
By Daniel Messer, Red Hat Storage
Red Hat Container-Native Storage 3.6, released today, reaches a new level of storage capabilities on the OpenShift Container Platform. Container-native storage can now be used for all the key infrastructure pieces of OpenShift: the registry, logging, and metrics services. The latter two services come courtesy of the new block storage implementation. Object storage is now also available directly to developers in the form of the well-known S3 API. Administrators will enjoy a more robust cns-deploy utility, support for online volume expansion, and more choice in deployment topologies in the OpenShift Advanced Installer. Last, but just as important, it now supports more concurrent workloads serving over 1,000 persistent volumes with just 3 nodes.
________________________________________
You know you must be doing something right when some of your users are looking to use your technology in different ways than expected. Initially, the idea of running GlusterFS alongside Kubernetes and OpenShift promised the ability to use a distributed storage system with a framework for distributed applications. They goes nicely together because both approaches are entirely based on scale-out software, hence independent of the underlying platform, and they are driven by a declarative API-driven design. On the GlusterFS side, that API is available in the form of an additional software daemon, called heketi. Things soon took a new direction when the first experiments of running the GlusterFS/heketi combination as an OpenShift workload were conducted.
A lot of engineering cycles later, the idea of hacking GlusterFS onto OpenShift has emerged to a fully supported product offering: container-native storage. Today, we are happy to announce container-native storage 3.6.
For the impatient: In essence, we have taken container-native storage from being an optional supplement in OpenShift to being a storage solution that now serves file, block, and object storage to applications on top of OpenShift and to the entire OpenShift internal infrastructure, as well.
For the curious reader, let's go see how we did that....
Increase density
The first thing we had to do was ensure that container-native storage was a robust, scalable, long-term solution for the different possible OpenShift cluster sizes. When we launched container-native storage with OpenShift 3.2 last summer, the container images were based on Red Hat Gluster Storage 3.1.3 and, on average, each brick process on a GlusterFS host/pod consumed about 300 MB of RAM.
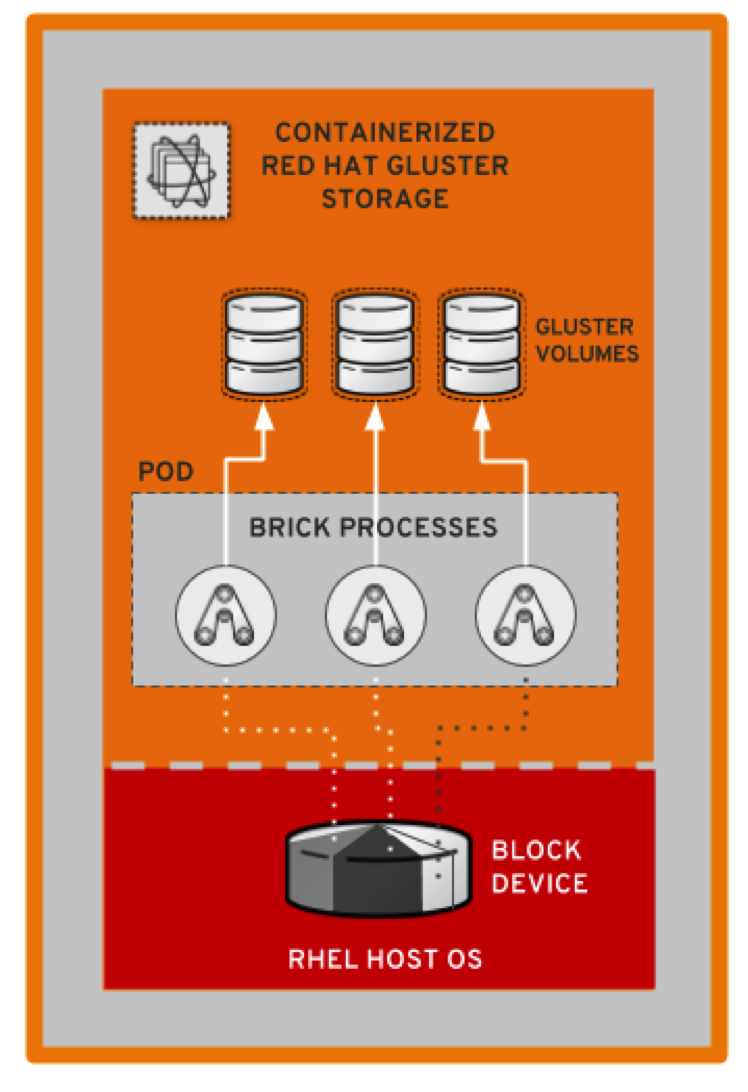
That may not sound like much, but you have to be aware that every PersistentVolume served by container-native storage results in a GlusterFS volume being created. Bricks are local directories on GlusterFS pods that make up volumes. The consistency of volumes across all its bricks (by default, 3 in container-native storage) is handled by the glusterfsd process, which is what consumes the memory.
In older releases of Red Hat Gluster Storage, there was one such process per brick on each host. It’s easy to see that with potentially hundreds of application pods in OpenShift requiring their own PersistentVolumes, the resulting number of brick processes in each GlusterFS pod will easily consume gigabytes of RAM and would create a significant effort to coordinate in each pod.
That many processes in a pod are an anti-pattern for Kubernetes and, even if we would have broken out those in separate containers, the memory overhead would still be huge.
Fortunately, Red Hat Gluster Storage 3.3 came to the rescue. Released just a little over 2 weeks ago, it introduced a new feature called brick-multiplexing. It’s easier to depict how this feature changes the structure of a GlusterFS pod in a diagram than a lengthy explanation:
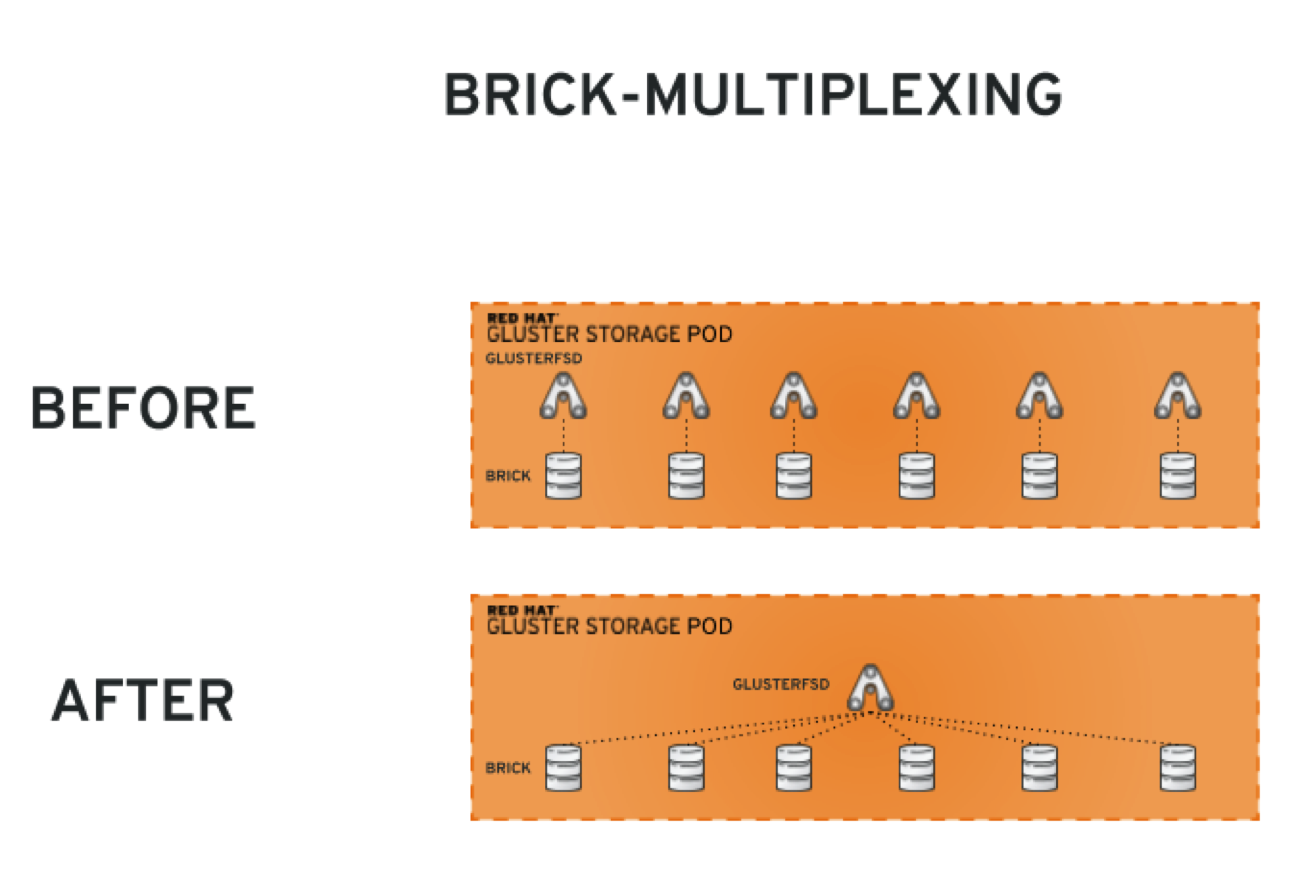
With brick-multiplexing, only one glusterfsd process is governing the bricks such that the amount of memory consumption of GlusterFS pods is drastically reduced and the scalability is significantly improved.
By introducing brick-multiplexing in version 3.6, we are able to support over 1,000 PersistentVolumes in a single container-native storage cluster. The amount of memory consumed increases linearly, so that 32GB of RAM are only needed at the high end of that. The rule of thumb is roughly 30-35 MB RAM per volume on each of the participating GlusterFS pods.
Container-native storage can probably support an even greater number of volumes, and we hope to confirm that soon. Until then, you always have the option to either run more GlusterFS pods in your OpenShift cluster or deploy a second container-native storage cluster, governed by the same Heketi API service.
Optimized storage for logging/metrics
File storage is what containers on OpenShift (and in general) deal with today. It’s a ubiquitous, well-understood concept. There are also proposals for native access to block devices in pods, but they are still in design or planning phases.
That is—at least for now—storage (including block) in Kubernetes and OpenShift always ends up being a mounted file system on the host running the pod, which is then bind-mounted to the target container’s file system namespace. Block storage provisioners in OpenShift eventually format the device with XFS too, before handing it over to the container.
GlusterFS is a distributed, networked file system which, in contrast to local filesystems like XFS, allows shared access from multiple hosts and stores the data in the backend distributed across multiple nodes. This big advantage does not come without cost, however: Some type of operations that are fast and cheap on a local file system are quite expensive in a distributed file system.
For some workloads (e.g., OpenShift Logging and Metrics), this can be a show-stopper. To properly support those, we designed something that might seem counter-intuitive at first: gluster-block. Take a look at the implementation scheme below:
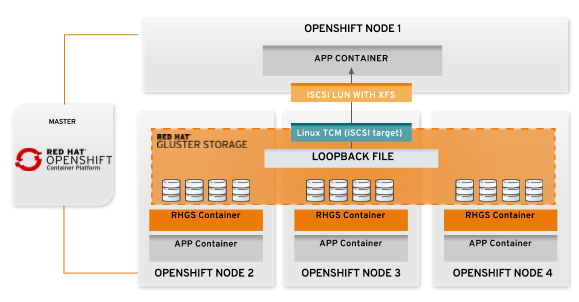
Yes, you see that right: We are using TCM (the Linux kernel's iSCSI stack, also called LIO) managed by targetcli to create iSCSI LUNs from files on a GlusterFS volume and present those as block devices to pods. The TCM stack allows local storage of a Linux system to be made available on the network via the iSCSI protocol. In our specific case, the local storage is a large raw file on a GlusterFS volume. On the client side, the iSCSI block device will be formatted with XFS and then bind-mounted to the target container's file system namespace.
But why go through all the trouble? In distributed file systems—and here GlusterFS is no exception—metadata-intensive operations like file create, file open, or extended attribute updates are particularly expensive and slow compared to a local file system. In particular, indexing solutions likes ElasticSearch (part of OpenShift Logging) and scale-out NoSQL databases like Cassandra (part of OpenShift Metrics) generate such workloads. But also other database software might make heavy use of locking and byte-range locking, which are costly compared to simple read and writes.
In order to qualify OpenShift Metrics and Logging Services to run well on a container-native storage backend, a significant speed up was needed for a lot of special file system operations like these.
You can probably guess what we were thinking: In software, many problems can be solved by adding an additional layer of indirection.
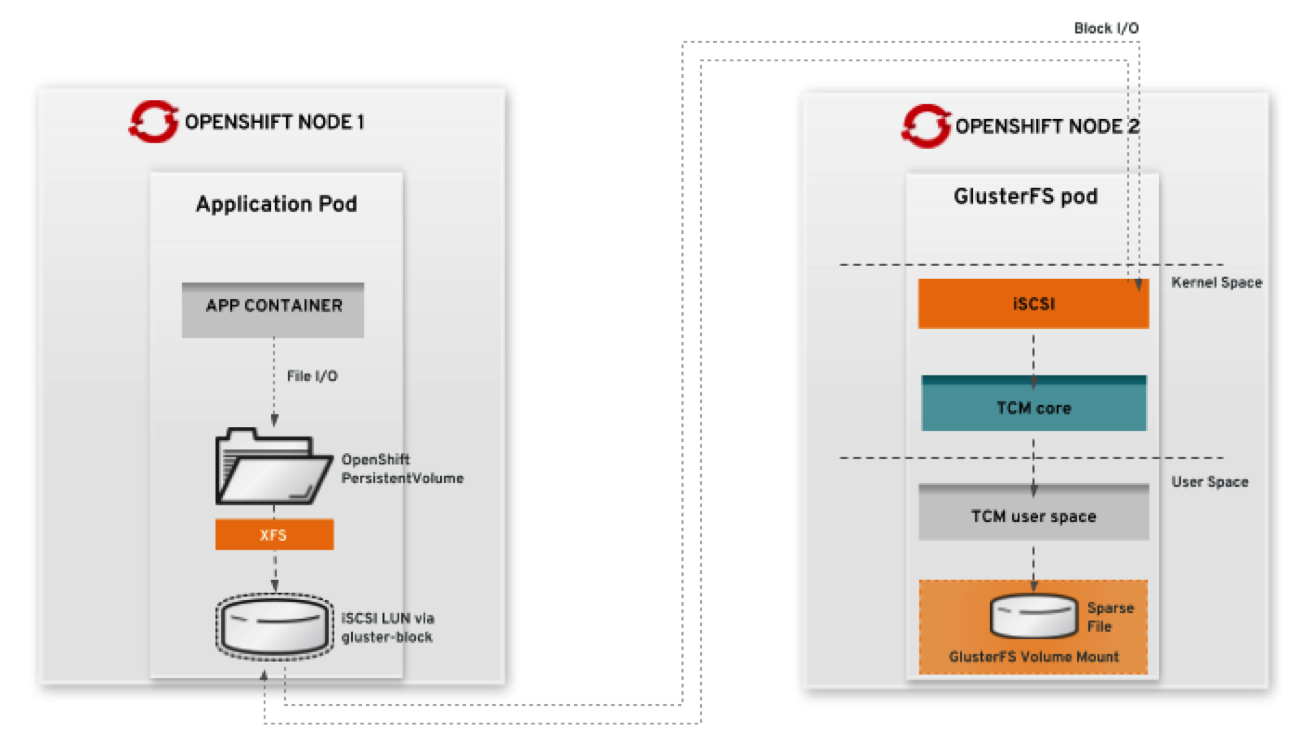
The indirection in accessing data on GlusterFS via iSCSI instead of a normal GlusterFS mount converts otherwise expensive file system operations to a single stream of continuous reads and writes to a single raw file on GlusterFS. The TCM stack delivers this IO stream over the network via iSCSI. On the receiving end, the file in GlusterFS backing the iSCSI LUN is accessed via libgfapi, a userspace library to access files in GlusterFS without the need to mount a volume.
The clients, in our case containers in pods on OpenShift, still write to an XFS file system the iSCSI LUN is formatted with. As a result, simple client-level read and write requests remain virtually as fast as accessing the file directly on GlusterFS, but also all the other file system operations are converted into much faster reads and writes to the file backing the block volume because they are not distributed. From the perspective of GlusterFS, it’s a constant stream of basic read and write requests, which GlusterFS is efficient at. Of course, this comes with a trade-off: gluster-block is not shared storage.
Container-Native Storage version 3.6 now provides backend storage for OpenShift Logging and OpenShift Metrics with gluster-block. For the moment, the use of gluster-block in production is only supported for OpenShift Logging and Metrics services, but use of gluster-block beyond that is under qualification, and support is expected to be extended soon.
The Logging and Metrics services have strict performance and latency requirements and are important for any OpenShift cluster in production. They provide vital information and debugging capabilities for administrators. By design, they are scale-out services, because their storage backend (ElasticSearch for Logging, Cassandra for Metrics) supports a shared-nothing approach. However, in production you do not want additional shards of ElasticSearch and Cassandra run side-by-side with your application pods. That’s why there is a concept of infrastructure nodes in OpenShift that do not run business applications but are dedicated to OpenShift infrastructure components like these. Typically, these kind of servers only have storage locally available, which is limited in capacity and performance. Thus, it might quickly become insufficient to store the logs and metrics of hundred of pods. With container-native storage, you now have a scalable, robust, and long-term storage solution for logging and metrics that utilizes the entire cluster's storage capacity.
Support a scale-out registry
There is one additional component in OpenShift that’s crucial for operations: the container image registry. This is where all the resulting images from source-to-image builds will be pushed to and where developers can upload their custom images. If it’s unavailable, those operations will fail, and users will be unable to launch new or update existing applications.
The default configuration for the OpenShift registry is to use `emptyDir` storage, that is, a local file system on the container host that depends on the registry pod's lifetime. In this setup, the registry, of course, cannot be scaled out, updated, or restarted on another host.
Fortunately, as of version 3.5, container-native storage allows for a scale-out registry using shared storage on a PersistentVolume served by GlusterFS. This has several advantages:
- No external storage is required, like NFS, which can cause problems with metadata consistency with a busy registry.
- There is no dependency on provider storage (e.g., AWS S3 being unavailable in a VMware environment) for shared data access.
- The registry can now be scaled out, ideally across all infra nodes.
- The registry storage backend can grow dynamically with the platform.
The beauty of this is that it can be installed like this right away. Like we’ve already covered during the announcement of OpenShift Container Platform 3.6 earlier this year, the OpenShift Advanced Installer now supports deploying container-native storage and the registry on container-native storage out of the box. See this video here for details.
All you have to do since OpenShift Container Platform 3.6 is add a few lines to your Ansible inventory file.
To deploy an OpenShift registry backed by container-native storage, first add the following variable definition in the [OSEv3:vars] section:
openshift_hosted_registry_storage_kind=glusterfsAnd then add a new host group defining the container-native storage nodes to the inventory, for example:
[glusterfs_registry] infra-1.lab glusterfs_devices='[ "/dev/sdd" ]' infra-2.lab glusterfs_devices='[ "/dev/sdd" ]' infra-3.lab glusterfs_devices='[ "/dev/sdd" ]'
This is enough to tell the OpenShift Advanced Installer that it should create a basic 3-node container-native storage cluster, in this case on the infrastructure nodes, using the supplied devices to create bricks. From this cluster a PersistentVolume will be created and supplied to the registry DeploymentConfig.
That way the registry will be launched with shared storage, provided by container-native storage, and scaled to 3 instances across the infrastructure nodes. You get a highly available and robust registry out of the box with no additional configuration needed.
S3 object storage for applications
In addition to providing block and file storage services, Container-Native Storage 3.6 now provides an S3 object storage interface as a TechPreview. Application developers have a ready-to-use REST API at hand to provide object storage to workloads on OpenShift, just a HTTP PUT or GET request away.
Object storage in Red Hat Container-Native Storage 3.6 provides a simple yet scalable storage layer for distributed applications that were previously tied to specific cloud provider S3 object storage. These application now run with little or no modification on OpenShift.
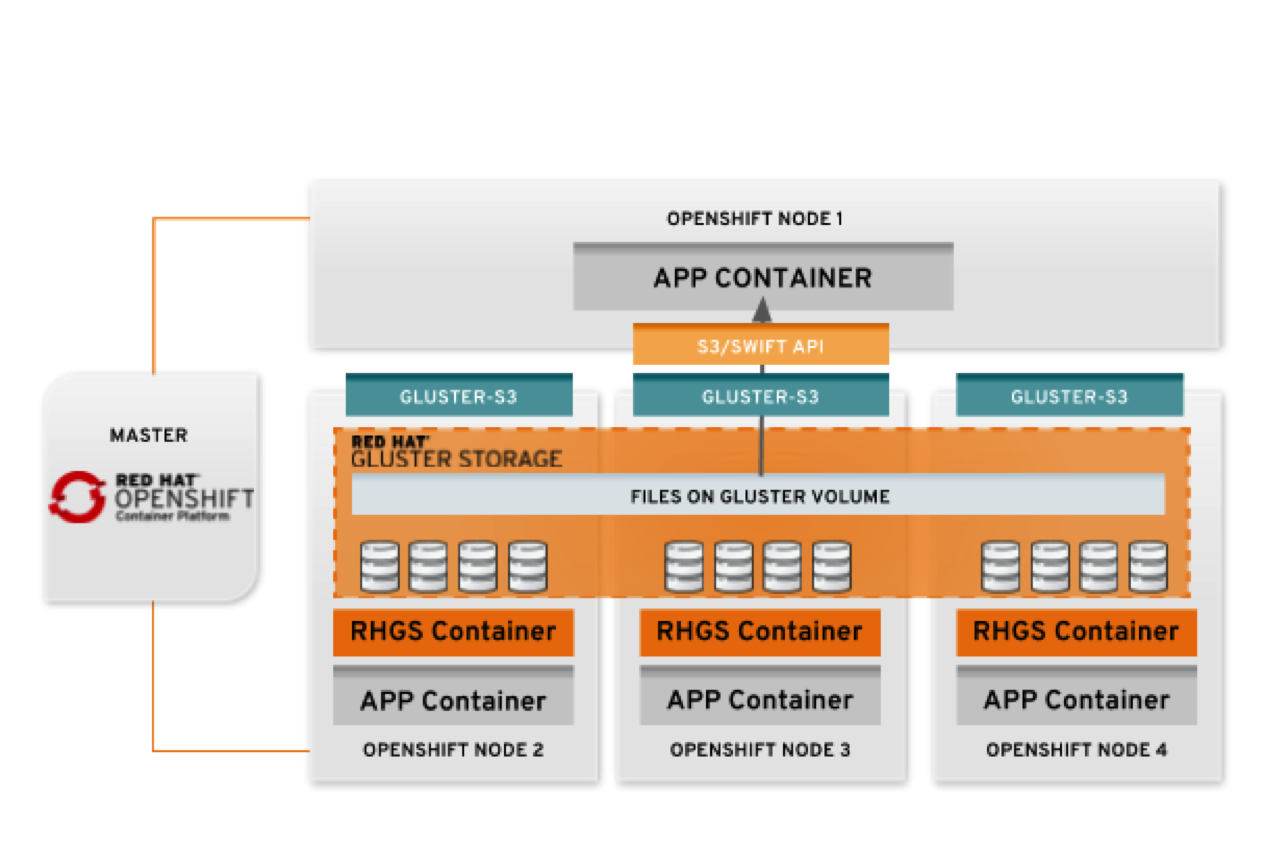 In this implementation, a gluster-s3 service is deployed as a pod in your OpenShift cluster, and an OpenShift Route is generated for it. The Route’s URL is provided to applications as their S3 endpoint. The service receives the S3 requests and translates those to file system operations on GlusterFS volumes. The S3 buckets and objects are stored as directories and files on that volume, respectively.
In this implementation, a gluster-s3 service is deployed as a pod in your OpenShift cluster, and an OpenShift Route is generated for it. The Route’s URL is provided to applications as their S3 endpoint. The service receives the S3 requests and translates those to file system operations on GlusterFS volumes. The S3 buckets and objects are stored as directories and files on that volume, respectively.
For now, this service can be deployed with the cns-deploy utility. There are some new command switches available for this purpose:
cns-deploy topology.json --namespace gluster-storage --log-file=cns-deploy.log --object-account dmesser --object-user dmesser --object-password redhatThe new parameters allow you to specify a name for the S3 account (object-account, an aggregate of multiple S3 buckets, one per CNS cluster), a named user (object-user), and the authentication password for that user in that account (object-password). Once all of these 3 switches are presented, cns-deploy will create the glusterfs-s3 infrastructure.
Support for doing this with the OpenShift Advanced Installer is expected to follow soon. The design foresees exactly one S3 domain/account per CNS cluster, although multiple CNS clusters can be deployed easily.
Improvements for deployment and operations
Besides a whole bunch of new features, we've also introduced improvements in usability to make the container-native storage experience better.
In Container-Native Storage 3.6, the cns-deploy tool has been improved in a number of ways. It is now more idempotent, allowing the administrator to run the installer multiple times without having to start from scratch. There will still be error scenarios that may require manual intervention, but it should be much easier to recover from such errors. It will also deploy the required resources to use gluster-block and gluster-s3. Combined with the idempotency improvements, administrators will be able to run cns-deploy to deploy those features into an environment that's already running container-native storage.
Container Native Storage 3.6 also provides improved integration with container-ready storage. All of our new features will work just as well on container-ready storage as container-native storage. In addition, we have introduced support for a configuration we're calling Container-Ready Storage without Heketi. heketi is the volume management API service for GlusterFS. In this configuration, container-ready storage runs with the usual Red Hat Gluster Storage nodes outside the OpenShift cluster, but heketi resides as a pod within OpenShift. This has the advantage of making the heketi service highly available rather than residing on a single machine. For new deployments, the cns-deploy can be used to initialize a container-ready storage cluster in this configuration.
Another common scenario that is likely to occur over time, even with the short-lived nature of some workloads, is PersistentVolumes filling to capacity. This can happen when a user under-estimates the required capacity for a workload or the pod simply runs way longer than expected. In any case, heketi now allows for online volume expansion.
To take advantage of this, simply use the heketi-client on the CLI to expand the size of any given volume:
heketi-cli volume expand --volume=0e8a8adc936cd40c2df3698b2f06bba9 --expand-size=2In the background, heketi changes the GlusterFS volume layout from a 3-way replicated to distributed-replicated. See below for a comparison from GlusterFS perspective.
Before volume expansion:
sh-4.2# gluster vol info vol_0e8a8adc936cd40c2df3698b2f06bba9 Volume Name: vol_0e8a8adc936cd40c2df3698b2f06bba9 Type: Replicate Volume ID: 841bd097-659b-4b5d-b3ec-56bb8cc51c2f Status: Started Snapshot Count: 0 Number of Bricks: 1 x 3 = 3 Transport-type: tcp Bricks: Brick1: 10.20.5.232:/var/lib/heketi/mounts/vg_c05319c8a95eaa083adbedb7d43913fa/brick_4bf9ae183dacceccf4bf525186850bdd/brick Brick2: 10.20.6.239:/var/lib/heketi/mounts/vg_bd7fbf9053d6340771f7b75ce2872339/brick_e1175aaaa8596aedc18bf8c56b42fe8d/brick Brick3: 10.20.4.184:/var/lib/heketi/mounts/vg_0797a1d458309eec3e5e818a9b87f6c6/brick_2b5255cc2c0297e4e34eb6f1b4319fb9/brick Options Reconfigured: transport.address-family: inet nfs.disable: on cluster.brick-multiplex: on
After volume expansion:
sh-4.2# gluster vol info vol_0e8a8adc936cd40c2df3698b2f06bba9 Volume Name: vol_0e8a8adc936cd40c2df3698b2f06bba9 Type: Distributed-Replicate Volume ID: 841bd097-659b-4b5d-b3ec-56bb8cc51c2f Status: Started Snapshot Count: 0 Number of Bricks: 2 x 3 = 6 Transport-type: tcp Bricks: Brick1: 10.20.5.232:/var/lib/heketi/mounts/vg_c05319c8a95eaa083adbedb7d43913fa/brick_4bf9ae183dacceccf4bf525186850bdd/brick Brick2: 10.20.6.239:/var/lib/heketi/mounts/vg_bd7fbf9053d6340771f7b75ce2872339/brick_e1175aaaa8596aedc18bf8c56b42fe8d/brick Brick3: 10.20.4.184:/var/lib/heketi/mounts/vg_0797a1d458309eec3e5e818a9b87f6c6/brick_2b5255cc2c0297e4e34eb6f1b4319fb9/brick Brick4: 10.20.6.239:/var/lib/heketi/mounts/vg_bd7fbf9053d6340771f7b75ce2872339/brick_c48d4ea4b43635f62c464ddf0259d733/brick Brick5: 10.20.4.184:/var/lib/heketi/mounts/vg_0797a1d458309eec3e5e818a9b87f6c6/brick_121fbc266c905311d8a8810f221fbdca/brick Brick6: 10.20.5.232:/var/lib/heketi/mounts/vg_c05319c8a95eaa083adbedb7d43913fa/brick_5f208c680444b4820f53c923aa079614/brick Options Reconfigured: transport.address-family: inet nfs.disable: on cluster.brick-multiplex: on
Finally, with Container-Native Storage 3.6, we have expanded the amount of technical documentation available. We provide more examples of things both new and pre-existing that you can do with container-native storage, as well as detailed upgrade procedures from a variety of configurations to make sure you can get the latest set of features.
Verdict
The storage play for containers is an exciting space at the moment. There are many options available for customers, and Red Hat container-native storage is unique in the way it runs natively on OpenShift and provides scalable shared file, block, and object storage to business applications and container platform infrastructure.
About the author
More like this
No time to lose: Why post-quantum security for financial services must start now
Architecting for maintainability: Lessons from a global multicluster platform blueprint
Container Roundup | Compiler
Untangling Networks | Compiler
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds