FURTHER INVESTIGATIONS
In part 1, you saw the basics of uperf and how to deploy Ripsaw benchmark operator with default values. Now, A variety of arguments can be tweaked to customize the user's workload. Below are some such arguments.
MULTUS
Cluster Networking Interface (CNI) basically tells the cluster how pods should communicate with other pods. There are various CNIs supported by OpenShift. OpenShiftSDN is the default CNI; other third-party CNIs like Flannel SDN and Nuage SDN are also supported. This is where Multus comes into the picture. Like the earlier example, Multus is also a CNI, which enables attaching multiple network interfaces to pods. This makes Multus a "meta-plugin," a CNI plugin that can call multiple other CNI plugins. For this, a “NetworkAttachmentDefinition” is defined with the name as NAD.yaml.
This is applied to the my-ripsaw namespace and can be checked as follows
$ oc apply -f NAD.yaml -n my-ripsawnetworkattachmentdefinition.k8s.cni.cncf.io/macvlan-range-0 created
networkattachmentdefinition.k8s.cni.cncf.io/macvlan-range-1 created
$ oc get network-attachment-definitions -n my-ripsaw
NAME AGE
macvlan-range-0 39h
macvlan-range-1 39h
Now these “NetworkAttachmentDefinition” can be included in the uperf CR:
<snip>
workload:
cleanup: false
name: uperf
args:
serviceip: true
hostnetwork: false
pin: false
multus:
enabled: true
client: "macvlan-range-0"
server: "macvlan-range-1"
</snip>
When this CR is applied, you can check that the macvlan network is added to the client and server pods. The macvlan annotations applied to the server pod are shown below in green. The IP address of 11.10.1.68 is from the range provided in “NetworkAttachmentDefinition” for the server:
$ oc describe pod <uperf_server_pod_name>
Name: <uperf_server_pod_name>
Namespace: my-ripsaw
Priority: 0
Node: ip-10-0-138-102.us-west-2.compute.internal/10.0.138.102
Start Time: Sun, 01 Mar 2020 16:20:08 +0000
Labels: app=uperf-bench-server-0-2d679e17
type=uperf-bench-server-2d679e17
Annotations: k8s.v1.cni.cncf.io/networks: macvlan-range-1
k8s.v1.cni.cncf.io/networks-status:
[{
"name": "openshift-sdn",
"interface": "eth0",
"ips": [
"10.133.0.242"
],
"dns": {},
"default-route": [
"10.133.0.1"
]
},{
"name": "macvlan-range-1",
"interface": "net1",
"ips": [
"11.10.1.68"
],
"mac": "8a:9d:41:8d:2b:aa",
"dns": {}
}]
openshift.io/scc: restricted
Now you can check the multiple network interface inside the server or client pod:
$ oc rsh <uperf_server_pod_name$ oc rsh <uperf_server_pod_name>>
sh-4.2$ ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
3: eth0@if245: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 8951 qdisc noqueue state UP group default
link/ether 0a:58:0a:85:00:f0 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 10.133.0.242/22 brd 10.133.3.255 scope global eth0
valid_lft forever preferred_lft forever
inet6 fe80::4413:2fff:fecc:d394/64 scope link
valid_lft forever preferred_lft forever
4: net1@if2: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 9001 qdisc noqueue state UP group default
link/ether d6:ac:00:0d:01:52 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 11.10.1.68/16 brd 11.10.255.255 scope global net1
valid_lft forever preferred_lft forever
inet6 fe80::d4ac:ff:fe0d:152/64 scope link
valid_lft forever preferred_lft forever
MULTITHREADING
Here the number of threads being used have been tweaked in the CR:
nthrs:
- 4
Make sure to delete and “reapply” the CR:
$ kubectl delete -f ${RIPSAW}/resources/crds/ripsaw_v1alpha1_uperf_cr.yaml
$ kubectl apply -f ${RIPSAW}/resources/crds/ripsaw_v1alpha1_uperf_cr.yaml
Once the benchmarking has completed, you can view the logs once again. The differences between the two runs are shown below. The BLACK text is the original run, and the WHITE text is the new run:
<?xml version=1.0?> |
<?xml version=1.0?> |
The main differences are: (1) different profile name, and (2) different value for “nthreads.” Perfect!
The handshake “phases” debug output should not look any different, so no differences are expected there, as it is mostly doing the same basic testing and error checking.
When you look at the execution of the flow ops, you see major differences. For example:
</snip> |
</snip> |
Although not immediately obvious, the results from four different threads under transaction ID 1 are different from the results for 1 thread under transaction ID #1 in the original test run. (Remember, transaction IDs start with 0, not 1!)
You also see a difference in the “Strand Details” section. That is, you see four strands being used when “nthrs” is set to 4 rather than a single strand when “nthrs” is set to 1.
Next, you see major differences in the transaction and flowop tables:
Txn Count avg cpu max min
---------------------------------------------------------------------------
Txn0 1 853.41us 0.00ns 853.41us 853.41us
Txn1 52740 570.21us 0.00ns 148.0`9ms 30.09us
Txn2 1 13.15us 0.00ns 13.15us 13.15us
$ oc rsh <uperf_server_pod_name>
Flowop Count avg cpu max min
---------------------------------------------------------------------------
connect 1 852.71us 0.00ns 852.71us 852.71us
write 843824 35.61us 0.00ns 148.09ms 29.99us
disconnect 1 12.66us 0.00ns 12.66us 12.66us
Txn Count avg cpu max min
---------------------------------------------------------------------------
Txn0 4 462.02us 0.00ns 595.69us 361.99us
Txn1 93164 1.30ms 0.00ns 350.60ms 29.93us
Txn2 4 9.41us 0.00ns 13.69us 5.50us
Flowop Count avg cpu max min
---------------------------------------------------------------------------
connect 4 461.46us 0.00ns 595.01us 361.40us
write 1490589 80.95us 0.00ns 350.60ms 29.84us
disconnect 4 9.00us 0.00ns 13.26us 5.11us
Far more writes are being executed, and you see 4 separate connects/disconnects, one for each thread.
When you look at the netstat statistics, you also see some major differences. Namely, the rates for opkts and obits increase, while the rates for ipkts and ibts decrease. For example:
Netstat statistics for this run
-------------------------------------------------------------------------------
Nic opkts/s ipkts/s obits/s ibits/s
eth0 9503 11004 3.42Gb/s 5.81Mb/s
-------------------------------------------------------------------------------
Netstat statistics for this run
-------------------------------------------------------------------------------
Nic opkts/s ipkts/s obits/s ibits/s
eth0 14745 7480 6.03Gb/s 3.98Mb/s
-------------------------------------------------------------------------------
Finally, when you look at the run statistics, you will see that the bytes/sec and ops/sec nearly double, while latency nearly halves. So, you see a significant difference between using a single thread and multiple threads.
DIFFERENT PROTOCOLS
Protocols other than TCP can be used. For example, you could use UDP by removing the “tcp” value under “protos” in the uperf CR yaml and adding “udp” instead. However, using a different protocol does not alter the format of the output logs. That is, you still get “netstat statistics,” “run statistics,” etc., all in the same format. The most noticeable difference with UDP, though, is that the “ipkts/s” rate drops to zero (0) for the netstat results.
If desired, you can run two different protocols (“protos”) in the same test run. To do so, simply add a line for “udp” after the “tcp” line. That is, add the line highlighted in orange:
</snip>
protos:
- tcp
- udp
sizes:
- 16384
nthrs:
- 4
runtime: 30
Once the CR is reapplied and the benchmark has successfully completed, there will be a separator in the logs separating the TCP results from the UDP results.
OTHER PARAMETERS
Other parameters can be changed, too. For example, you can set the message size, the runtime, etc. More information on the effects of modifying these parameters can be found in reference 8 (the UPerf manual). The values used for these parameters are very specific to one’s project, so will not be covered here.
KIBANA AND ELASTICSEARCH
As mentioned in the CR yaml comments, you can store uperf benchmark results in Elasticsearch and view them in Kibana. Info on how to store results into Elasticsearch can be found here, under the “Storing Results into Elasticsearch” section: https://github.com/cloud-bulldozer/ripsaw/blob/master/docs/uperf.md
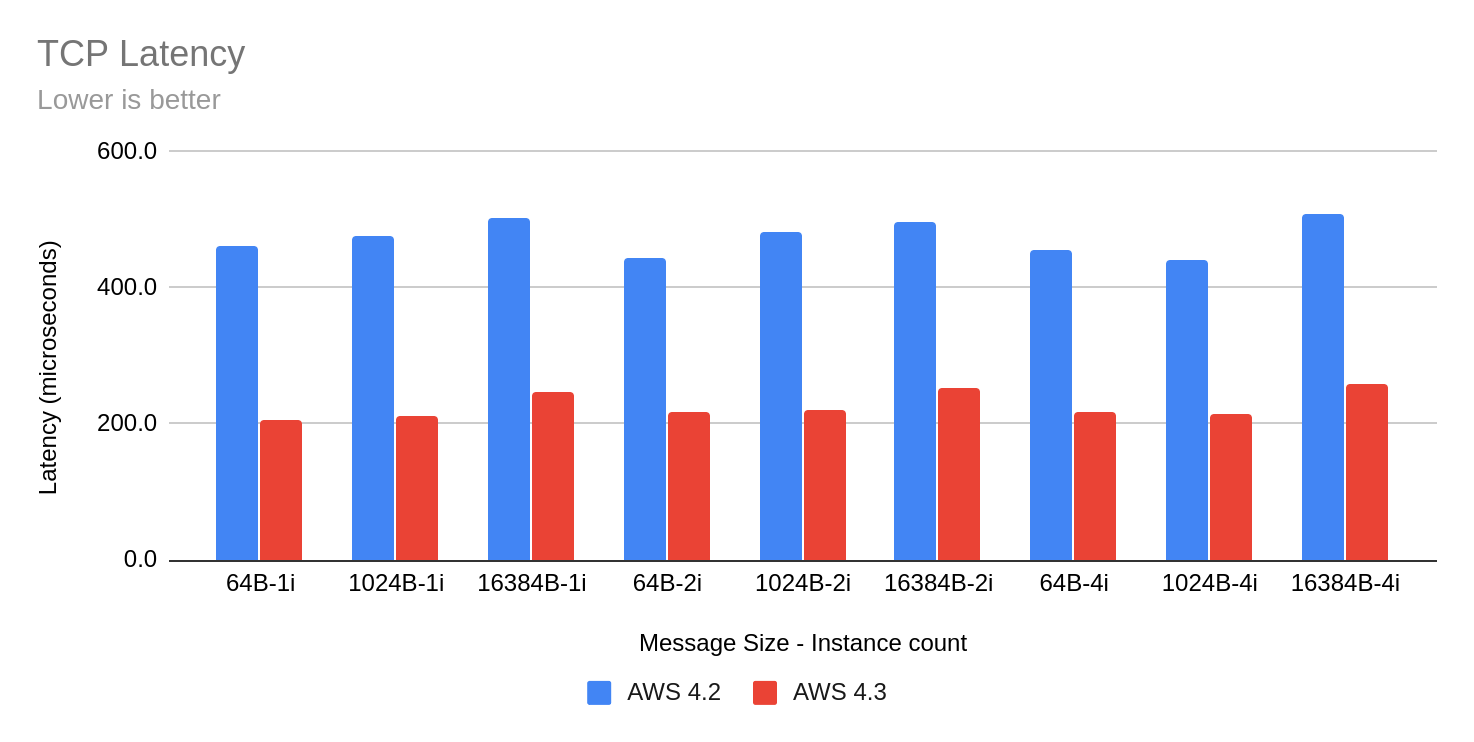
RESULTS - OCP 4.3 v OCP 4.2 on AWS
For Performance and Scale release testing, you usually compare the current release to the previous one. The graphs below show TCP Throughput and TCP Latency performance numbers for pod to pod using OpenShiftSDN as the overlay. The Instance count is the number of client-server pairs used and the number of threads is 1.

About the authors

More like this
AI in telco – the catalyst for scaling digital business
Introducing OpenShift Service Mesh 3.2 with Istio’s ambient mode
Crack the Cloud_Open | Command Line Heroes
Edge computing covered and diced | Technically Speaking
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds