
There was a time in information technology when everything was centralized. It was called mainframe computing. Programs and data lived in one place. Even the compiler that turned source code into machine-executable binaries and the documentation required to support that code lived on that single machine.
But that was then, and this is now. Today, computing resources are distributed over a vast technology landscape that keeps expanding. This is good. Distributed, decentralized computing makes the cloud possible. It also creates an environment that supports modern microservice-based architectures. But as with any set of benefits, there are also challenges.
One of the biggest challenges in modern distributed architectures is the risk of fragmented change management. When you have a large, decentralized IT organization in which workgroups enjoy a high degree of autonomy, unless precautions are taken, it's not unusual for one workgroup to make a change in its work product only to have that change impact other workgroups in a negative, insidious manner.
To put it bluntly, sometimes the left hand does not know what the right hand is doing, not so much out of ill intent, but rather because of an underdeveloped architectural design that can't accommodate the type of change management required in a modern distributed system. Fortunately, there is a way to avoid this type of hazard using the single source of truth (SSOT) approach to asset management in conjunction with GitOps principles.
Describing the basics of an SSOT approach is the purpose of this article. I'll begin with a scenario that illustrates a hazardous environment. Next, I'll describe how to use the SSOT approach alongside GitOps to create an accurate, reliable source of knowledge that allows workgroups to collaborate effectively.
An all-too-typical scenario
Imagine a workgroup that publishes a mission-critical API used inside and outside the organization. As with any API, documentation is essential. Without it, developers using the API are flying blind.
To document the API, a technical writer examines the code created by the API developers and then manually creates the API documentation. The writer copies and pastes into the documentation the operational details that other developers need to work with the API. The documentation is then published on a website, again using a manual process.
It's a typical process, but one that's risky. Why? Well, take the scenario a step further. A day after the API documentation is published to the website, the software developers in the workgroup change the API by adding new functionality and release an updated version of the API. However, they don't inform the technical writer of the change. That makes the API's existing documentation out of sync with the latest, published version of the API. (See Figure 1, below.)

The risk at hand is apparent. The development team has published its "truth," but the technical writer's "truth" described in the documentation is different. To use the popular phrase, there is no single source of truth. As such, things can go haywire in no time. A single source for truth is needed. So the challenge is to make one.
Creating a single source of truth
An SSOT is a technique by which all the data relevant to a given domain is organized into a single location using a standard means of hosting. The concept is pretty straightforward, but the implementation can get tricky.
Much of the conventional wisdom about creating an SSOT is that an organization declares an authoritative data source that describes all the facts needed for all parties in a domain to do their work. That data source might be a filesystem, a database, or a wiki. Unfortunately, conventional wisdom has a shortcoming. Creating a scalable SSOT involves a lot more than just publishing data to a single location.
In the scenario above, the SSOT was the API's source code. That didn't work out too well, did it? The minute the code was updated, the documentation went out of sync. The shortcoming is built into the architecture. The code is acting as the SSOT yet fulfilling very little of its obligations.
[ If you're starting your cloud journey, download the eBook Event-driven architecture for a hybrid cloud blueprint. ]
In order for something to be a reliable SSOT, it needs to be accessible to all parties that depend on the truth, and it needs to have a way to communicate to those interested parties when the truth changes. Using the raw source code as the SSOT is not sufficient to ensure dependable accuracy over time.
Instead of using the source code as the SSOT, what if you instead use an API specification, taking a specification-first approach. Specification First means "all work emanates from an ever-evolving but controlled specification. This includes coding, documenting, and enhancing software."
Typically, those implementing Specification First for an API use a standard specification format such as OpenAPI, gRPC, AsyncAPI, or GraphQL. API specifications of this sort can be quite detailed, down to the function definition level.
The benefit of using Specification First as an SSOT is that both code and documentation can be generated from the specification document. Thus, software developers and documentation developers use the API specification collaboratively. However, they don't work with the specification manually. Rather, they use automation technologies to do most of the work.
[ Find out more about configuring Red Hat Ansible Automation Platform with GitOps. ]
Figure 2 is an example of taking a Specification-First approach to implementing an SSOT architecture. Notice that both the API and the API documentation use the API specification as the SSOT. Hence, all parties do their work according to the specification. Software developers create code according to the specification. Technical writers create documentation according to the specification.
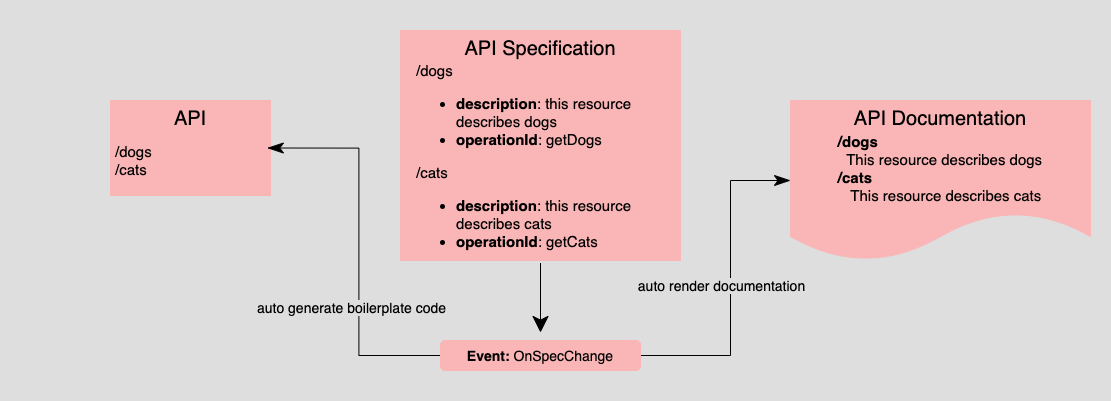
However, as attractive as using Specification First is to implementing an SSOT architecture, there is still a good argument to be made: So what? What's to stop the API developer from going into the source code and making changes to the API unbeknownst to the technical writer and thus putting everything out of sync again? This is where automation comes in.
Take another look at Figure 2. Notice the event, OnSpecChange, shown at the bottom of the illustration. This indicates that somehow an OnSpecChange event is raised when a change is made in the API specification, and interested parties can react accordingly.
How that event is raised and how interested parties will react is an architectural design decision. These days, a popular architectural design is based on the principles of GitOps. Under GitOps, a source code repository service such as GitHub, BitBucket, or GitLab can raise messages that get consumed by various message hooks.
Figure 3 illustrates an architectural design that applies GitOps to the SSOT approach.
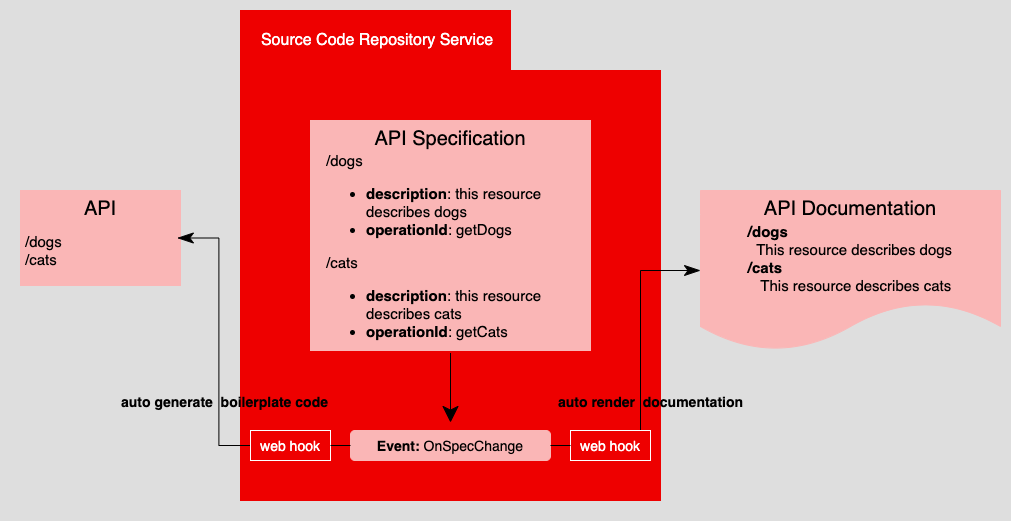
Notice in Figure 3 that the source code repository service makes it so that when a change happens in the API specification, an OnSpecChange event is raised and consumed by hooks that notify the API and the API documentation when a change event occurs. In turn, the API source code and the API documentation react accordingly. In this case, there can be automation behind the API source code that stubs out the function in the source code. Also, for documentation published on a website, the documentation team can create automation that reacts to the OnSpecChange event by rendering the added information in the documentation website without human intervention. (I use this technique frequently.)
Using the GitOps and SSOT architecture, when a change occurs in the API specification, such as adding a new endpoint to the API, all relevant resources—source code and documentation—will react to the update according to the automation in place. Figure 4 illustrates an example.

Putting it all together
Using GitOps in conjunction with the SSOT approach to asset management can save a lot of headaches. However, be advised the practice is a bit more than just putting code in a repository. Implementing an SSOT architecture doesn't just happen; it's a matter of planning. Remember, SSOT's benefit is it allows many workgroups to collaborate safely and accurately. There's a lot of design work required to achieve this goal.
SSOT's scope of impact goes beyond a single development team. It's an undertaking that happens at the enterprise level. Thus, the design and implementation efforts required to make an SSOT that works fall within the realm of enterprise architects, and with good reason. Their job is to see the Big Picture and create systems that meet the needs of that Big Picture. Implementing an SSOT using Specification First and GitOps principles is indeed a Big Picture item. Fortunately, once adopted and found effective, an SSOT architecture will become a way of life within the enterprise and provide benefits for years to come.
About the author
Bob Reselman is a nationally known software developer, system architect, industry analyst, and technical writer/journalist. Over a career that spans 30 years, Bob has worked for companies such as Gateway, Cap Gemini, The Los Angeles Weekly, Edmunds.com and the Academy of Recording Arts and Sciences, to name a few. He has held roles with significant responsibility, including but not limited to, Platform Architect (Consumer) at Gateway, Principal Consultant with Cap Gemini and CTO at the international trade finance company, ItFex.
More like this
The value of unconventional experience: From sweeping hair to shaping careers
Turning complexity into confidence with Red Hat Technical Supportability Review with AI
Container Roundup | Compiler
Untangling Networks | Compiler
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds