
Background
In Architecting Containers Part 4: Workload Characteristics and Candidates for Containerization we investigated the level of effort necessary to containerize different types of workloads. In this article I am going to address several challenges facing organizations that are deploying containers - how to patch containers and how to determine which teams are responsible for the container images. Should they be controlled by development or operations?
In addition, we are going to take a look at
what is really inside the container - it’s typically a repository made up of several layers, not just a single image. Since they are typically layered images, we can think of them as a software supply chain. This software supply chain can address mapping your current business processes and teams to the container build process to meet the needs of a production container deployment in a flexible and manageable way.
Red Hat has always been concerned with creating an enterprise class user space. Since the beginning, our solution has been Red Hat Enterprise Linux, and that doesn’t change in a containerized world - what does change, is how people consume the user space inside a containerized software supply chain.
Traditional Supply Chain (Today)
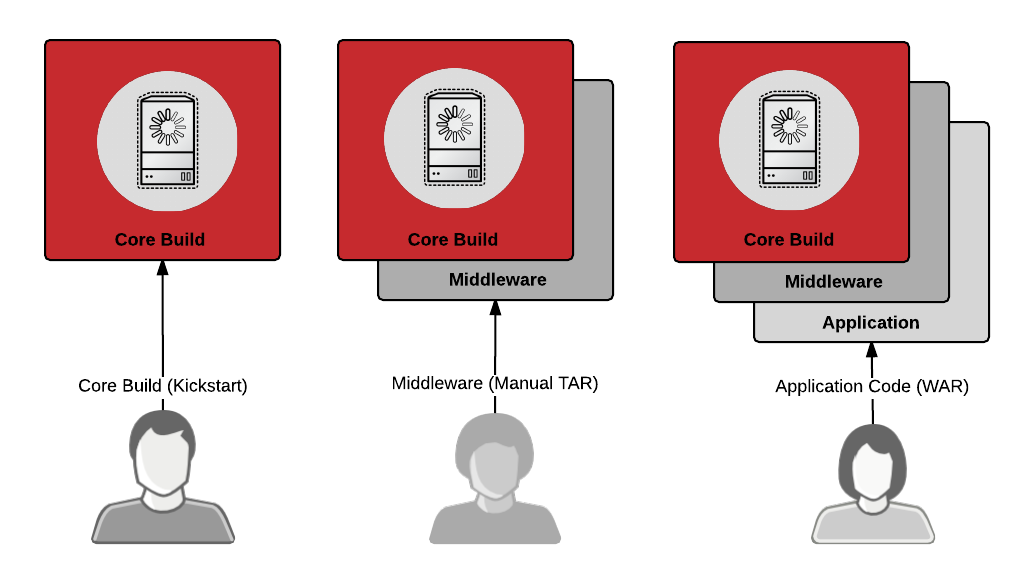
Let’s start with a look at how things are commonly “done” today in a non-containerized environment. Operations, middleware and development teams each have responsibility for different pieces of what gets deployed into production.
When a new project begins, the operations team sets up a physical or virtual server, lays down a fresh operating system and does some initial configuration to meet various corporate protocols and/or security policies. The resulting image is often called a core build, gold build, or standard operating environment.
Once the operations team is finished with a new server, they often hand it off to an application delivery team. This could be a specialist team that focuses on databases, Java application servers, message buses, integration software, or even Web servers. The specialist team will further configure the server to their standards. In this article, I will refer to these teams as “middleware”.
Finally, if the server is meant to be a development platform, access will be given to the development team. At this point, the development team will begin to work on their code.
This deployment process has historically been replicated for development, testing, and production environments (...amounting to a lot of work). Also, today, each team generally deploys their software using a different methodology and artifact/package format.
Below is a list of common package formats and artifacts that are used by each team:
- Development: simple text files (Python, Ruby, Node.js), EAR/WAR files, or executables
- Middleware: tar files (Java), RPMs (MySQL, PostgreSQL), Ruby Gems, or PHP PEAR objects
- Operations: RPMs (security updates, bug fixes), tar files, and Puppet/Chef/Ansible to modify files
The way software is deployed today has some serious downsides:
- Slow because each team can only start their work after the last team has finished their part.
- Difficult to change because each team uses their own set of tools.
- Difficult to understand what has been changed because each team has their own methodologies; some may use automation while others may change things manually.
- Tracking changes is difficult because there is no temporal (when) or spacial (what) record between teams; often it is a hand off in a ticketing system.
Many have tried to solve these problems by standardizing on one tool, but this has always been painful. Each format has its own strengths and weaknesses. For example, RPMs are good for tracking provenance, but require gymnastics when installing multiple versions of the same software (scl enable anyone?). TAR files (and others like GEMS, PIP, and CPAN) with less metadata are good at installing multiple copies but do not provide the ability track when they are updated or where they came from. Operations wants some form of governance because they get called in the middle of the night, while developers just want to push their files and go.
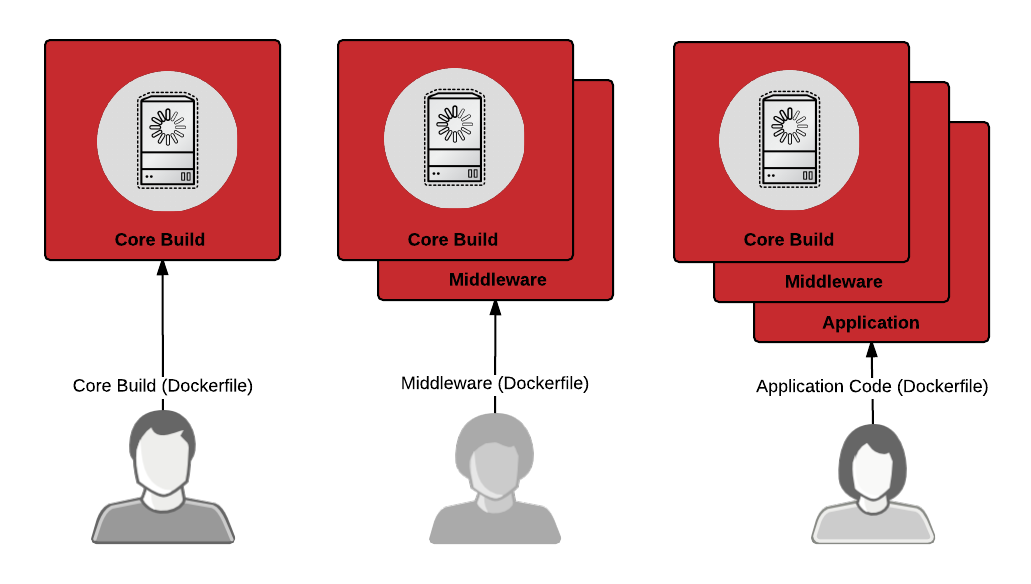
A Converged Software Supply Chain
And, this is where containers enter the picture. Adopting a standardized build methodology and artifact format allows each team to retain control over the bits they care about while maintaining a clean hand off to teams that will consume their work:
- Format: The Docker format provides each team a way to easily share the output of their work.
- Build: Building from Dockerfiles encourages transparency and collaboration between teams.
- Deploy: Build artifacts allow the deployment logic to be completely separated from the the build logic.
- Isolation: Teams can operate at different speeds (temporal) and on different software (spatial).
Operations can update the underlying standard operating environment - developers can change their applications as much as they like - both teams have confidence that the final build artifact will run correctly in production. This allows clean separation of temporal and spatial concerns - teams can operate at different speeds, only changing their pieces of the container repository. Incompatibilities can now be found during the build instead of the deploy. Tests can be used to provide confidence. Tests can be augmented when problems are discovered and resolved.
The separation of responsibilities between operations, middleware and development doesn’t have to go away in a containerized world - Linux containers can help to streamline the development, deployment, and management of applications through a solid supply chain methodology.
Analyzing Existing Supply Chains
One of the first questions asked is, who else is doing this? The answer is, anyone that has containers in production. There are several examples of public containerized multi-tier software supply chains. In this section, we are going to analyze several of them: DockerHub Official Images, Red Hat Software Collections/OpenShift, and a custom supply chain that I built for my own use and as a demo.
Before we can analyze the container supply chain which is embedded in the the docker repositories, we are going to need a tool. Regretfully, this tooling used to be built into Docker, but was removed. Luckily, Nate Jones built an awesome little tool called DockViz. We are going to use DockViz to analyze several different supply chains.
Docker Hub
We are going to analyze the wordpress image on Docker Hub because it is a very popular place to pull images from. The wordpress image is tagged so that users can select different versions of wordpress, for example, built on Apache, or FPM.
Docker Hub also provides links to the Dockerfiles which were used to build the images - see Apache or FPM as examples. This is great to get a better understanding of how a software supply chain should be setup. One downside is there are a lot of different tags in the repository and it can be difficult to understand which version you need.
These images are great for getting started, but what happens if you want a wordpress image built on a specially hardened version of Apache, or a NGINX? What if you have a standard operating environment built on Red Hat Enterprise Linux? You could go to the community and see if there is something that meets your needs, but this is a Turing Complete problem. Users could want millions of different permutations of images and Docker Hub cannot possibly build images for every given user’s particular needs.
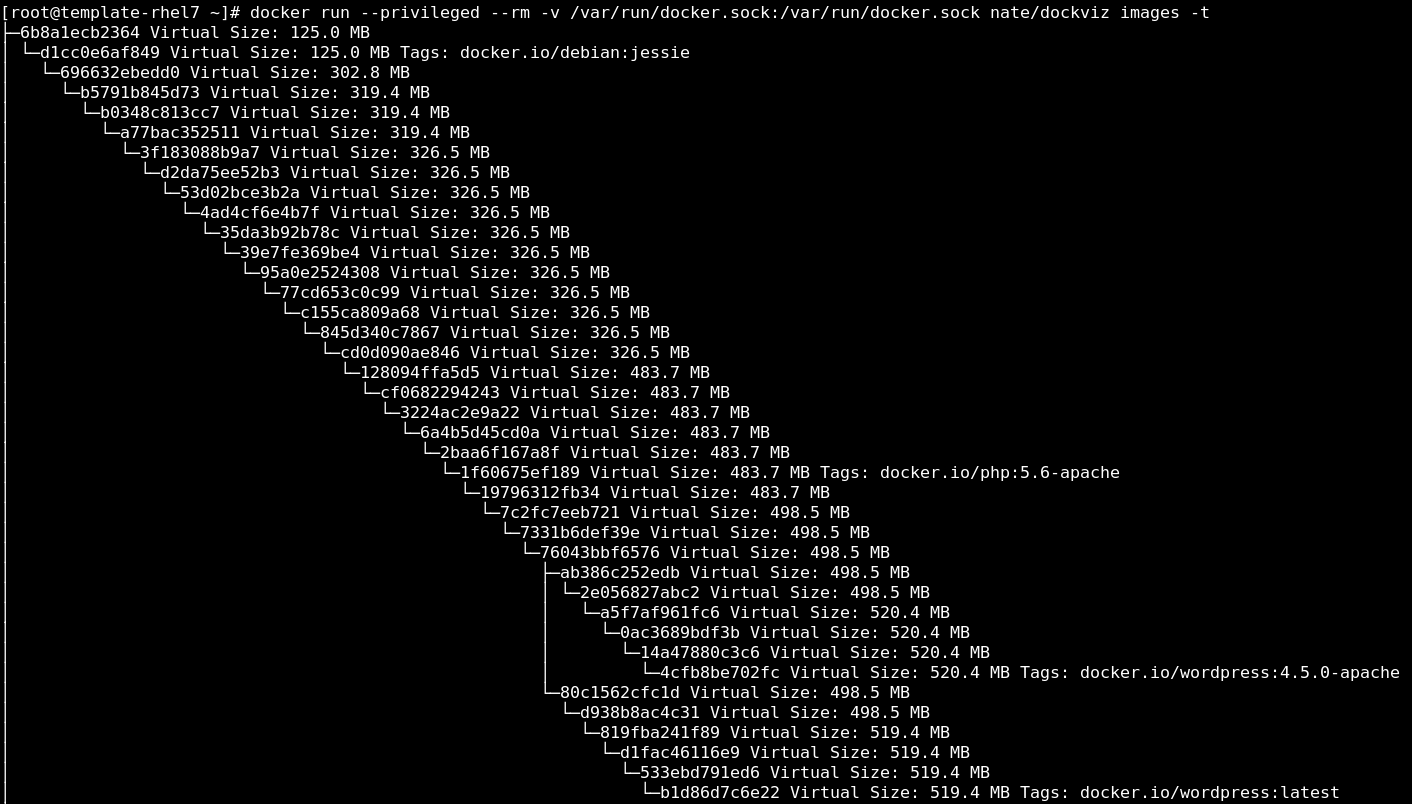 Notice the layers in the image above. Each of the layers that are tagged (debian:jesse, php:5.6, wordpress, etc.) essentially designate that a Dockerfile was used. Each of them used the image "above" them in the FROM line of the Dockerfile. There are so many layers because each line of a Dockerfile creates a new layer.
Notice the layers in the image above. Each of the layers that are tagged (debian:jesse, php:5.6, wordpress, etc.) essentially designate that a Dockerfile was used. Each of them used the image "above" them in the FROM line of the Dockerfile. There are so many layers because each line of a Dockerfile creates a new layer.
Red Hat Software Collections / OpenShift
Next, we are going to analyze the images that are delivered by the Red Hat Software Collections team. These are intermodal images which are built to run applications and build new images which will run applications. If you were to build wordpress on this image, you would have a standard three tier supply chain.
First, notice that this supply chain is built with Red Hat Enterprise Linux as the base image. This is a good starting point and this repository has much stronger provenance than pulling an arbitrary image from Docker Hub.
Next you might notice, there are not many layers. This is because Red Hat build tool squashes layers after it is done building the images. This leaves a very clean repository with a minimal amount of layers. This is a good image to start building off of if you need quick access to Ruby, Python, Node.js, or other languages and frameworks.
The downside of the Red Hat Software Collections images is that engineering decisions have already been made for you. Like images from Docker Hub, Red Hat cannot possibly build images that will meet every user’s needs.
 Very concise software supply chain. This is how Red Hat builds all of our official images. This makes it much easier to see the relation between layers.
Very concise software supply chain. This is how Red Hat builds all of our official images. This makes it much easier to see the relation between layers.
Custom Software Supply Chain
Next we are going to analyze a custom built software supply chain with strong provenance and the ability to make any customization necessary. Notice that the below supply chain has a clean chain of custody.
- Red Hat provides the base rhel7 image
- Your operations team customizes the corebuild layer
- Your middleware teams customize their own layers
- Your developers customize their own layers
This custom supply chain enforces clean separation of concerns and the ability to adopt containers without having to heavily modify your processes or organizational structure. Each of your current teams still retain control over the bits they care about.
Finally, this supply chain allows for very sophisticated and granular delegation of control - ops can patch anywhere in the stack and only modify the images that are necessary (e.g. modify all applications by patching the core build, or just PHP apps by patching the httpd-php layer), developers can make code changes without being worried about whether it will be patchable by operations. There are a lot of engineering advantages to this supply chain, which will be explained in the following sections.
 Notice, this is a very clean software supply chain. Each of the tags designate a component that can be reused in multiple applications. Each is created with a separate Dockerfile.
Notice, this is a very clean software supply chain. Each of the tags designate a component that can be reused in multiple applications. Each is created with a separate Dockerfile.
Building Your Own
So, how do you build a container supply chain that is right for you and your teams? These are still early days in terms of “container supply chain development”, but some patterns and best practices are already forming.
A New Set of Problems
Now that all of the teams can use a single tool to build and distribute software, it’s a panacea right? Well, not quite - Docker repositories are built in layers, and there are limitations in the tooling. Most importantly layers have a parent child relationship, and parent layers can’t just be swapped out if we want to change them. If the operations team rebuilds the corebuild in our example above, all of the dependent layers have to be rebuilt.
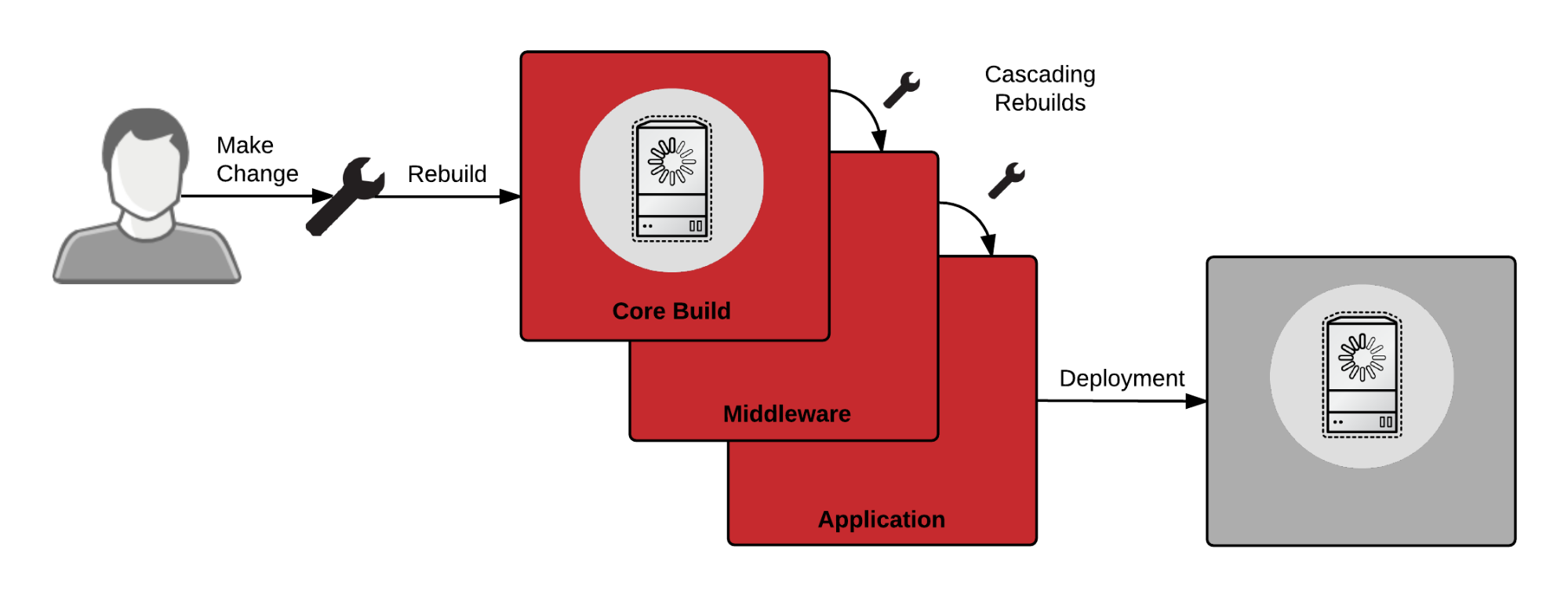 If operations changes the corebuild, middleware and development have to rebuild their images - and that’s not fun. Certain problems now become blurred:
If operations changes the corebuild, middleware and development have to rebuild their images - and that’s not fun. Certain problems now become blurred:
- Who controls each layer?
- Who controls what goes into production?
- Who is responsible for updates?
- Who is responsible for fixing regressions in performance, functionality, etc.?
Well, the good news is, I think I have some answers for you...
State of the World: Who Owns What
Here is a suggestion on how control of the supply chain can be broken down by team. This really doesn’t require a big change to organizational structure or processes. The biggest change is each team will have to adopt Dockerfiles for their builds. This will allow clear communication between teams.
Also, designing a supply chain so that each team uses a dockerfile as the currency for collaboration allows for cascading builds as mentioned above.
| Type | Example Image Name | Build vs. Buy | CI/CD Solution | Who Owns | Notes |
| Base Image | rhel7 | Buy | Maybe | Operations | Could use CI/CD to create custom images to verify base images on import. |
| Core Build | corebuild | Build | Build | Operations | Bad vendor support at this layer. Could use Jenkins, but going to be home grown. Test for compatibility, don’t break things up the stack. The industry still hasn’t fully fleshed out best practices around Ansible, Chef, Puppet and how they apply to a world with immutable infrastructure. |
| Middleware Build | httpd-php | Build | Build | Middleware Team | This could be applications server, PHP, Python, databases, or even message busses. Can be built with CI/CD tooling. Can be treated more like a core build or more like code, it depends. |
| Application Build | wordpress | Build | Buy | Development | Great vendor support, plenty of best practices around Jenkins and other build solutions for the “last mile” of the supply chain. |
| Deployment | - | Buy | Maybe | Development or Operations | Releases can be controlled by developers or operations depending how your organization and its level of comfort. |
Demo
For this blog entry, I have built a custom supply chain demo and modeled how cascading builds and deployments would work inside of OpenShift. There are two parts to this demo and I have placed them both in GitHub repositories so that you can clone them and use them as an example.
Build
First we have the software supply chain. This is where the layers are built and it’s done in a project controlled by operations, but this could be broken into separate projects as necessary. All of the engineering decisions - hardening, performance, Apache, PHP, FPM, MOTD, etc. - are done in these layered builds.
Going into all of the engineering decisions made is beyond the scope of this blog entry, but specific choices were made around Apache MPM, FPM, and running on port 8080 (...instead of a low port that requires escalated privileges) as the state of the art way to build a PHP application server. Package installs are only done in the first two layers (corebuild, httpd-php) because the last mile of application builds do not typically rely on RPMs. The last mile could even be built with Source to Image.
This particular wordpress image was also built to be completely compatible with the Wordpress image on Docker Hub. This makes it easy to deploy in any demo that configures the container with the exact same environment variables (WORDPRESS_DB_HOST, WORDPRESS_AUTH_SALT, etc.).
Deploy
Second, I have built the Wordpress demo in a separate project to demonstrate that the build and deploy can be completely separated. I chose wordpress because many people were already showing Kubernetes demos with the Wordpress image on DockerHub and I wanted to make it easy to demo with a different supply chain because many organization do not want to pull images from the Internet without a verifiable chain of custody.
This deployment uses an Image Change Trigger to detect that a new image is available in OpenShift and redeployed automatically, but this could be triggered manual if a team is not comfortable with that.
https://www.youtube.com/watch?v=LWwgKLwCHms
This demo will walk through an entire patching process showing how each team still retains control of their Dockeriles which can live in different GitHub repositories. The Corebuild is even located in a different project to show even better separation of concerns between teams.
Conclusion
There are a lot of challenges preventing organizations and teams from adopting containers. Patching and ownership are just two. A secure, manageable software supply chain with provenance and a known chain of custody can address these two particular challenges.
It’s pretty clear that a three tier supply chain is a good place to start for your own applications. It provides flexibility and allows current specialist teams to keep focusing on the engineering choices they need to make in the stack - operations can focus on the core build, middleware specialists can focus on their layer, and developers can focus on the last mile, their application.
This article has a lot of new concepts, so if you have any question or comments, please reach out below.
About the author
More like this
Why flexibility is non-negotiable in the Middle East’s AI transformation journey
The future of AI demands a hybrid foundation
Technically Speaking | Inside open source AI strategy
Collaboration In Product Security | Compiler
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds