
On November 29, we launched Red Hat Ansible Automation Platform 2.3, which included new and exciting features including improvements for Configuration as Code (CaC). Ansible Automation Platform 2.3 also includes improvements to automation controller as well as the introduction of Ansible validated content. This blog post will walk you through what CaC is and the benefits it can bring to your organization, including a UI and API walkthrough of automation controller and how to take a full Configuration as Code approach to your automation infrastructure.
What is Configuration as Code (CaC) in Ansible Automation Platform?
CaC is a term generally referring to the separation of configuration settings from the actual code. The ideal being you can store that configuration data in source control, and easily run and tweak it to match different environments.
In Ansible Automation Platform terms, we can use the features within the automation controller in combination with CaC to provide a more flexible, richer experience. Essentially we’ve added "Prompt on Launch" to everything within a job template, many of which will also trickle down into workflows.
"Prompt on launch" is our Ansible Automation Platform way of saying "this is the last stop", which will have the highest precedence and overrule the defaults in the template. This means it’ll be the final configuration choice for the automation run.
These improvements allow us to utilize a CaC approach to running automation. More on how to do that a little later.
Benefits
- This now allows you to reduce the number of templates you may need to match all the different environments and combinations of runtime configurations required.
- Previously, many customers told us they would need to copy many templates and make the required changes for each environment. No more!
- Pass configuration variables at runtime without making playbook changes.
- It enables you to develop even more generic playbooks, which utilize these variables at runtime.
- You can use the same approach whether using the Collection, CLI, UI or calling the API.
UI Changes
If we look at a job template, you’ll see that there are now only a few items that aren’t promptable on launch. These are the job template name, description, project and playbook, which are the minimum information required to define a job template. Everything else is now promptable!

As an example, if I change the demo job template as supplied, to prompt on launch for the Inventory to run against, the Execution Environment to use, the Credentials to be supplied and the Instance Group to run against, hopefully you can see just how powerful this feature is:

Also notice that there is a new “Prevent Instance Group Fallback” option:

Previously, a job template could be run on any of the following instance groups:
- Instance groups added to the job template
- Instance groups added to the inventory the job template is being run on
- Instance groups added to the organization the job template is part of
- The default instance group
In some cases, you may not want to allow the addition of instance groups from other sources on a job template. This is now possible by enabling "Prevent Instance Group Fallback". This option resides on both the job templates and inventories and will prevent the above fallback sequence from happening. This is particularly useful if you want to mandate that automation only runs against certain instance groups, for instance those in DMZs where no other connectivity is possible.
There are two important notes to include on this behavior:
- If you enable "Prevent Instance Group Fallback" on a job template but don’t provide instance groups on the job template, it has to fallback. The same applies for inventory.
- Providing a list of instance groups as a prompt on launch of a job template automatically implies "Prevent Instance Group Fallback", even if it’s not checked.
So back to running the demo job template with those options enabled:
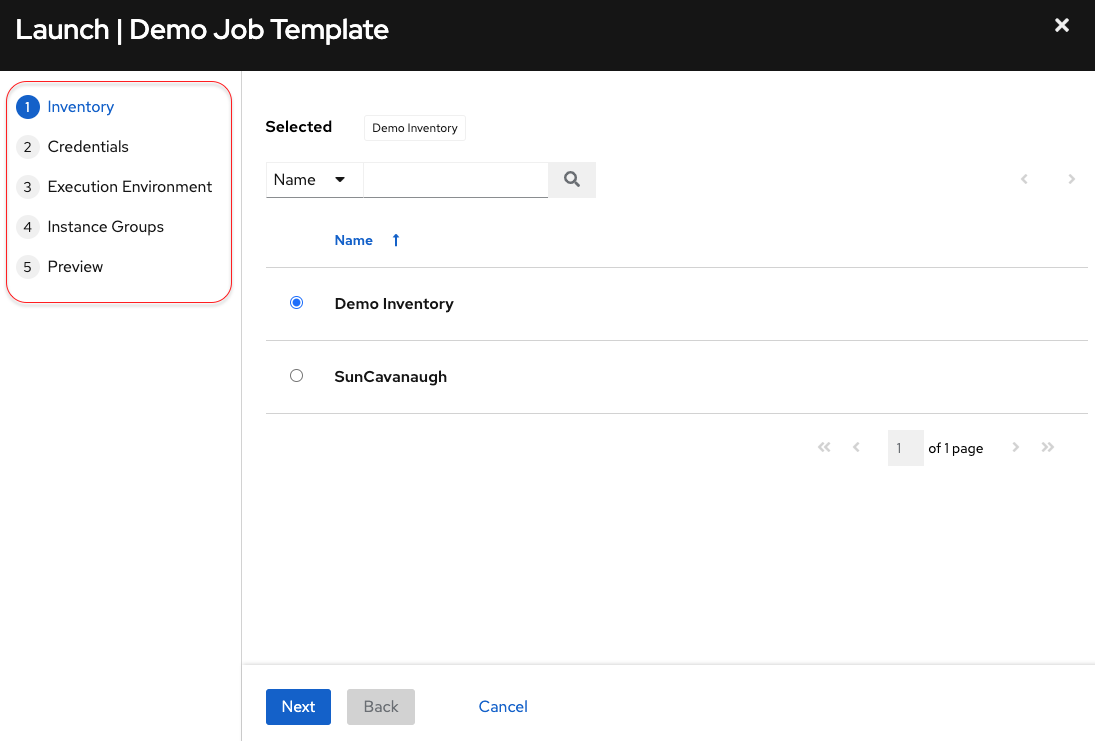
One can see it’s guiding me through those choices. I can now run the template, where and how I like to fit my needs:
- I want to run this automation against different hosts somewhere (Inventory)
- I need to provide different credentials for this particular run (Credentials)
- I want to test the template against different execution environments (Execution Environment)
- I want to change where this automation normally runs (Instance Group)
Hitting the API
What about if you only use the API to launch automation jobs? No problem, we have you covered here as well.
If we look at the browsable automation controller API for the demo job template (ID 7) and scroll down to the bottom of the details, you’ll see the new fields listed and their settings:
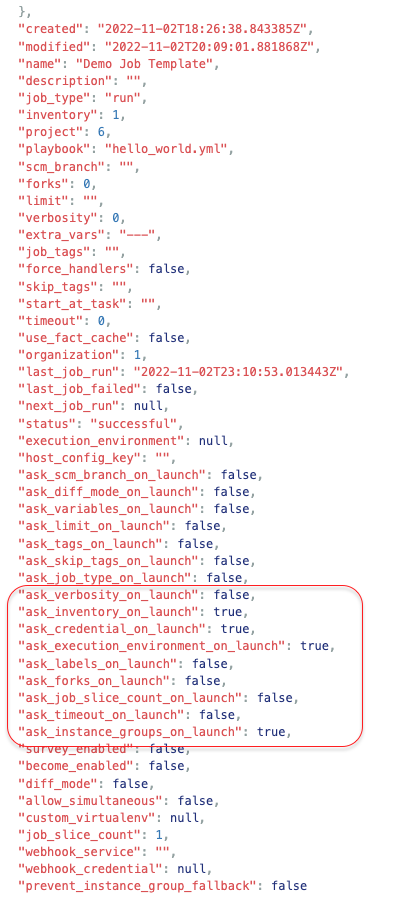
Notice the fields I changed are now set to true (for prompt on launch).
We support a number of authentication methods for accessing the automation controller, but we recommend using OAuth2 tokens. I’ll not cover how to create a token here as it’s covered in the documentation, so check the above link out for more details.
If we know the job template ID we can call that directly, but I like to use the unified name using the named_url, as we can reference the name rather than ID.
If we use curl to fire off the request and pipe the output to jq, we’ll get some nice formatted, readable output. Right now, you need to be a System Administer to be able to do this, as there are objects which reside outside of an organization level (we’ll work on refining that in a future release).
We’ll just get the Job ID back so we can go view the output in the UI. Notice that I’m not passing in Inventory or Credentials changes, so we can also rely on the job template defaults if we want.
Notice instance_groups has a list of two parameters. We can pass more than one instance group to the automation run. It’ll use the first if there is capacity, falling back to the second if not. This may be useful if you’re concerned about execution capacity, or you want to target a particular instance group for the run.
curl -s -k -X POST -H "Authorization: Bearer VCq0iVVjPtbdRvPFfmMEvc8OqCCn5R" -H "Content-Type: application/json" --data '{"execution_environment": "4", "instance_groups": [1,2]}' https://10.0.23.100/api/v2/job_templates/Demo%20Job%20Template++Default/launch/ | jq .job
53 (output is the Job ID) If we go back into the UI, we can see the runtime parameters that were used in the job:
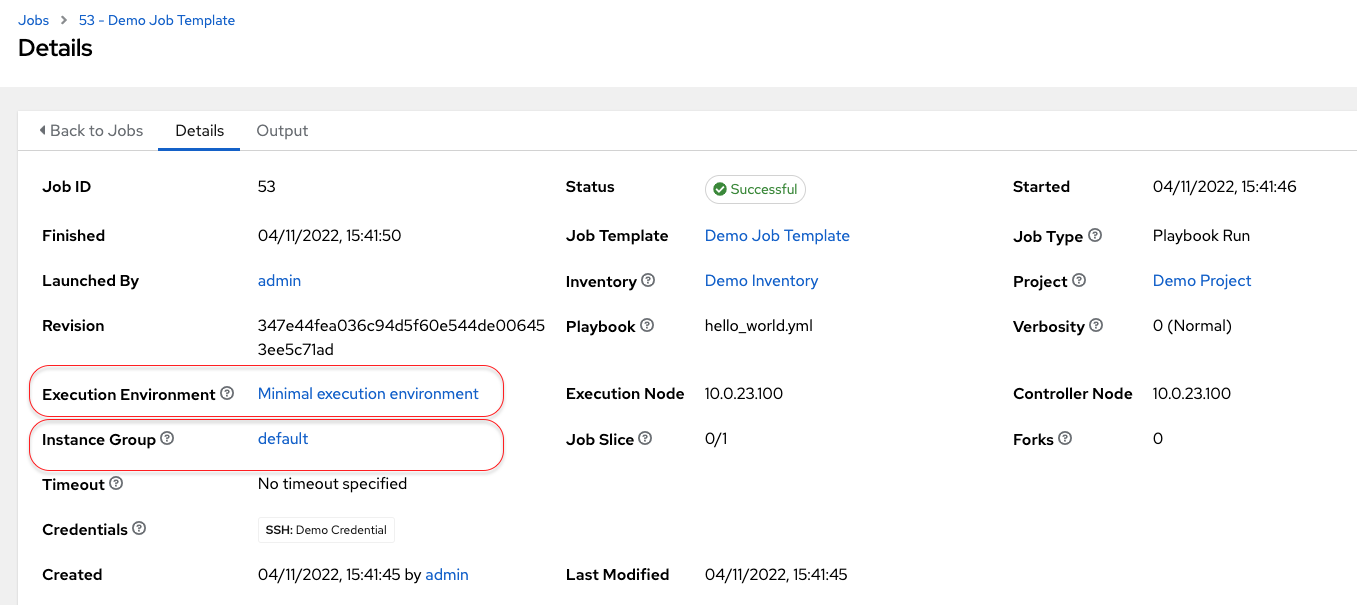
Note that even though we passed in two instance groups to run on, the details page only shows the instance group which was selected to run the automation.
The Full CaC Experience
We can combine this exciting new enhancement with my go to for this purpose, the Red Hat Communities of Practice Controller Configuration Collection. This has a plethora of roles in order to do all sorts of management, configuration and runtime.
This collection is so useful that it has become validated content with the release of Ansible Automation Platform 2.3. There will be similar Ansible validated content for Hub configuration, execution environments and Ansible Automation Platform utilities (look for infra.* collections in Ansible automation hub).
There is a role for launching job templates, where we can pass vars in. Let’s look at the repo example:

You could just ansible-galaxy install this Collection, but I’ve Git cloned it, installed the requirements and then using this example, I’ve created:
configs/credentials.yml
controller_credentials:
- credential_type: Red Hat Ansible Automation Platform
name: Controller
inputs:
host: 10.0.23.100
oauth_token: VC********
verify_ssl: falseThis defines the automation controller host I’m going to use, any optional connection parameters and the authorization method. Here we’re using the "Red Hat Ansible Automation Platform" credential type, which should work for the majority of use cases. There are a number of other ways to set this up; details are in the repo (like setting controller_vars).
run_jt_cac.yml
This is my generic playbook for running jobs. All I’ve added is where to find my controller config and the CaC config:
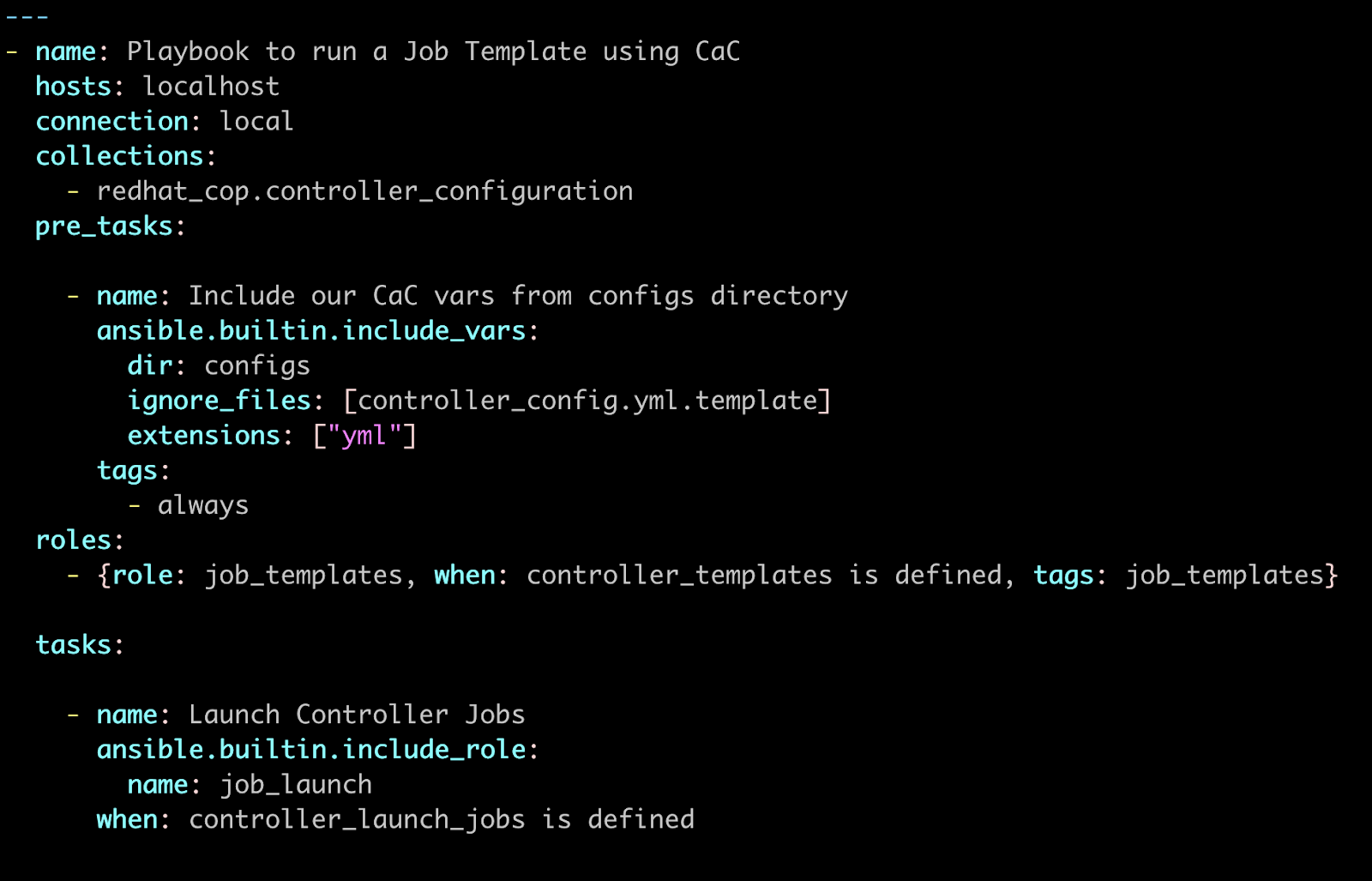
Now all we need to do is define your CaC to pass to the above playbook:
configs/jt_cac.yml

We can make this even more human readable, as the collection uses lists, YAML, and even the "real" non item numbered configuration values, one of the benefits of CaC as the modules do the lookups for you.
---
controller_launch_jobs:
- name: Demo Job Template
execution_environment: Automation Hub Minimal execution environment
instance_groups:
- default
- controlplane
inventory: Demo Inventory
- name: Demo Job Template
execution_environment: Ansible Engine 2.9 execution environment
instance_groups:
- SunCavanaugh Cloud
inventory: SunCavanaugh Industries
...So we’re running the same demo template twice, but simply defining what we want to run for each using different parameters. No code change, simply configuration data!
Now let’s run the playbook, and observe the results:
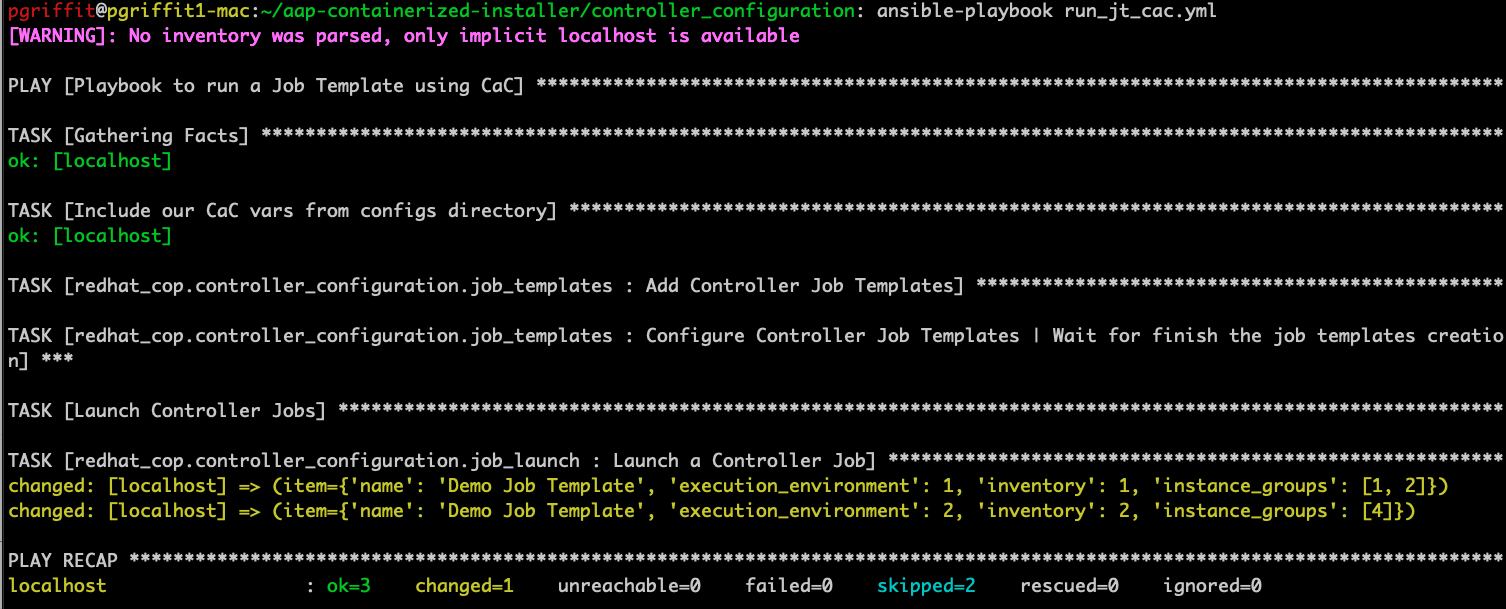
Back in the UI, the first job output shows:

And the second showing the different parameters used:

Neat!
Summary:
These CaC improvements provide a much more flexible runtime configuration, helping you reduce the number of hardcoded templates you previously might have needed for the right environmental mixes.
The Red Hat Communities of Practice Controller Configuration Collection even has a dispatch role which provides you with a mechanism to load any CaC found, without having the specify individual items like job templates and projects.
Develop even more generic playbook solutions that utilize configuration data as runtime parameters, allowing you to reach and automate when, where and how you need to.
Where To Go Next:
Check out the documentation for the new "Prompt on Launch" enhancement that enable Configuration as Code for automation controller.
Also, checkout the awesome Red Hat Communities of Practice Controller Configuration Collection that makes this all possible.
We are also looking to add a post install role to the current Ansible Automation Platform installer, which will provide a way to land CaC into automation controller as part of your installation process. So you will be able to not only install Ansible Automation Platform, but seed your configuration content at the same time!
Many thanks to Shane McDonald, John Westcott and Sean Sullivan in particular for their contributions to this article.
About the author
Phil Griffiths is a Product Manager for Ansible Automation Platform with nearly seven years of experience at Red Hat. Phil has held roles as a solution architect and technical consultant both at Red Hat and for other organizations.
More like this
Provide access to Red Hat documentation in environments with limited connectivity
BackendTLSPolicy expands Gateway API transport security
Untangling Networks | Compiler
Technically Speaking | Defining sovereign AI with open source
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds