
Edge computing is an important step forward in distributed architecture. According to the Worldwide Edge Spending Guide from IDC, quoted in a press release from Red Hat, the worldwide edge computing market is estimated to reach $250.6 billion in 2024. Clearly, this is technology worth attention.
Edge computing's essential principle of bringing computing as close as possible physically to the consumer provides a fast, efficient way to deliver complex computing services. However, unlike data center-based distributed architecture, which involves interservice communication between clusters of machines housed together in the same regional locations, edge computing involves physical devices that are spread over wide areas. And, in some cases, the machines are in constant motion. These devices might be a forklift in a warehouse, a driverless vehicle on an interstate highway, or an ATM in a shopping mall. Bringing a wide variety of physical devices into the digital domain fundamentally alters how architects approach distributed computing. (See Figure 1, below)
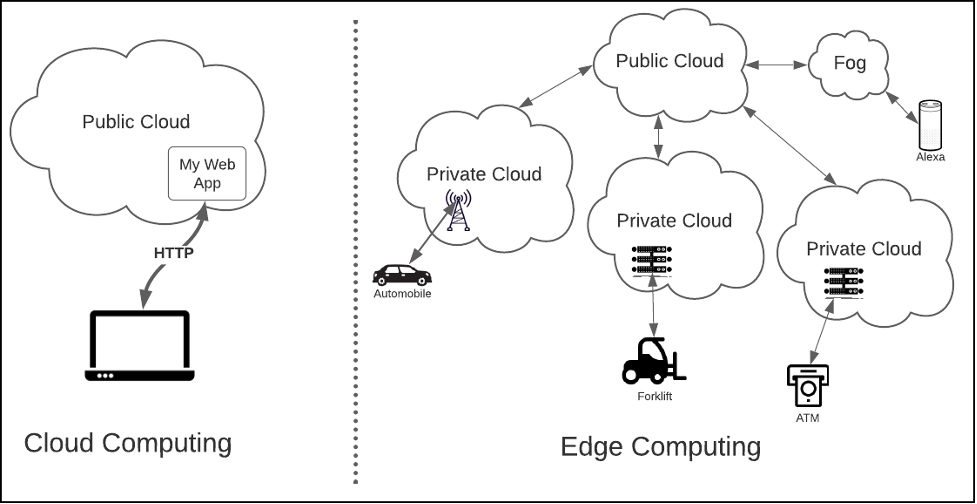
Figure 1: Edge computing requires a higher degree of segmentation in distributed computing patterns
A critical factor in edge computing architectural design is segmentation—logical, physical, and data. Where and how computing assets exist in the application domain are important factors in edge computing. Whereas protecting digital data is a primary consideration in a cloud computing environment, in edge computing, protecting the dozens, hundreds, even thousands of physical devices from malicious intrusion is just as important as protecting the bits and bytes flowing in and out of the devices. After all, do you really want a bad actor hacking into the smart device sitting in your living room and listening to your every conversation? Or worse yet, do you want that same bad actor taking over the driver-assist mechanisms in your automobile and wreaking havoc upon other vehicles as it makes its way down Main Street on the way to the grocery store?
These risks are some of the real challenges in edge computing, and they must be addressed. Fortunately, they have, mostly through giving keen attention to architectural design considerations around segmentation.
In this article, I look at segmentation in an edge computing environment. I'll discuss the challenges implicit in edge computing. Finally, I'll examine different approaches to segmentation—physical, logical, and in terms of data.
The challenges at hand
Edge computing introduces distributed computing to a number of factors that add more complexity to architectural design segmentation strategies. Whereas the standard cloud computing environment is relatively homogenous, made up of data centers containing racks of x86 machines and mainframe computers that communicate via TCP/IP over fiber optic ethernet, edge computing is different. Edge computing incorporates a wide variety of devices and communication protocols that might be powered by any number of physical chipsets. Some devices, such as Automated Teller Machines (ATM), use standard x86 CPUs, others such as those running on Raspberry PI devices, use ARM architecture. Finally, some devices use chipsets that are unique to the device, such as those found in robotic systems and automobiles.
In addition to differences in computational hardware, there's variation in communication protocols. One device might communicate via a direct ethernet cable, another uses a wireless technology that communicates over 802.11x, and yet a third uses Bluetooth to connect. All these devices will need to be supported.
Updating systems is also a concern. When working with standard computing devices such as laptops, tablets, or cellphones, updating these systems is fairly straightforward because, typically, they are accessible from within the network. But, how do you upgrade the software on a driverless vehicle that has special hardware, that uses special protocols, and has intermittent connectivity to the network? These types of cases pose a significant challenge in enterprise architecture, yet they must be accommodated. Thus, paying attention to resource segmentation in an edge computing environment at the physical, logical, and data levels really matters.
Physical segmentation
Physical segmentation is about separating the parts of a distributed architecture over a variety of physical machines. As mentioned above, in a central data center, physical segmentation usually involves the placement of computer hardware in racks of servers within the building. In situations that require lightning-fast communication between the machines on the network, the devices will be installed as close together as possible. The laws of nature are such that the closer machines are to one another, the less time it takes for data to move between them. For less time-sensitive applications, the actual proximity of the machines within the data center is of less consequence. Just having everything in the same building will suffice.
However, when edge computing comes into play, things get more complex. Where the machines are placed matters, particularly when the application domain is stretched out over a wide geography. Long distances between devices can translate into greater latency in the communication chain. In such cases, the physical computing grid needs to be broken up into smaller segments.
One of the segmentation patterns that has emerged is termed the Fog pattern. The Fog pattern is one in which satellite data centers and collection points are positioned as intermediary computing points between IoT devices and the primary data center. (See Figure 2, below)
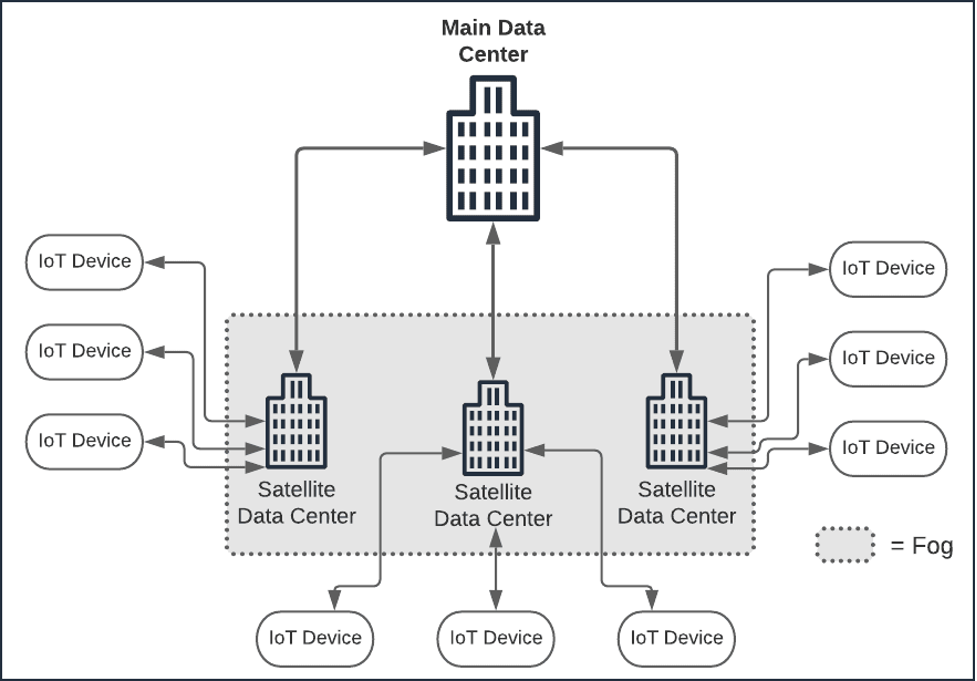
Figure 2: The Fog pattern describes a way of segmenting physical computing between IoT devices and the primary data center
Data centers in the Fog act as quasi-edge devices in that many times, they run on private networks, at a particular location, and have a special purpose.
An example of the Fog architecture is a traffic-cam system in which a group of traffic cameras is connected to a district data center in the municipal grid. In turn, each district data center connects back to the city's main data center. The data transfer is more efficient because each camera is connected to the Fog. However, simply moving data to and fro only has meaning in terms of the logic that's using that data. There's a good deal of efficiency to be gained by placing critical programming intelligence at just the right point among the computing assets in the edge architecture. This is where segmenting programming logic comes into play.
Segmenting logic
The typical pattern to distribute intelligence in a web application is to put the UI logic, validation rules, and some computational capabilities in the web page or client device. Computing logic relevant to the application that is broader in scope is hosted in the data center, for example, fulfilling a purchase on Amazon.com. In many ways, web application architecture is closer to a traditional client-server architecture than not.
However, with edge computing, applying the web-server model of segmenting logic between the edge device and the main data center doesn't always make sense. This is particularly true when the edge device is a dedicated machine such as a smart forklift in a warehouse or a video camera at a traffic intersection. The network traffic alone can be a showstopper. If the device cannot communicate back to the main data center, for example, when hitting a "dead zone" in the facility, operations can come to a grinding halt. Thus, how and where logic is segmented is an important architectural decision.
A good rule of thumb to use when considering logic segmentation is to put only as much logic in each physical segmentation layer as is necessary for that segment to do its job. For example, suppose the particular IoT device is a smart forklift that supports real-time location, which allows it to automatically find the correct rack in the warehouse from which to pull merchandise. In that case, the forklift should have the logic installed to navigate to the intended location safely. The device should not have to keep calling back to a server for instructions about how to navigate its path throughout the warehouse. Also, the forklift should have the logic that's required to do system updates. Such logic might take the form of an SSH server that allows a human or bash script to do manual updates or a message subscriber that's bound to a message broker in the Fog. In this situation, the message subscriber on the forklift receives an update message from a central message broker. The forklift then uses an HTTP client to call back to the Fog server to update its code.
Navigating the warehouse floor, selecting a palette of merchandise, and facilitating updates are core functions of a smart forklift. However, it is not a core function of the forklift to process the customer order related to the merchandise the forklift selected. That work is better done by logic hosted elsewhere, for instance, in a small set of servers in the warehouse or a private Fog located in the warehouse's geographic region.
Restricting order processing to the warehouse is appropriate to the contextual boundary of the facility. However, there is a further level of escalation. The logic that coordinates that particular customer order in the bigger picture of the company's supply chain management system can be hosted further up the stack in the Enterprise Resource Planning service that the company uses globally. (See Figure 3.)
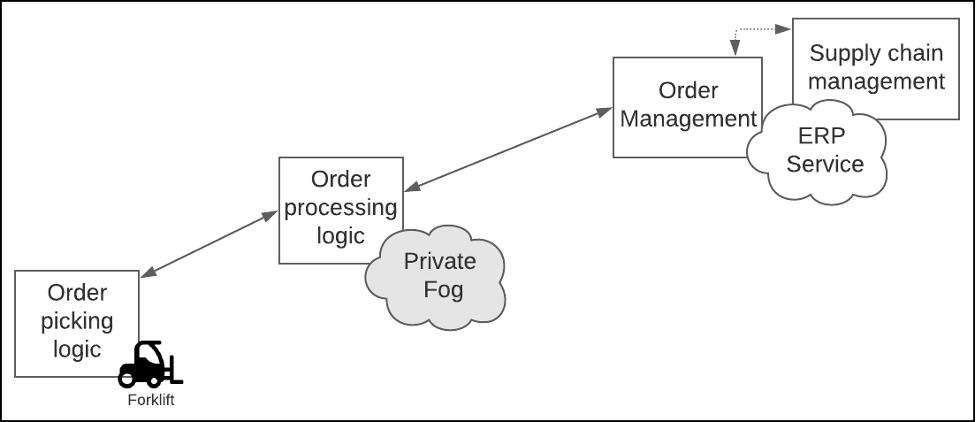
Figure 3: In an edge-computing architecture, logic should be partitioned according to the essential purpose of the segmentation layer
While it's true that there is no "one size fits all" solution in terms of logic segmentation in an edge architecture, the important unifying concept is that you want to get just the right amount of logic as close to the need as possible. The actual implementation will vary by device array and application domain. Smartphones, which are by nature, a multi-purpose device, will contain a wide variety of software, while devices with a narrower scope of purpose, such as a home thermostat, will have a lot less.
Figuring out how to segment logic is equal parts art and science. The important thing to understand is that logic segmentation is a critical aspect of edge computing architecture that requires significant thought and planning as well as a keen awareness of the purpose of each entity in the edge architecture.
Segmenting data
In addition to determining the segmentation of logic in an edge computing grid, architects need to think through how data will be segmented, too. Unfortunately, as with logic segmentation, there really is no "one size fits all" way to approach segmenting data. How an architect segments data depends on the purpose of the data exchange and the network's physical environment.
However, a good guideline to remember is that smaller data packets are easier to move and faster to process than larger ones. Data converted to a binary format such as Protocol Buffers and streamed data under a highly efficient communication protocol such as gRPC provides a very fast exchange. The tradeoff is that moving to binary data structures transmitted in a stream adds a higher level of complexity to the architecture in terms of packaging and processing the data. Nonetheless, the basic rule is this: Small packets good, streamed data better! With this in mind, let's revisit the smart forklift and warehouse scenario described above.
There are three data exchange points in the smart forklift and warehouse scenario: The smart forklift, the local warehouse private cloud (a.k.a, the Fog), and the ERP system that coordinates the supply chain. The ERP system is hosted in a secure global cloud.
The purpose of the smart forklift is to retrieve a palette of merchandise from a warehouse bay. To meet the need, the local private cloud sends specific order information to the smart forklift.
The local private cloud keeps track of the movement of the smart forklift. In addition, the local private cloud sends the ERP system information relevant to customer orders as they are fulfilled by the smart forklift when it brings a palette of merchandise to the warehouse dock and loads it into a truck for delivery to the customer.
The ERP in the global cloud sends information about the order to be filled to the warehouse Fog. The entire scenario is illustrated above in Figure 3.
Let's examine the segmentation of data according to the endpoint.
Understanding data exchange in an IoT environment
First, there is the smart forklift. The smart forklift needs to send its location and operational status information to the private Fog at the warehouse level. The warehouse needs the location information to provide the most efficient route to the warehouse bay of interest. Also, if the smart forklift breaks down, the warehouse needs to be alerted, thus the need for operational status information.
Location and status information is very time-sensitive. After all, if an aisle in the warehouse is blocked, the smart forklift needs to reroute immediately. Or, if the smart forklift breaks down, the order it was processing needs to be moved to another machine. The forklift can encapsulate location, routing, and status data into small, structured messages that get passed back to the warehouse Fog in a continuous stream. As mentioned above, streaming data is fast and efficient, particularly when the message is transformed from text to a binary format. Thus, segmenting data into binary messages exchanged via a data stream running under gRPC will meet the need at hand.
The smart forklift doesn't need to know everything about a customer order in terms of sending and receiving order information. All it really needs to know is the order ID, the merchandise ID (the SKU), and the warehouse bay where the pallet of merchandise is stored. These three values can be structured into a very small message received from the warehouse Fog. Such message exchanges can be facilitated via a typical HTTP request-response against a RESTful API. For faster transmission, the order information between the smart forklift and private Fog can be exchanged via a bidirectional gRPC stream.
No matter which transport method the system uses, the essential requirement is that the data exchanged between the IoT device, in this case, the smart forklift, and the private Fog coordinating the activities of the IoT device in the warehouse must be segmented into small messages that can be sent and received very quickly. The bottom line is that speed is essential. Thus, the data needs to be segmented accordingly.
Segmenting data exchange between the Fog and the cloud
There is a big difference with the segmentation between the private Fog and the ERP system hosted in a global cloud. The most significant difference is the degree of time sensitivity that applies to the data exchange.
Information exchange between the IoT device and private Fog needs to be nearly instantaneous. Data exchanges between the warehouse's private Fog and global ERP system can be given more time. Whereas the data exchange between the IoT device and private Fog needs to happen on the order of milliseconds, the exchange between the warehouse and the ERP system can tolerate a latency of a second or two. Also, the ERP system and the private Fog in the warehouse are only interested in information relevant to order fulfillment. This means that data can be submitted and received in batches. A single message can contain data about a lot of orders. The result is that the messages are bigger. However, this is okay because there's more time available for the exchange. (See Figure 4, below.)
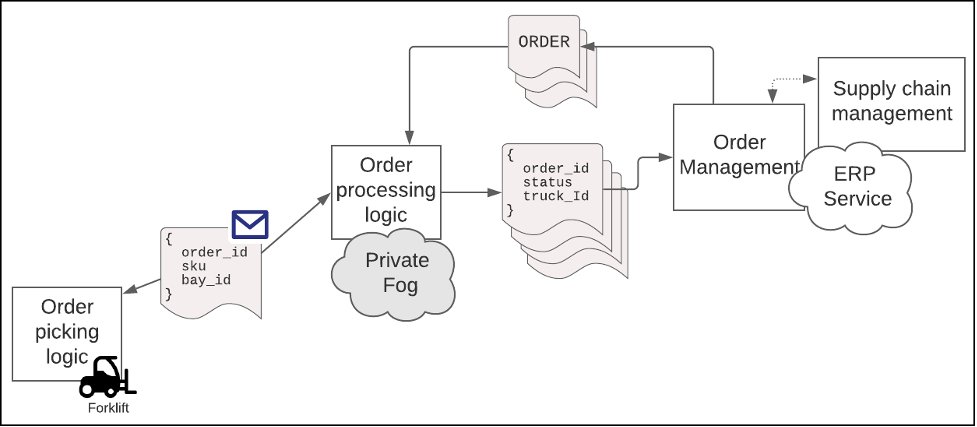
Figure 4: Data segmentation is an important aspect of enterprise architecture in an edge computing environment
The exchange can be facilitated using standard HTTP over a RESTful API, or it can be transmitted in a stream. This decision is a matter of preference. For some companies, working with REST at the ERP level is a lot easier than supporting the mechanics of encoding and decoding binary streams of data over a network connection that is open and continuous. Also, just as data is segmented according to the physical environment and the purpose of the interaction, so too is IT talent. Thus, making sure the organization has the right people working in the right area matters.
Programming an IoT device requires a different skill set than writing the code for an ERP system, particularly if you are writing to a specialized IoT device with a proprietary programming language. Companies tend to divide IT developers up accordingly. Thus, deciding on the API framework and data formats to use will depend to some degree on the human resources available as well as the purpose of data exchange and the physical environment where the exchange takes place.
Putting it all together
Edge computing is the next great opportunity in distributed computing. The continuing growth of the Internet of Things (IoT) and the broader distribution of commercial web applications puts edge technologies at the forefront of architecture design and implementation.
Edge computing brings a lot of power to the modern digital enterprise. As the saying goes, with great power comes great responsibility. Thus, having a general awareness of the dynamics driving segmentation patterns in edge computing is essential for the forward-thinking enterprise architect. While the ideas discussed in the article only scratch the surface of principles and best practices of architectural segmentation in edge computing, the concepts presented are a good place to start.
About the author
Bob Reselman is a nationally known software developer, system architect, industry analyst, and technical writer/journalist. Over a career that spans 30 years, Bob has worked for companies such as Gateway, Cap Gemini, The Los Angeles Weekly, Edmunds.com and the Academy of Recording Arts and Sciences, to name a few. He has held roles with significant responsibility, including but not limited to, Platform Architect (Consumer) at Gateway, Principal Consultant with Cap Gemini and CTO at the international trade finance company, ItFex.
More like this
Physical AI: When machines start to think and act in the real world
Two-node OpenShift with fencing improves reliability at the edge
Infrastructure At The Edge | Compiler
Open Curiosity | Command Line Heroes
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds