

As enterprises increasingly adopt large language models (LLMs) into their mission-critical applications, improving inference run-time performance is becoming essential for operational efficiency and cost reduction. With the MLPerf 4.1 inference submission, Red Hat OpenShift AI delivers impressive performance with vLLM delivering groundbreaking performance results on the Llama-2-70b inference benchmark on a Dell R760xa server with 4x NVIDIA L40S GPUs. The NVIDIA L40S GPU offers competitive inference performance by offering the benefit of 8-bit floating point (FP8 precision) support.
Applying FP8 quantization to store the model weights in memory in lower floating point precision, we were able to get excellent results while running the model in a smaller memory footprint than we otherwise would. These results further reinforce OpenShift AI's capability to deliver high-performance LLM inference, enabling enterprises to efficiently deploy and scale AI applications in production environments. With 1,718 tokens/sec in offline mode [1] this result highlights significant performance improvements to the vLLM project which we are excited to discuss in this article.
MLPerf background
MLPerf Inference is a suite of industry-standard AI/ML inference benchmarks created by MLCommons. MLCommons is an AI engineering consortium with support from across the industry, including hardware companies, cloud vendors and software companies.
Llama-2-70b is one of the LLMs included in the MLPerf Inference suite of benchmarks. This benchmark includes two scenarios, Offline and Server. Offline mode highlights the raw throughput that the system-under-test is capable of while batch processing the entire dataset of queries. Server mode simulates an interactive scenario where requests are sent to the system under test one at a time by the MLPerf load generator, following a Poisson distribution, to issue requests at a specified average requests/sec rate. For OpenShift AI users, these benchmarks provide valuable insights into the platform's capabilities for running LLM inference under high load.
Results
The results of the Llama-2-70b MLPerf Inference benchmark are a measurement of throughput in the two separate scenarios, Offline mode and Server mode. In v4.1, we were able to achieve a throughput of 1717.77 tokens/sec in Offline mode and 1469 tokens/sec in Server mode [2] with vLLM and OpenShift AI running on a server with 4xL40S GPUs. The throughput achieved in Offline mode demonstrates the performance you can achieve on this platform when running offline batch-inference workloads such as synthetic data generation, document summarization, text classification and more.
The Server mode simulates a server use case like conversational AI, where requests are arriving one-at-a-time at a variable rate. The average request rate that we were able to achieve in server mode was 4.97 requests per second. The 1469 tokens/sec throughput was achieved while meeting the maximum latency threshold for Server mode of two seconds time-to-first token and a 200ms latency per token average. The mean token length of the output was 295 tokens, which is representative of conversational use cases with conversational use-cases.
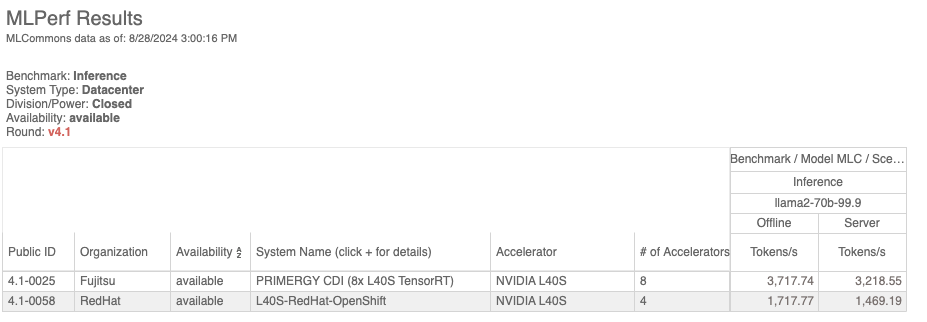
The full list of results from all submitters is available on the MLCommons website.
Technical highlights
vLLM is a quickly evolving open source project with an active community of contributors from across the industry. As of OpenShift AI version 2.10, OpenShift AI includes vLLM as a supported runtime.
Compared to our previous MLPerf Inference submission, we were able to leverage several vLLM runtime enhancements to improve performance. The previous submission was done on a server with 8 x NVIDIA H100 Tensor Core GPUs, and in this round we achieved approximately 55-65% of the throughput on a server config that is approximately 15% of the cost. In our previous submission, we used a vLLM container image based on vLLM version 0.3.1. In this round we used a custom image based on version 0.5.1 which includes several performance improvements thanks to the work of the upstream vLLM community.
FP8 quantization
In this round we deployed the model using FP8 quantization, where the model weights and activations that are normally represented by 16 or 32 bit floating point numbers are converted down to 8 bit floating point numbers. At this reduced precision, we were still able to meet the required accuracy for the benchmark, while improving performance in several ways. Quantization is increasingly common in production model serving because of the performance gains that are possible with negligible loss in accuracy. Before deploying the model, we utilized the auto_fp8 tool to quantize the Llama-2-70b-chat-hf model to FP8 precision with static activation scaling factors as documented in the vLLM documentation.
By switching from FP16 to FP8, we reduce the GPU memory required to load the model from ~140GB to ~70GB. This allows us to run the model in a smaller hardware footprint, on 2xL40S instead of 4xL40S GPUs, with each L40S GPU having 48GB of GPU memory.
Freeing up more GPU memory with quantization also leaves more space for the KV-cache, which increases the maximum number of sequences that can be processed concurrently in a batch. Another benefit of “shrinking” the model with quantization is that less memory bandwidth is needed to read the model weights from GPU memory during each forward pass of the model. GPU hardware like NVIDIA L40S GPUs also support computation at FP8 using their FP8 Tensor Cores. In vLLM the linear layers of the model are able to run on these cores, resulting in accelerated computation of these layers.
Tensor parallelism and model replicas
In our testing we were able to achieve higher throughput in this benchmark with two model replicas each on 2xL40S GPUs than with one replica on 4xL40S GPUs. Increasing the degree of tensor-parallelism (i.e., the number of GPUs used to split the model) expands the available GPU memory for the KV-cache, enabling larger batch sizes. However, this implementation also introduces additional overhead due to inter-GPU communication, resulting in higher latency. When KV-cache space isn’t a major constraint, the throughput gain from doubling tensor-parallelism is typically less than 2x, and running two independent instances of the model can provide better throughput and latency. For use cases requiring more KV-cache space, where most requests have longer sequence lengths (e.g. retrieval augmented generation (RAG)), a single instance on four GPUs might perform better.
Other recent enhancements of vLLM which helped enable these results include the chunked-prefill feature, Python multiprocessing backend for tensor-parallelism and better flash attention kernels.
Architectural overview

In this submission, we used OpenShift AI 2.11 and the OpenShift AI model serving stack based on KServe. KServe simplifies many aspects of model deployment like autoscaling, networking, health checking and runtime configuration. Although the MLPerf benchmark is most similar to large scale batch inference use cases, features of Red Hat OpenShift Serverless help minimize latency for real-time use cases. For example, Knative least-requests load balancing where requests are forwarded to the instance with the least number of requests helps to balance load, minimizing per-token latency for each user.
The code for our implementation of this benchmark is available on Github. The model was deployed on the OpenShift AI model serving stack using a custom runtime with the vLLM image quay.io/wxpe/tgis-vllm:2a60ad3 which had slightly newer features from the upstream project than the version included in OpenShift AI 2.11 at the time of submission.
In our submissions, we deployed 2 replicas of the model in RawDeployment mode, each with a separate endpoint. This was achieved by simply creating two separate InferenceService custom resource objects, and the OpenShift AI model serving stack orchestrates the deployment and networking, exposing the model endpoints.
The test harness dispatches requests differently depending on whether the test is being run in Offline or Server mode. In Offline mode, the test harness sent large batches of 1000s of requests in a round-robin fashion to each replica, and in Server mode the test harness sent one request at a time, round-robin, as it is dispatched by the MLPerf load generator.
In subsequent testing since the time of submission, we have been able to achieve better performance in Server mode of this benchmark by utilizing the Serverless deployment mode in OpenShift AI. This provides load-balancing based on least requests, which does a better job of distributing the load across replicas than round-robin. This is ideal for real-time applications like chatbots, and enables administrators to make more efficient use of the underlying hardware resources by automatically scaling model replicas as needed.
What's next for OpenShift AI users
Since the time of the submission, there have been significant performance improvements upstream in the vLLM project. Check out the v0.6.0 announcement blog which describes how the vLLM community has been able to improve throughput as much as 2.7x in some cases. There has also been even more work in upstream vLLM to improve FP8 performance. Join the active community of vLLM contributors to stay on top of the latest innovations, and help to push the boundaries of AI inference.
We are continuing to analyze inference workloads and test the latest advancements in model and runtime optimizations to improve the performance of OpenShift AI for large language models like Llama-2-70b.
Curious how your infrastructure could benefit? Try running your LLM of choice on OpenShift AI to see how it can help optimize your AI/ML model serving infrastructure.
---
[1] Verified MLPerf® score of v4.1 Inference Closed Llama2-70B-99.9 Offline. Retrieved from https://mlcommons.org/benchmarks/inference-datacenter/ 07 November 2024, entry 4.1-0058. The MLPerf name and logo are registered and unregistered trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use strictly prohibited. See www.mlcommons.org for more information.
[2] Verified MLPerf® score of v4.1 Inference Closed Llama2-70B-99.9 Server. Retrieved from https://mlcommons.org/benchmarks/inference-datacenter/ 07 November 2024, entry 4.1-0058. The MLPerf name and logo are registered and unregistered trademarks of MLCommons Association in the United States and other countries. All rights reserved. Unauthorized use strictly prohibited. See www.mlcommons.org for more information.
About the authors
David Gray is a Senior Software Engineer at Red Hat on the Performance and Scale for AI Platforms team. His role involves analyzing and improving AI model inference performance on Red Hat OpenShift and Kubernetes. David is actively engaged in performance experimentation and analysis of running large language models in hybrid cloud environments. His previous work includes the development of Kubernetes operators for kernel tuning and specialized hardware driver enablement on immutable operating systems.
David has presented at conferences such as NVIDIA GTC, OpenShift Commons Gathering and SuperComputing conferences. His professional interests include AI/ML, data science, performance engineering, algorithms and scientific computing.
Diane Feddema is a Principal Software Engineer at Red Hat Inc in the Performance and Scale Team with a focus on AI/ML applications. She has submitted official results in multiple rounds of MLCommons MLPerf Inference and Training, dating back to the initial MLPerf rounds. Diane Leads performance analysis and visualization for MLPerf benchmark submissions and collaborates with Red Hat Hardware Partners in creating joint MLPerf benchmark submissions.
Diane has a BS and MS in Computer Science and is presently co-chair of the Best Practices group of the MLPerf consortium.
More like this
Why self-hosted inference is essential: Building a reliable, sovereign inference layer
Make every GPU-hour count: Progress tracking in Red Hat OpenShift AI
Technically Speaking | Defining sovereign AI with open source
Technically Speaking | Inside open source AI strategy
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds