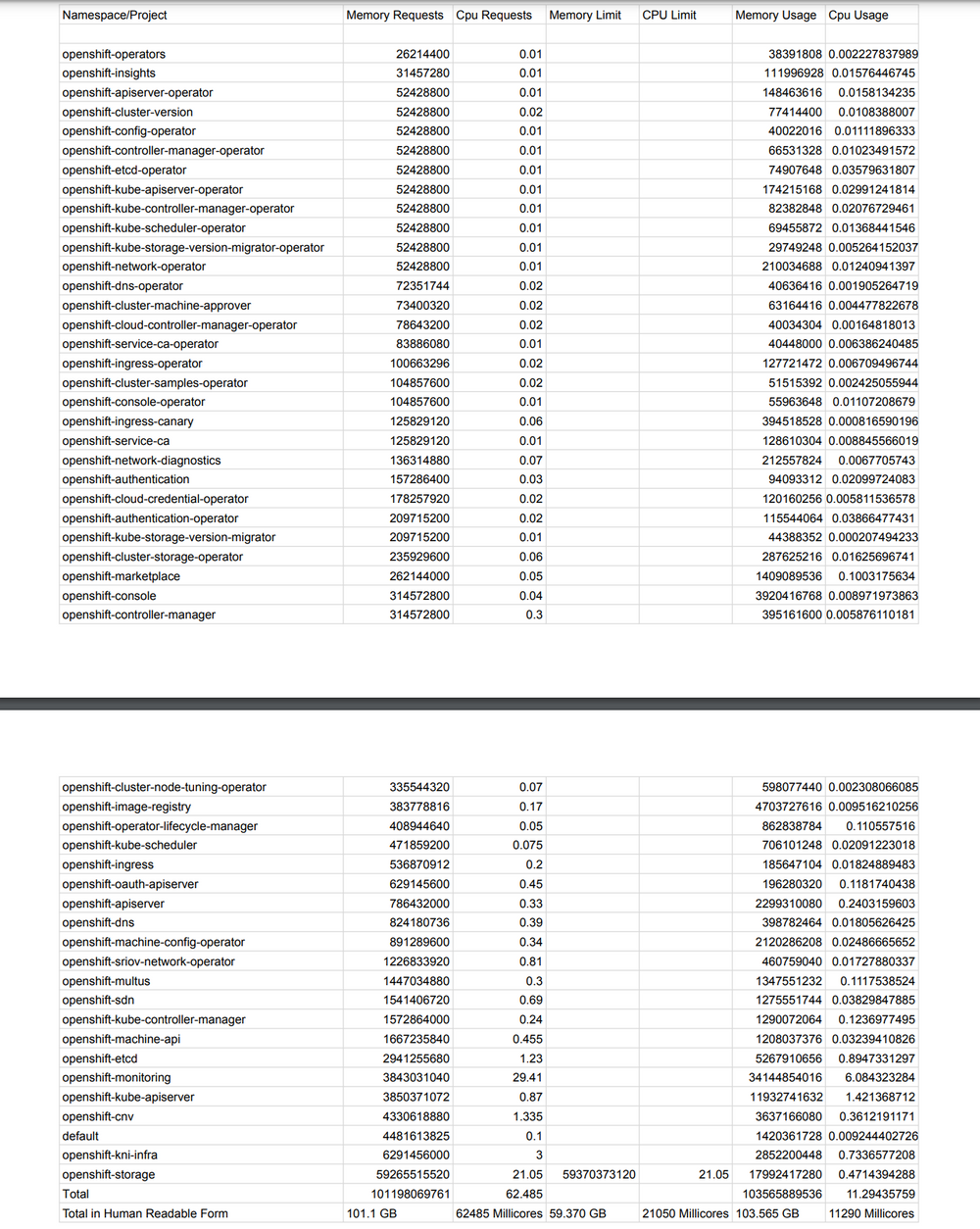
In the output of this cluster, all masters and workers are schedulable, which makes things easier. I can simply subtract the total numbers (listed in the spreadsheet) from the total processing power of all nodes in the cluster.
Assume that there are six master/worker servers each with 128GB of RAM and 32 threads (32,000 millicores) each.
- Total memory available for this configuration: 768GB of RAM
- Total threads: 192,000 millicores
There are no limits set on a majority of the OpenShift namespaces and projects. Since this is the case, you may want to base limits on current utilization and add limits that are set to make available resources lower. ODF is the only limit that is set at 21,050 millicores and 59.370GB of memory. I will add this number.
Based on current utilization, these custom workloads can consume up to the following:
- Memory: 768GB - 103.565GB - 59.370 (limit) = ~605GB available
- CPU: 192,000 millicores - 11,290 millicores - 21,050 millicores (limit) = ~160,000 millicores available
I still recommend keeping resource utilization less than 50%, but this a user preference. Determining the correct threshold is not one size fits all. Deploying fewer servers and keeping utilization high will reduce costs, while deploying more servers with lower utilization can increase stability. You need to set thresholds based on your priorities.
[ Read Hybrid cloud and Kubernetes: A guide to successful architecture ]
This originally appeared on myopenshiftblog and is republished with permission.
About the author
Keith Calligan is an Associate Principal Solutions Architect on the Tiger Team specializing in the Red Hat OpenShift Telco, Media, and Entertainment space. He has approximately 25 years of professional experience in many aspects of IT with an emphasis on operations-type duties. He enjoys spending time with family, traveling, cooking, Amateur Radio, and blogging. Two of his blogging sites are MyOpenshiftBlog and MyCulinaryBlog.
More like this
The evolution of infrastructure automation in the age of AI: 4 key takeaways from Red Hat Summit 2026
From alert fatigue to automated action: Automated patching in the AI era
Untangling Networks | Compiler
Operating System Management | Compiler
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds