
Apache Kafka has proven to be an extremely popular event streaming platform, with the project reporting more than 60% of Fortune 100 companies using it today. Developed by the Apache Software Foundation in 2011, Apache Kafka is an open source software platform that can publish, subscribe to, store, and process streams of records in real time.
But what even is an event streaming platform? Heck, what do half the things in Kafka mean?
The concepts of Kafka producers, consumers, topics, partitions, and so on can be hard to grasp for newcomers to Kafka. So if you find yourself scratching your head at anything Kafka related, this is the right article for you.
Covering everything from the publish-subscribe messaging pattern to Kafka Connect, here are 10 essential Apache Kafka terms and concepts to get you started on your Apache Kafka journey.
1. Publish-subscribe messaging pattern
Apache Kafka is a publish–subscribe based messaging system. What does that mean?
A messaging pattern is simply a way messages (a fancy word for bits of data) are transmitted between a sender and receiver. There are multiple messaging patterns out there (for example, fan-out or request–response), but we’ll focus on the publish–subscribe messaging pattern for our purposes. With publish-subscribe messaging, senders (also called publishers) send messages to multiple consumers (also called subscribers) using a single destination. This destination is often known as a topic.

Figure 1. The publish-subscribe messaging workflow. Source.
Each topic can have multiple subscribers, and every subscriber receives any message published to the topic. Topics allow for instantaneous, pull-based delivery of messages to subscribers, which is one reason why in a publish–subscribe-based messaging system (such as Apache Kafka), you can handle high volumes of data in real time.
2. Event streaming
Event streaming is an implementation of the publish-subscribe messaging pattern with added capabilities. Since Apache Kafka is an event streaming platform, not only can it publish and subscribe to streams of events, but also store and process them as they occur.
In event streaming, an event (also called a message or record) is simply a record of a state change in the system. In a payment processing use case, for example, an event might be that a customer has completed a financial transaction.
An event stream is a sequence of events where events flow from publishers to subscribers. Again, in a payment processing use case, an event stream could be the continuous flow of real-time information about the financial transactions happening in your business.
3. Kafka clients and servers
Before we dive into how clients, servers, and the Transmission Control Protocol (TCP) work in Kafka, it’s helpful to know that Kafka is a distributed system. A distributed system is a computing environment where various software components located on different machines coordinate together to get stuff done as one unit.
Kafka’s distributed system is made up of a cluster of one or more servers (called Kafka brokers) that can span multiple datacenters (or cloud instances) and clients, allowing you to create applications that communicate with Kafka brokers to read, write, and process streams of events.
Servers and clients in Kafka coordinate via a custom binary format over TCP, a communications standard that connects a server and a client and enables them to exchange messages with each other.
4. Producers, and Consumers, and Consumer groups
Stepping outside of a Kafka cluster, we will find the applications that use Kafka: producers and consumers. Producers are applications you write that put data into topics (explained below) and consumers are applications that read data from topics.
If you're limited to a single consumer, your application might not catch up with all of the messages streaming in from a topic partition. By pulling multiple consumers together in a consumer group, however, Kafka allows for multiple consumers to read from multiple topic partitions, increasing messaging throughput.
In a consumer group, multiple consumers read from the same topic, but each consumer reads from exclusive partitions, which we’ll further explain in No. 6.
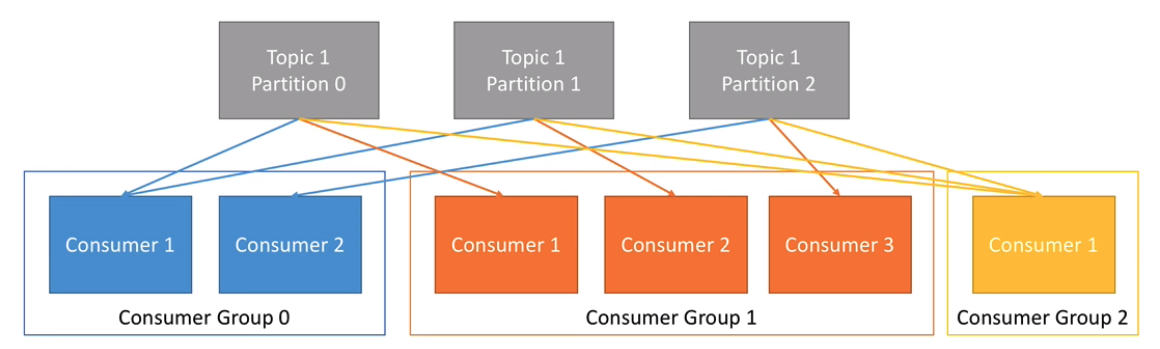
Figure 2. Consumer groups. Source
5. Kafka clusters and Kafka brokers
As the name suggests, a Kafka broker arranges transactions between producers and consumers. Brokers handle all requests from clients to write and read events. A Kafka cluster is simply a collection of one or more Kafka brokers.
6. Kafka topics & Kafka partitions
Remember when we talked about event streams? Well, it goes without saying that there can be a lot of events going on at once—and we need a way to organize them. In Kafka, the fundamental unit of event organization is called a topic.
A topic in Kafka is a user-defined category or feed name where data is stored and published. Put another way, a topic is simply a log of events. In a website activity tracking use case, for example, there might be a topic with the name of “click” that receives and stores a “click” event every time a user clicks on a certain button.
Topics in Kafka are partitioned, which is when we break a topic into multiple log files that can live on separate Kafka brokers. This scalability is important not only because it allows client applications to publish/subscribe to many brokers simultaneously, but also because it ensures high data availability since partitions are replicated across multiple brokers. If one Kafka broker in your cluster goes down, for example, Kafka can safely failover to partition replicas on the other brokers.
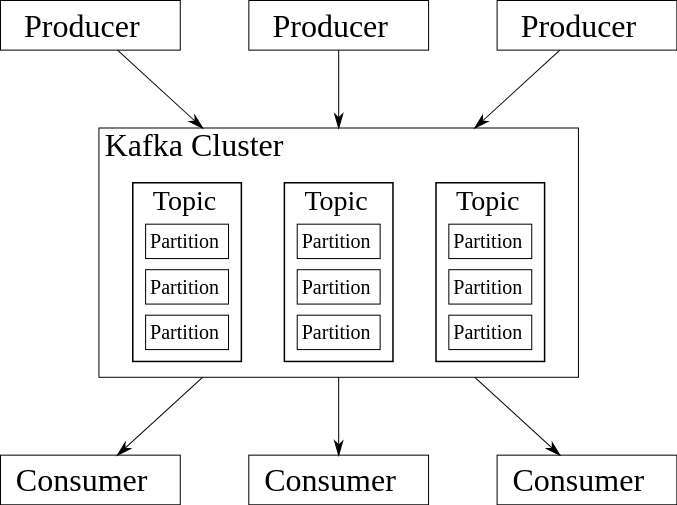
Figure 3. Example Kafka architecture. Source
{kind=link}
Lastly, we need to talk about how events are ordered in partitions. To understand this, let’s return to our website traffic activity use case. Say we split our “click” topic up into three partitions.
Every time our web client publishes a “click” event to our topic, that event will be appended to one of our three partitions. If a key is included with the event payload, this will be used to determine the partition assignment, otherwise events are sent to partitions in a round robin fashion. Events are added and stored within partitions sequentially, and the individual ID that each event gets (e.g., 0 for the first event, 1 for the second, and so on) is called an offset (see Figure 3).
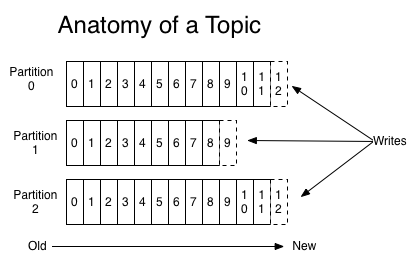
Figure 4. Anatomy of a Kafka topic. Source
7. Kafka topic replication, leaders, and followers
We mentioned in the previous section that partitions can live on separate Kafka brokers, which is a key way that Kafka secures against data loss. This is accomplished through setting the topic replication factor, which specifies the number of copies of data over multiple brokers.
For example, a replication factor of three will maintain three copies of a topic for every partition in other brokers.
To avoid the inevitable confusion of having both the actual data and its copies present in a cluster (e.g., how will a producer know which broker to publish data to for a particular partition?), Kafka follows a leader-follower system. That way, one broker can be set as the leader of a topic partition and the rest of the brokers as followers for that partition, with only the leader being able to handle those client requests.
8. Apache ZooKeeper
In a production environment you will probably use Kafka with Apache Zookeeper, another project of the Apache Software Foundation. In a nutshell, ZooKeeper is a centralized service that helps you coordinate and manage distributed applications.
Remember how we said Kafka is a distributed system? Well, Zookeeper is what Kafka uses to coordinate a variety of distributed tasks, including performing elections (controller and topic leaders), topic configuration (maintaining a list of topics, how many partitions each has, etc.), storing metadata (such as the location of partitions), tracking the status of Kafka Brokers, and so on.
(Zookeeper is being phased out starting with Apache Kafka 3.0.0)
9. Kafka Connect
Kafka Connect is a data integration framework for Apache Kafka. Basically, Kafka Connect is what helps you get data into a Kafka cluster from some outside source like a message-queue or relational database. It’s also what can help you get data out of a cluster (so that you can store or sync it somewhere else).
It achieves this with connectors, which are reusable pieces of code you use to connect to common data stores. Since spinning up your own connectors is really tough, it’s common for developers to just use preexisting connectors developed and supported by the Kafka community.
There are two sorts of connectors in Kafka. Source connectors are connectors that get data from a data store, while sink connectors are connectors that deliver data from Kafka topics into a data store.
10. Kafka Streams
Kafka Streams is a Java API for building streaming applications that can process and transform data inside Kafka topics. In a nutshell, Kafka Streams lets you read data in real time from a topic, process that data (such as by filtering, grouping, or aggregating it) and then write the resulting data into another topic or to other systems of record.
Red Hat OpenShift Streams for Apache Kafka
Congratulations! You should now have a solid understanding of some of the basics terms and concepts of Apache Kafka. Understanding producers, consumers, consumer groups, and other terms in the Kafka lexicon is no easy feat, so go ahead and pat yourself on the back.
For as easy as Apache Kafka can make things, however, there are plenty of things that make it a hassle to deal with.
For example, there is no data verification in Apache Kafka—your consumers might not be able to understand the data coming from producers since there are no well-defined data schemas. There’s also the pain of dealing with the Day 2 operations of Apache Kafka, doing all administrative work such as monitoring, logging, upgrades, etc.
Red Hat OpenShift Streams for Apache Kafka, a managed cloud service, is designed to help alleviate many of these challenges. It goes farther than core Kafka technology because of what comes packaged alongside it: OpenShift Streams for Apache Kafka includes a Kafka ecosystem and is part of a family of cloud services—and the Red Hat OpenShift product family—that help you build a wide range of data-driven solutions.
The best part? You can get started and try the Red Hat OpenShift Streams for Apache Kafka hosted and managed service right now (and connect to any application) at no cost!
Additional resources
Blog post
3 common challenges of using Apache Kafka
Documentation
Red Hat OpenShift Streams for Apache Kafka product documentation
Get the e-book
Event mesh: A primer
Watch the webinar
Understanding Kafka in the Enterprise
Read the blueprint
Event-driven architecture for a hybrid cloud blueprint
About the author
Bill Cozens is a recent UNC-Chapel Hill grad interning as an Associate Blog Editor for the Red Hat Blog.
More like this
The future of AI demands a hybrid foundation
OpenShift Virtualization 4.21: Removing complexity from your virtual machine networking workflow
Technically Speaking | Inside open source AI strategy
Collaboration In Product Security | Compiler
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds