



In How we designed a 5G/6G-ready business support system (BSS) for telco operators, we performed a performance analysis with a 5G/6G-ready converged charging system (CCS). We compared using dedicated bare-metal against a common application platform for telecom providers.
In this article, we'll take a closer look at how to optimize the cost (meaning the charges you see on your cloud bill) versus the return on investment (in transactions per second [TPS], or the capacity observed) to calculate a cost-risk analysis of using hyperscaler infrastructure.
[ Learn why open source and 5G are a perfect partnership. ]
OpenShift cluster formation on AWS
OpenShift Virtualization extends OpenShift Container Platform to allow you to host and manage virtualized workloads on the same platform as container-based workloads. From the OpenShift Container Platform web console, you can import a virtual machine (VM), create new or clone existing VMs, perform live migrations between nodes, and more. OpenShift Virtualization can manage Linux and Windows VMs.
This solution covers hybrid workloads (VMs and containers), so we've enriched the sandbox Red Hat OpenShift (self-managed) cluster on AWS with OpenShift Virtualization Operator. To leverage nested virtualization, we had to use EC2 metal instances which are, unfortunately, more expensive.

Converged charging system (CCS) deployment formation
We deployed the i2i Systems CCS solution described in our previous article with the following footprint:
- 3 (high-availability behind Kubernetes Service exposure) VMs that accommodate the CCS backend. It contains:
- CPU cores: 16
- Memory: 48GB
- Total storage: 500GB
- 3 (high-availability behind Kubernetes Service exposure) 5G charging function (CHF) cloud-native network functions (CNFs) that are integrated with the CCS backend
- CPU cores per module: 2
- Memory per module: 4GB
- Attached storage: 15GB
[ Try this hands-on learning path to deploy a cluster in Red Hat OpenShift Service on AWS. ]
CCS KPI benchmarks
Our objective is to get some benchmarks on TPS and latency in response time. It is important to keep latency below a certain threshold to prevent fraud. Keeping response time below a certain threshold (<50ms) is acceptable for telecom service providers, as most prepaid offerings are measured using minutes of service given or taken.
1250TPS: 9.88ms latency
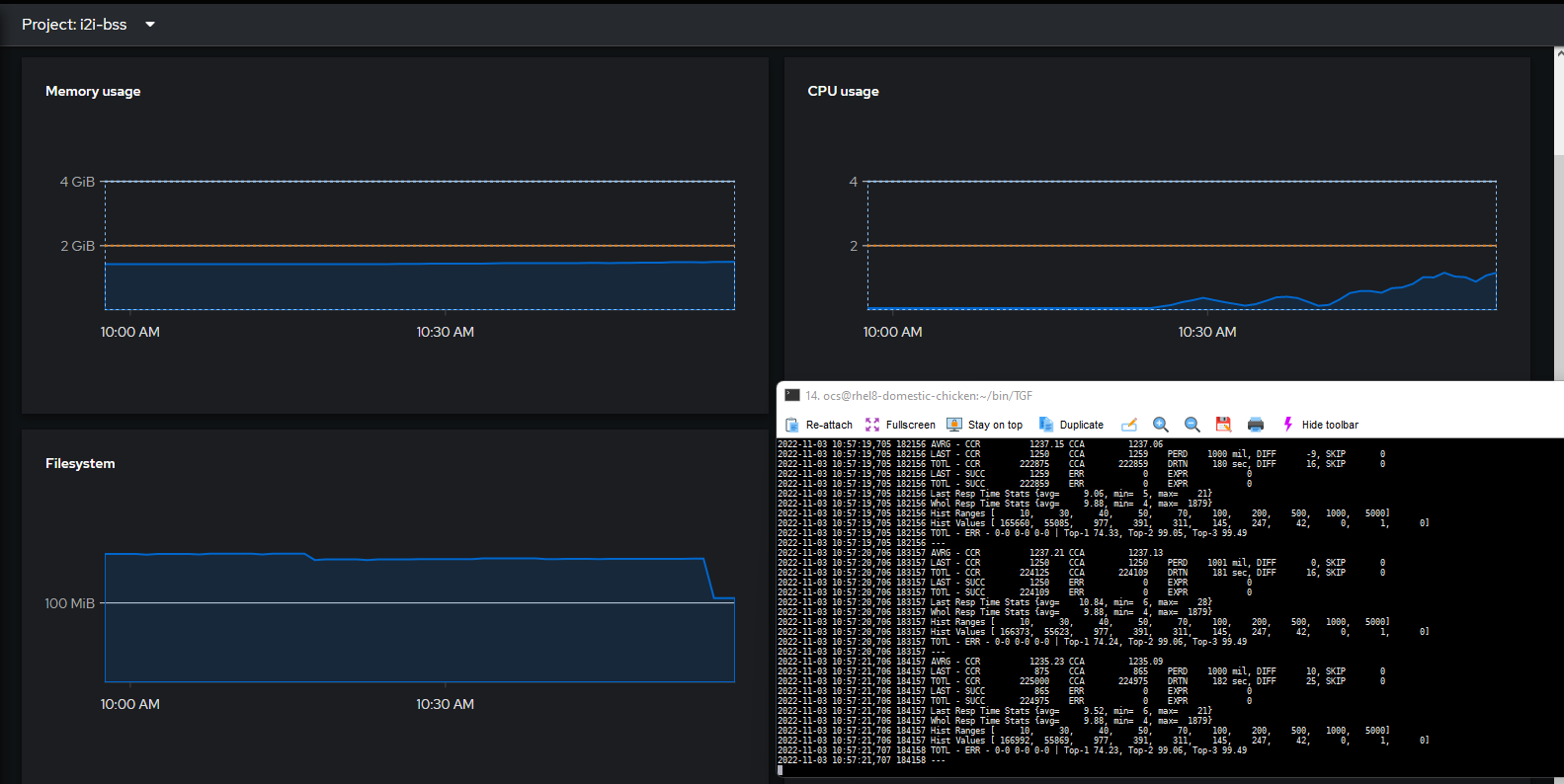
Figure 3. 1500TPS: 11.6ms latency
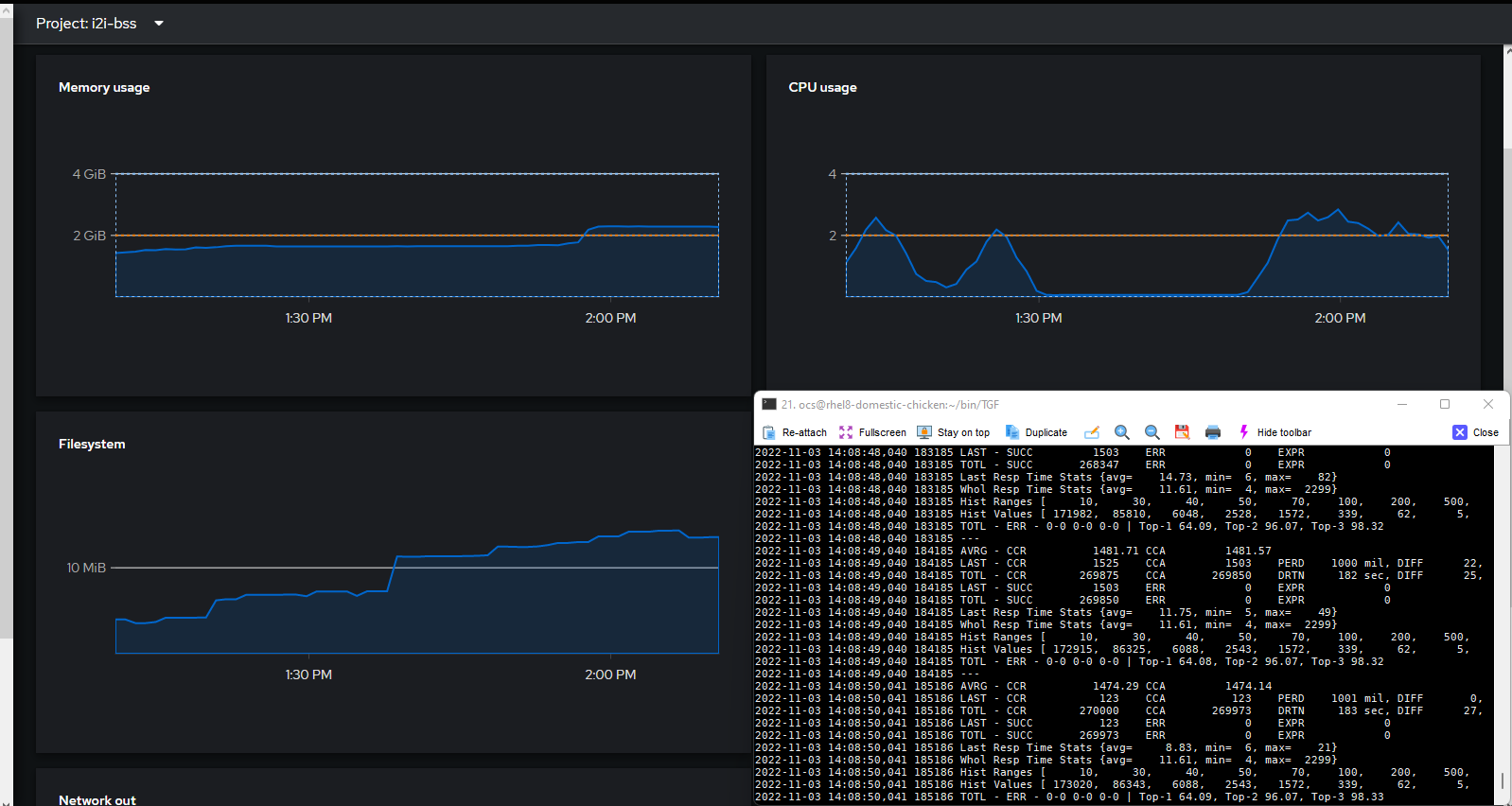
Figure 4. 2000TPS: 32.43ms latency
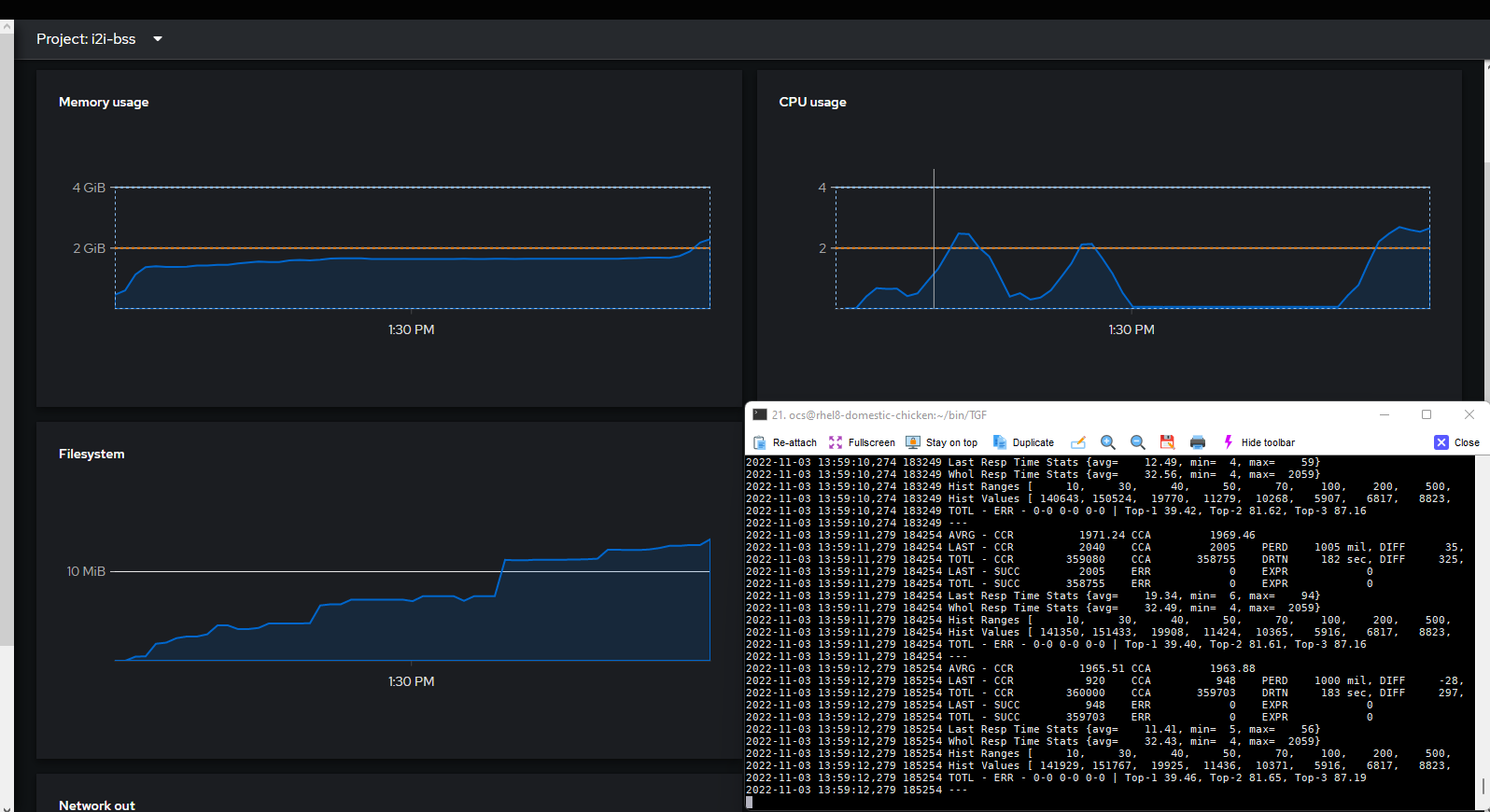
Observations
We achieved two-times-better performance with the exact VM and CNF specification as in our earlier benchmark.
The main reason for this performance difference is:
- We leveraged the latest-generation Intel CPU with higher CPU clock frequencies, faster memory, and storage bus speeds available through the AWS EC2 metal instance.
- We had higher networking throughput: 100Gbps vs. 40Gbps per network interface controller (NIC).
However, the average cost per CPU core in this test has a significant difference ($39.42 per month versus the CPU cost of an already-paid-for on-premises machine capital expense, or CAPEX) that carries the per-cluster cost to higher OPEX spending ($5.3K/month).
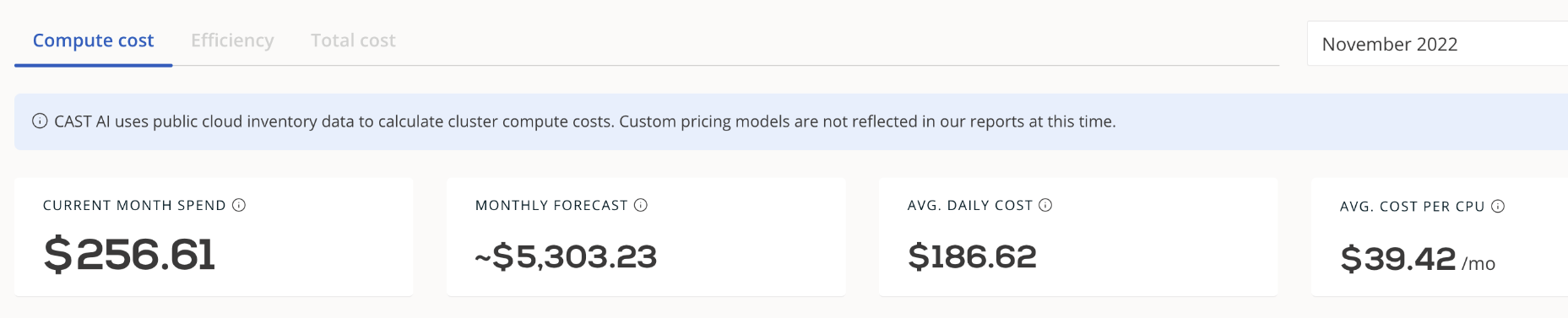
A cloud approach with expensive resource usage should always get the best utilization levels for each resource allocated and paid; otherwise, cloud consumption may not be as economical as it could be. (Please see Quantitative cost comparison of on-premise and cloud infrastructure based EEG data processing for a detailed quantitative cost comparison of on-premises and cloud infrastructure usage for data-intensive application sets.)
[ See Kubernetes: Everything you need to know ]
How to improve the price/performance ratio
Cost analysis and optimization is a continuous process, especially on the cloud, where you need to monitor the cost of each solution and its components to run and deliver the best user experience and operational efficiency.
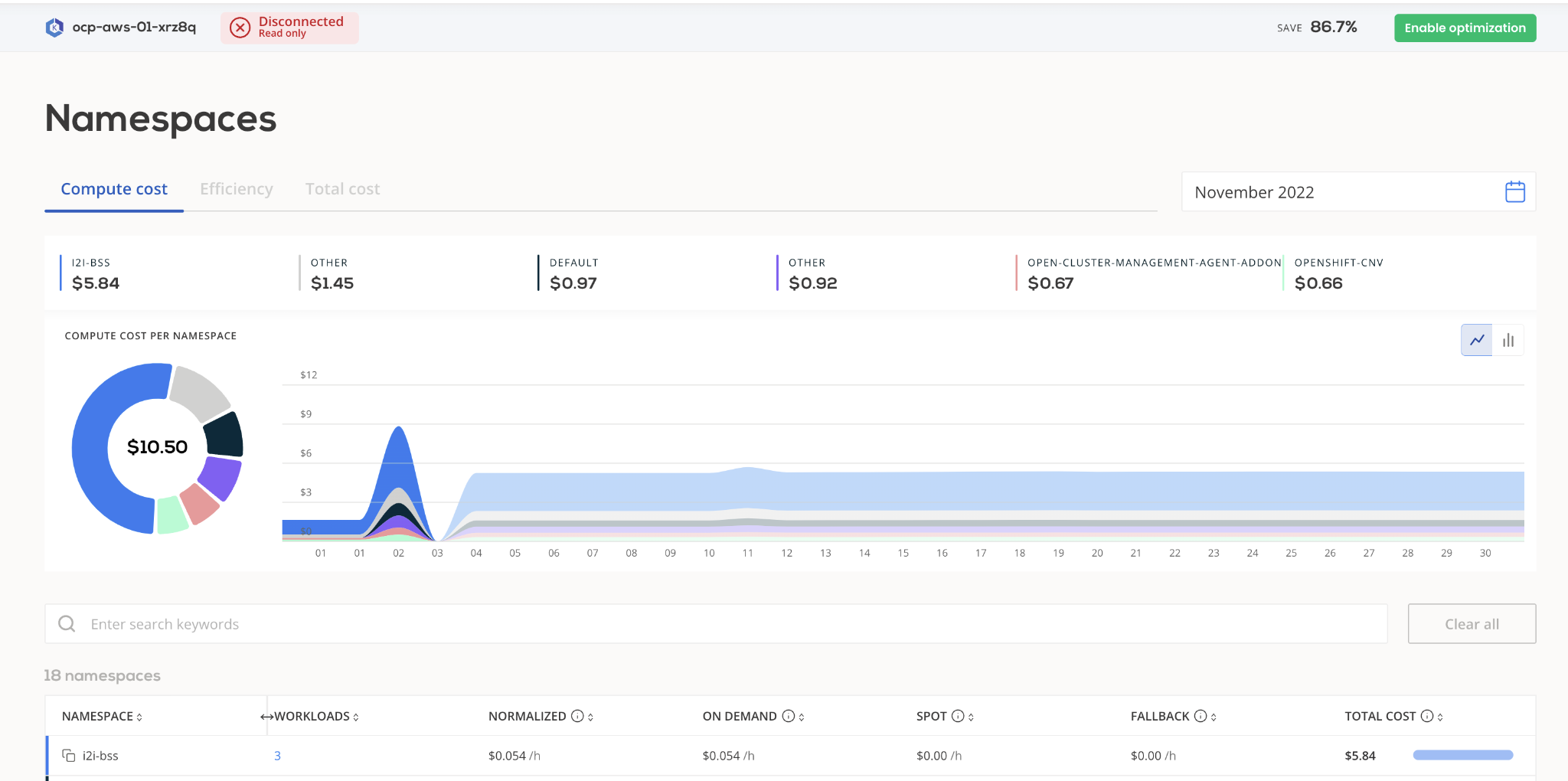
With Kubernetes as an application platform, it is common to use namespaces as one of the isolating boundaries for tenancy and monitoring cost breakdowns.
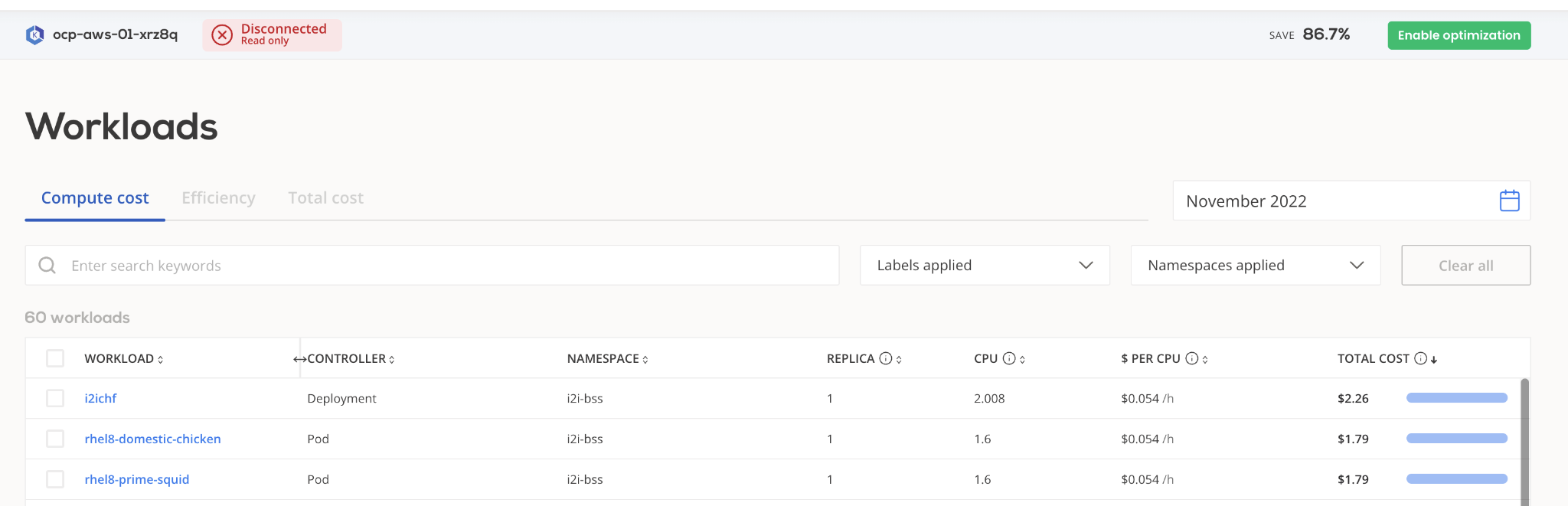
Within a namespace, a workload analysis will help contrast the cost of the application versus business metrics, such as TPS measurement.
[ Hybrid cloud and Kubernetes: A guide to successful architecture ]
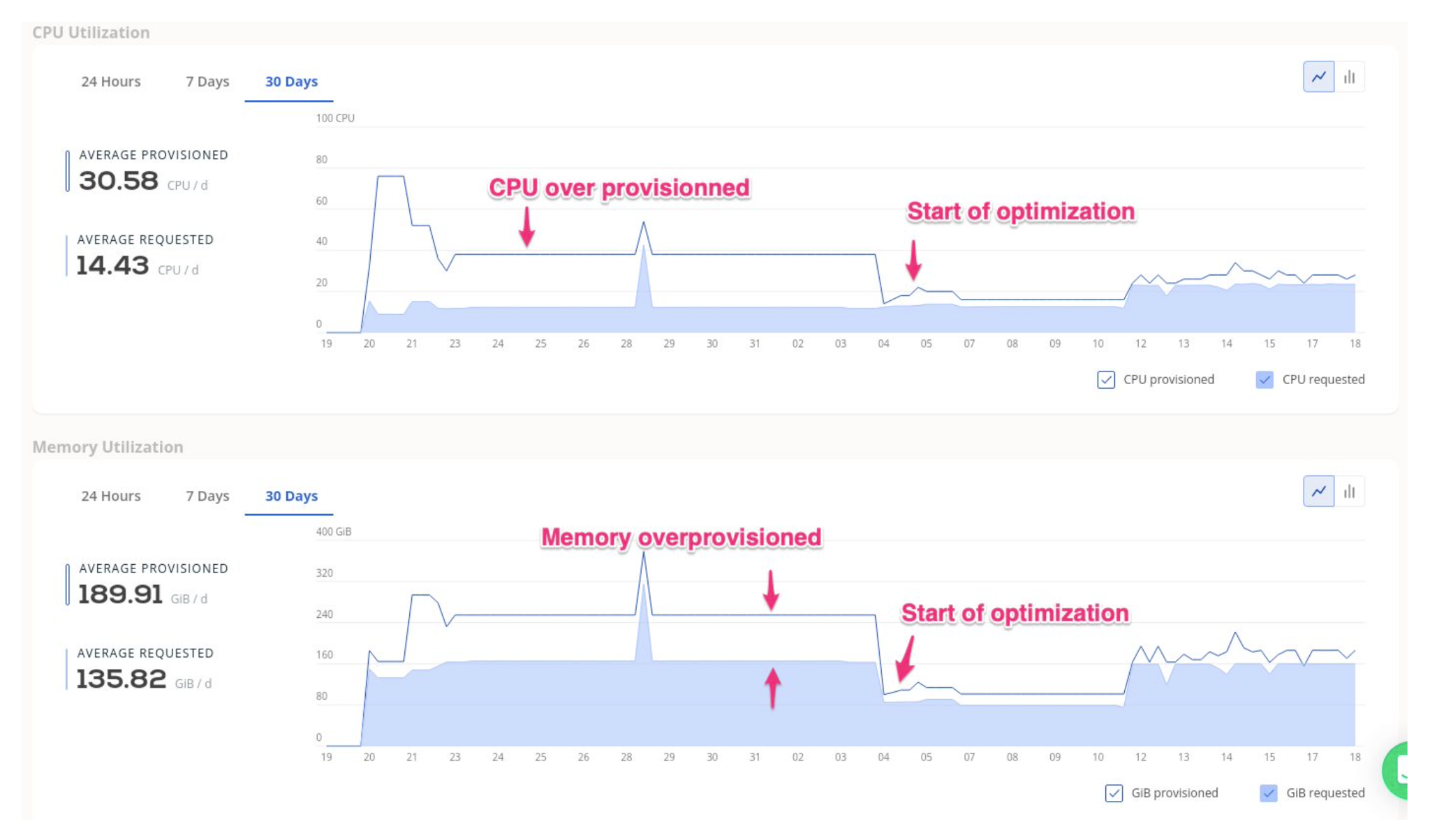
We used Cast AI to guide us in maintaining intended performance levels for application return/revenue and lowering infrastructure and platform costs. It can automatically reduce the infrastructure and platform costs and maintain the application's intended performance levels with the optimized ratio of return/revenue.
CAST AI optimization is based on two automated strategies:
Cluster auto-scaling based on workload needs versus demand, with real-time and extremely efficient rightsizing.
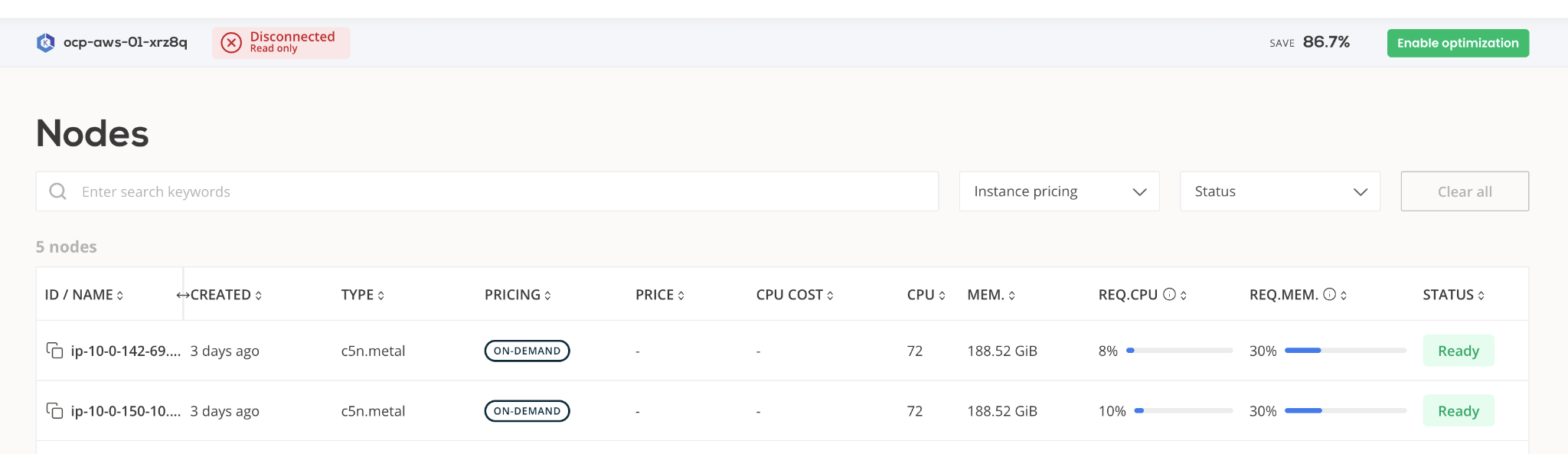
Guiding the selection and use of the most cost-effective cloud resource type (for example, spot vs. on-demand EC2 instances), effectively doing a real-time price arbitrage over hundreds of instance types.
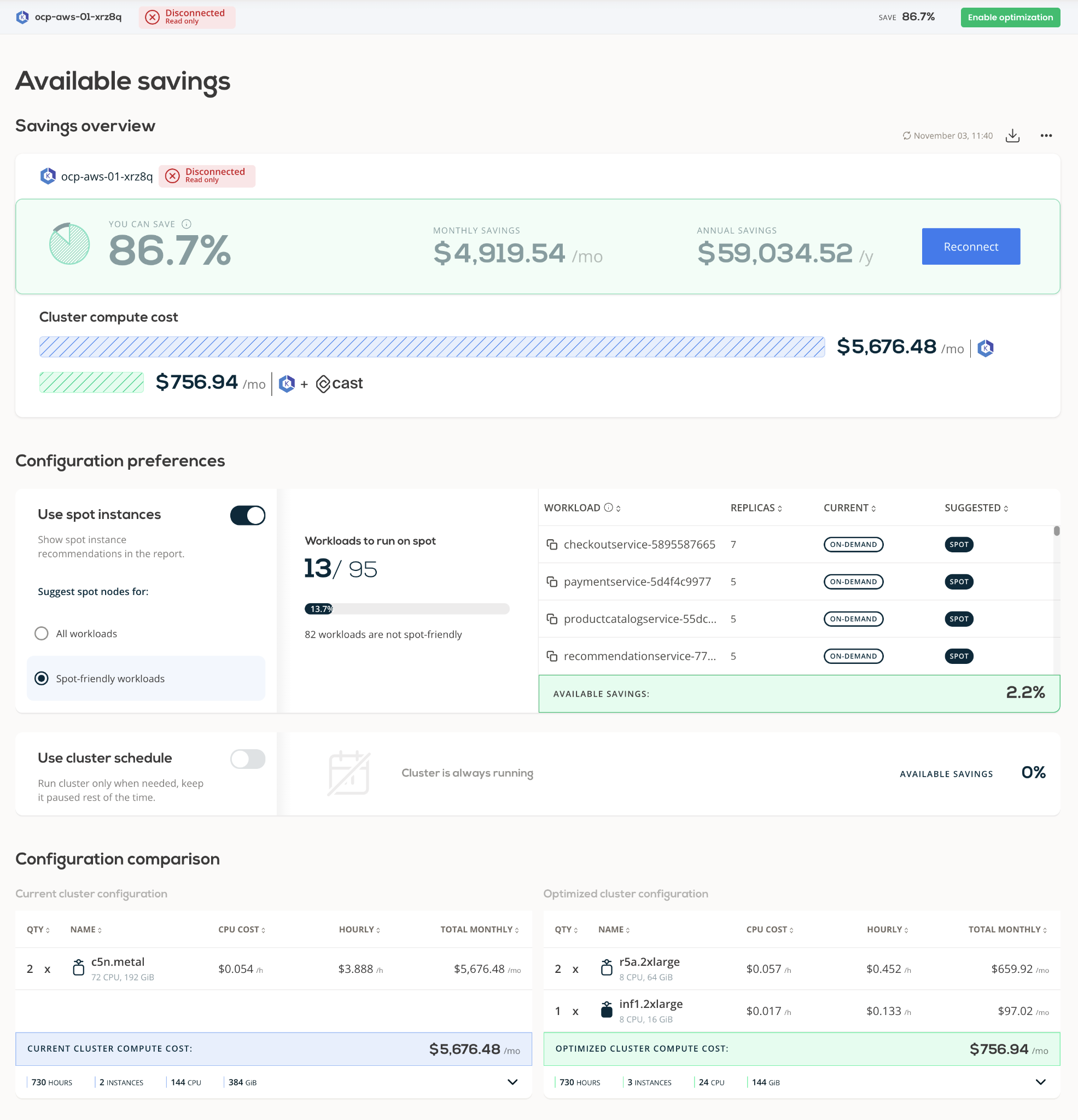
Cast AI continuously reduces the cost of the cluster at the cluster scale and application levels.

If you don't want to implement another solution to increase cost-effectiveness, at least use AWS's native services for managing spending limits and alerts.
Summary
The BSS modernization price-over-performance benchmark tests have shown that Red Hat OpenShift Container Platform with cloud-native virtualization may deliver equivalent and sometimes even better performance for business support system (BSS) solutions with mixed container and VM workloads compared to bare metal. The tests have also shown that users can achieve better total cost of ownership and a consistent deployment experience across different infrastructure types.
This deployment example demonstrates how to optimize cost while meeting or exceeding critical performance requirements. This reference solution, developed with our partners at i2i and Cast AI, automates cost and performance optimization in real time to keep BSS solutions performing optimally from economic and performance points of view.
Details of our BSS modernization ROI optimization solution can be found in the video below.
[ Check out Red Hat's Portfolio Architecture Center for a wide variety of reference architectures you can use. ]
About the authors
Fatih E. Nar, has built a career by solving complex challenges in various domains including telecom, entertainment, media, and others.
With experiences at Google, Verizon Wireless, Canonical Ubuntu, Ericsson, and now Red Hat, he specializes in cloud native and data- and AI-driven solutions for enterprises and service providers.
His work blends AI, cloud, and high performance networked computing to create efficient and scalable software-driven solutions.
He holds an MSc in Information Technology and a BSc in Electronics Engineering, along with completed AI studies at MIT and Stanford, and has been admitted to Purdue University for a doctorate program for Spring 2026.
Fatih is also a recognized writer, sharing insights through his Open xG HyperCore series on Medium and contributing to AI/ML projects on GitHub and Hugging Face.
In 2025, Fatih was elected as a subject matter expert on AI/ML within Linux Foundation Networking (LFN) organization to steer and lead AI initiatives.
When not working, he’s likely exploring new datasets and AI models, ctl’ing with k8s, or sneaking dad jokes into tech discussions.
Volker Tegtmeyer develops content strategies that show how Red Hat solutions can help telecommunications service providers meet their business and technology challenges. Solutions that help service providers in their digital transformation and as they evolve from telco to techco. New technologies cover broad areas from 5G, AI/ML, telco cloud, automation to new solutions that help tackling sustainability goals. Volker has more than 20 years of experience in the telecommunications industry having previously worked in various roles at Siemens, Cisco and Akamai.
Leon is co-founder and CTO at CAST AI. Formerly Vice President of Security Products OCI at Oracle, Leon's professional experience spans across tech companies such as IBM, Truition, and HostedPCI. He founded and served as the CTO of Zenedge, an enterprise security company protecting large enterprises with a cloud WAF. Leon has 20+ years of experience in product management, software design, and development, all the way through to production deployment. He is an authority on cloud computing, web application security and Payment Card Industry Data Security Standard (PCI DSS), e-commerce, and web application architecture.
Yasar Koc is an Integration Engineer with five years of experience and system administration and devops skills. He currently works as part of the System Engineering team at i2i Systems.
Before this role, he worked as a QA Specialist and Support Specialist on national and international charging projects. He has gained experience in Linux system management, performance tuning, and network management in these projects.
He completed his Bachelor of Science degree at Pamukkale University in the Computer Science Engineer Department in the year of 2017. Before graduation, he participated in an internship and was employed at Er-Bakır A.Ş.
More like this
The value of unconventional experience: From sweeping hair to shaping careers
Why Operational Resilience and Digital Sovereignty Top the CIO Agenda
Container Roundup | Compiler
Untangling Networks | Compiler
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds