

The objective of this blog post is to present customers with options regarding HA/DR for applications deployed on OpenShift.
At a high level, high availability means that an application is available regardless of underlying failures. An example scenario where high availability comes into play is when a node fails and Kubernetes reschedules any lost pods to surviving nodes.
At a high level, disaster recovery means action needs to be taken to recover applications in the event of a disaster. An example scenario where disaster recovery is needed is when the entire cluster is lost, meaning that workload must be recovered to a new cluster.
By understanding potential points of failure, you can understand risks and appropriately architect both your applications and your clusters to be as resilient as necessary at each specific level. Following are some of the potential pitfalls.
Pod failure and premature termination
Pod failure refers to individual pods crashing or otherwise failing to perform their task. This can occur for many reasons, such as a misconfiguration. Premature termination happens when, for example, a pod is evicted from a node as a result of resource contention. This can have an adverse effect on the application if appropriate resiliency and other measures are not used. Some of the steps to ensure high availability of applications in the event of pod failure and termination are:
- Setting replica count appropriately to accommodate an individual pod failure
- Setting anti affinity rules to ensure pods are distributed across nodes
- Setting pod disruption budget. Be aware that pod disruption budgets cannot prevent involuntary disruptions from occurring.
For additional information, check out this article.
Node failure
Node failure is referring to anytime a node unexpectedly becomes unavailable to the cluster. This could be because of a hardware failure, resulting in the node becoming inaccessible on the network, or an environmental issue, such as a power failure. In this case, some potential ways to mitigate the failure are:
- Have health checks in place for the nodes
- Use hypervisor anti affinity rules for control plane nodes so that a single hypervisor failure does not result in multiple control plane nodes becoming unavailable.
- Understand that, by default, it takes five minutes for Kubernetes to reschedule workloads from an unreachable node. For worker nodes that have been provisioned using an IPI-based install, you may reduce this time by having machine health checks in place, which will result in the node being replaced. For other workloads, use the Poison Pill Operator to detect node failure faster.
- For virtualized OpenShift clusters, the hypervisor’s high availability features can bring back nodes quickly. This will result in the pods on any lost OpenShift nodes being rescheduled when the node rejoins the cluster.
If a node fails, for any reason, here are some helpful links to recover the lost capacity:
- Replacing failed master node: https://access.redhat.com/solutions/5668461
- Add worker nodes with UPI after deployment is done the same as during deployment.
Cluster failure
Cluster high availability depends on the control plane staying healthy in the event of failure. If the control plane fails, or otherwise becomes inaccessible, many functions will stop working. Scheduling of Pods is one of the most critical. With OpenShift 4, all clusters (with the exception of single node OpenShift) have three control plane nodes, each one also hosting an etcd member. With three nodes, the control plane will continue to function even with one failed node. If two nodes fail, then the control plane cannot function.
So, with that said, if all three OpenShift control plane nodes are in the same data center and there is a data center failure, the OpenShift cluster cannot recover.
Scenario - Customer has two data centers
A “stretched” cluster between two sites, where one site hosts two control plane nodes and the other hosts the third control plane node, does not meaningfully increase availability. A single site failing, the one with two control plane nodes, will result in the cluster being unavailable. The additional complexity and potential failure of the components “between” the two sites also contributes to increased risk of the OpenShift cluster being unavailable or otherwise impacted. So, while it is fully supported to have a stretched cluster, it commonly does not increase availability.
In general, the better option with two sites is to deploy an OpenShift cluster in each of the two data centers and have a global load balancer in front of them. However, this does require some application awareness and monitoring to ensure that the correct instance is active and any persistent data used by the application is replicated appropriately.
Option 1: Active/Passive, where the app is wholly in one location and the component definitions (Deployment, Service, Route, Secret, ConfigMap, PV/PVC) are available at the second location, ready to be deployed leveraging strategies like GitOps. But, storage would need to be replicated inline with their Recovery Time Objective (RTO) and re-introduced to the destination cluster accordingly:

For replicating application data, one can use either infrastructure level replication, for example, (a)synchronous storage replication, or application-level replication, for example, CockroachDB, which is a cloud-native distributed SQL database.
Option 2: Active/Passive (Warm DR) scenario where a global load balancer sends all traffic to one location and the app manages replication to the secondary location:
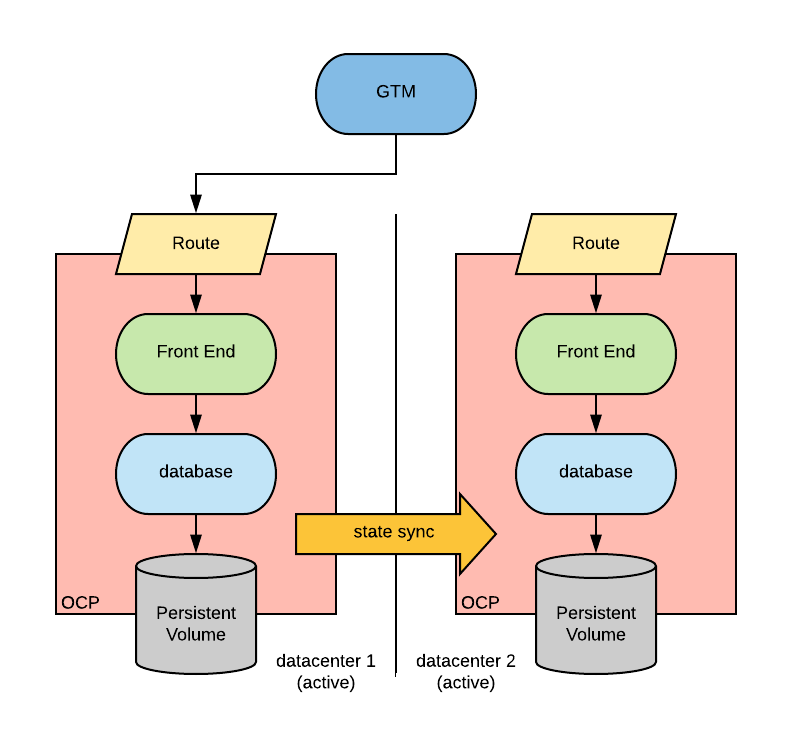
Option 3: Active/Active scenario where the global load balancer sends traffic to both locations and the app manages cross-replication between them:

Scenario - Customer has ability to deploy workloads in three availability zones
Deploying an OpenShift cluster across at least three availability zones is a recommended option for a highly available cluster. Control plane nodes are distributed across availability zones by default when deploying with IPI. Given that network communication across cloud availability zones has low enough latency to satisfy etcd requirements, the above approach works on most hyperscale cloud providers. However, this tactic will not work across cloud regions, which have much higher latency for region-to-region communication.

Close coordination between application teams, infrastructure teams, and database teams is essential to design highly available applications on Kubernetes clusters.
In addition to potential points of failure discussed above, ensuring availability of storage is critical for successful high availability of stateful applications
Storage availability
The best ways to maintain availability of storage are to use replicated storage solutions, shared storage that is unaffected by outages, or a database service that is independent of the cluster.
Conclusion
In this article, we presented multiple options for protecting workloads against downtime. This list does not cover all of the scenarios and is by no means exhaustive. For the next steps, please check out these additional resources:
Please reach out to your Red Hat account team to discuss further.
References:
About the authors
With his experience of being a customer of OpenShift as well as prior experience of working on IBM software, Santosh helps customers with their Hybrid Cloud adoption journey.
More like this
Why flexibility is non-negotiable in the Middle East’s AI transformation journey
The agentic paradox and the case for hybrid AI
Edge computing covered and diced | Technically Speaking
Crack the Cloud_Open | Command Line Heroes
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds