
This post was co-authored by Keith McClellan, Director, Partner Solutions Engineer at Cockroach Labs.
Introduction
In this series of articles, we present approaches to deploy stateful workloads on OpenShift clusters across geographical regions with the goal of achieving zero-downtime disaster recovery performance when a region is lost.
In part one of this series, we looked at steps needed to prepare the clusters to house stateful workloads. In this article, we will describe how to deploy CockroachDB, a cloud-native distributed SQL database. In addition, we will also execute performance tests to validate the deployment, and we test a DR scenario to verify that we can actually achieve a zero downtime SLA in case of disaster.
CockroachDB’s Architecture
CockroachDB was designed from the ground up to act as a shared-nothing, distributed SQL database. It automates data replication, manages quorum across replicas, and guarantees full ACID compliance with serializable isolation between transactions.
CockroachDB’s architecture enables guaranteeing an RPO (recovery point objective) of zero (0) seconds (no data loss) and an RTO (recovery time objective) of less than nine (<9) seconds for supported failure mode. That nine seconds is the time it takes the cluster to sense the loss of a lead replica for any portion of the data and elect a new leader. By distributing the authority to act on data across the nodes of the cluster, architects and engineers can design a system based on what scenarios they need to survive. For example, the architecture outlined here can survive arbitrary node failure or the failure of an entire site and still meet these RTO and RPO objectives. This tool can be used to determine what the minimum infrastructure requirement is to meet certain survivability goals.
Step 1: Setup
In the following scenario, the architecture we are testing is designed to survive an arbitrary node, availability zone, or datacenter failure without loss of data and without requiring manual recovery.
The architecture for CockroachDB (CRDB) is similar to that of the previously deployed HashiCorp Vault: a nine-node cluster with three nodes for each of the three managed OpenShift clusters. This should not be a surprise as CockroachDB also uses Raft as its fundamental state synchronization protocol.
The resulting end state architecture is depicted below:
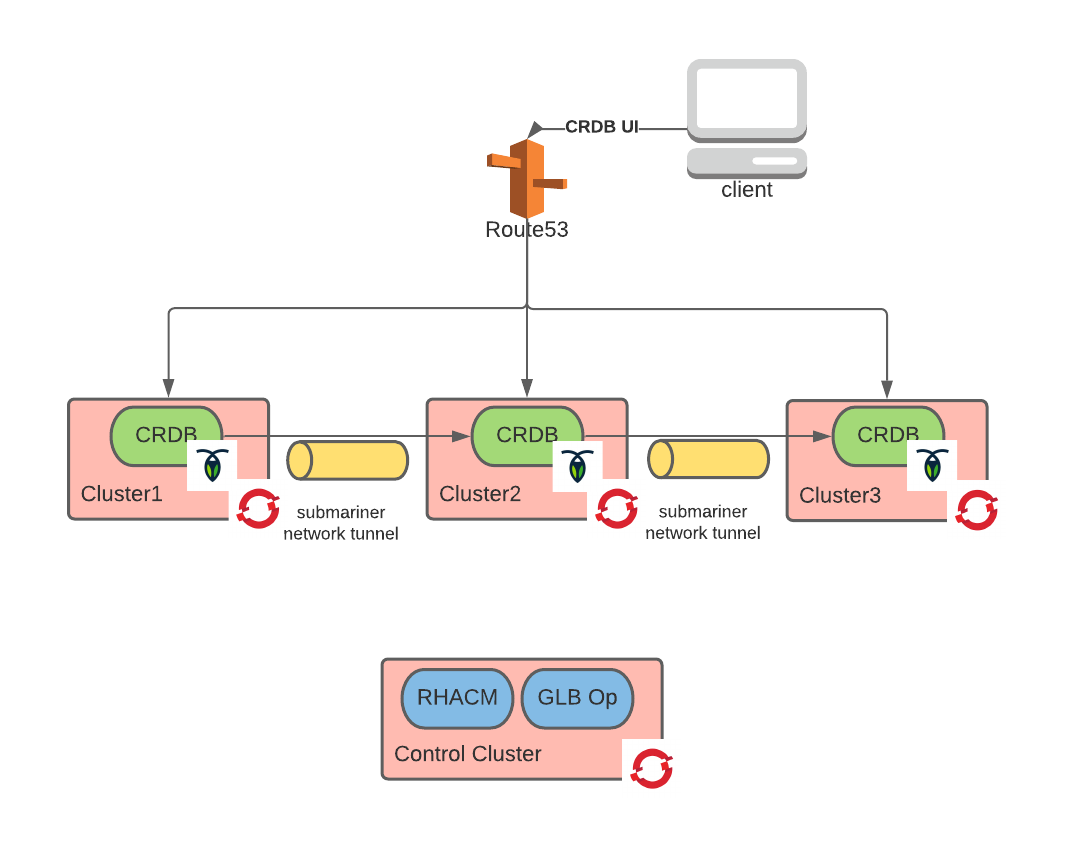
As illustrated previously, a CockroachDB cluster is stretched across three OpenShift clusters deployed in separate AWS regions. Route53 acts as global load balancer (mainly for the CockroachDB UI) and is configured by the global-load-balancer-operator. The three OpenShift clusters on which CockroachDB runs have been previously deployed via Red Hat Advanced Cluster Management (RHACM).
Finally, the CRDB instance forms a single database cluster, thanks to the direct peer-to-peer connectivity provided by the network tunnel implemented with Submariner. A full overview of the global-load-balancer-operator, RHACM and Submariner can be found in the previous article.
A more detailed depiction of the nine-node CRDB cluster is shown below:
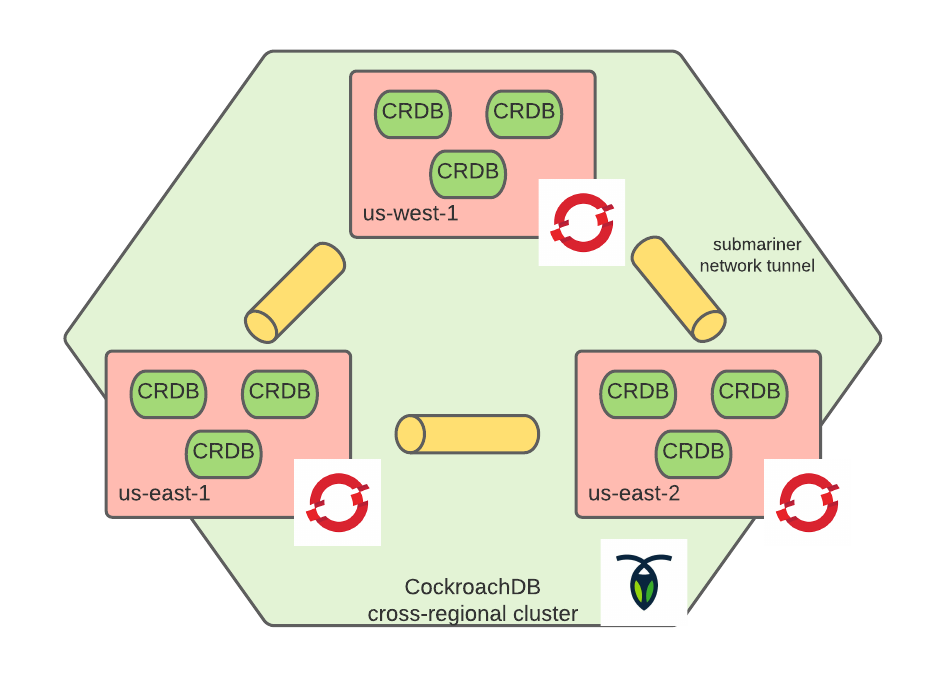
As illustrated above, each region has three instances of CockroachDB to allow for this cluster to survive not only an arbitrary node failure, but an entire site failure. Instances of the database communicate with one another in a mesh configuration by way of the Submariner network tunnel.
All communication is secured with mutual TLS (mTLS)with certificates automatically provisioned by the previously deployed cert-manager.
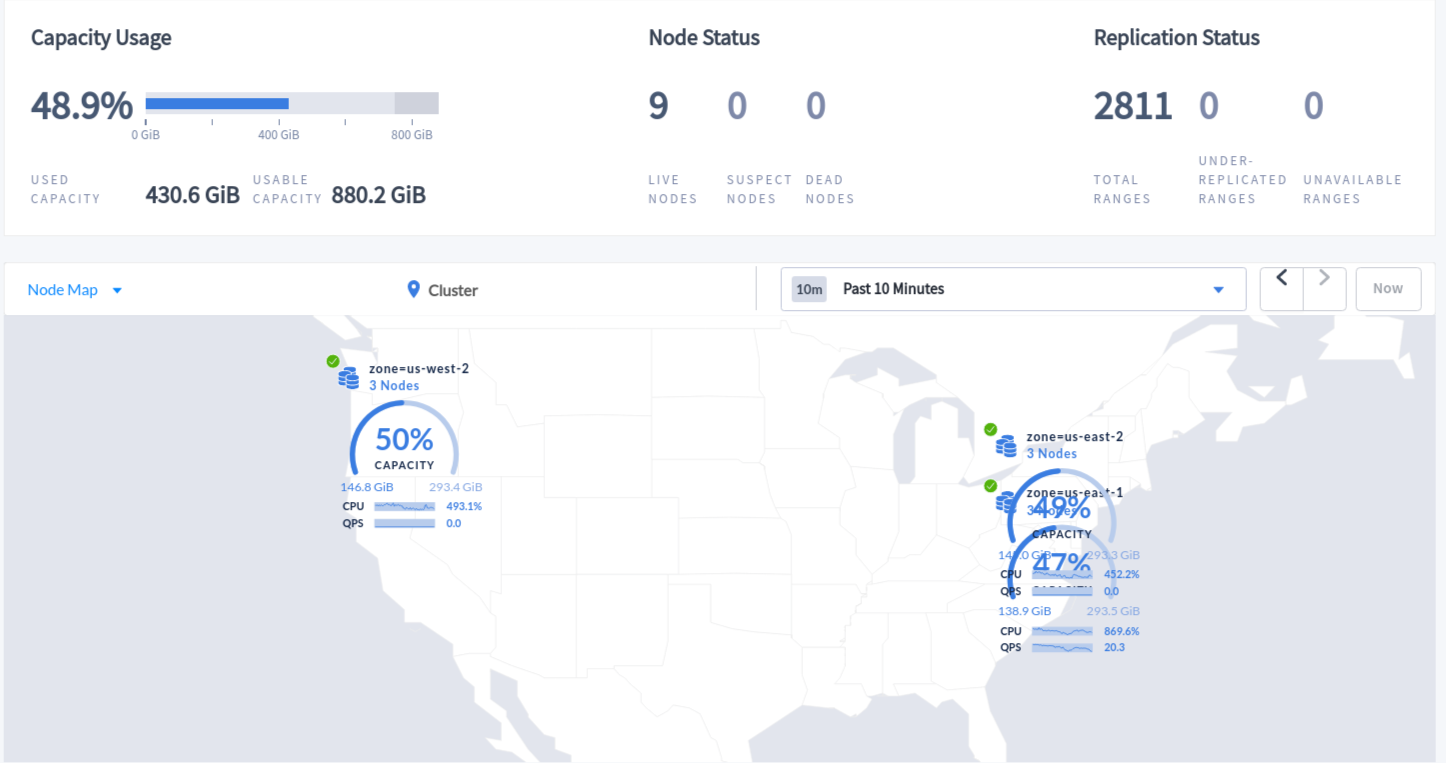
A Helm chart that was derived from the official CockroachDB Helm chart is used to deploy the cluster. By following these steps, you can deploy and initialize the CockroachDB cluster. After a successful deployment, you should be able to access the user interface to verify the health of the cluster.
CockroachDB also offers a view in which one can verify the latency between the nodes:
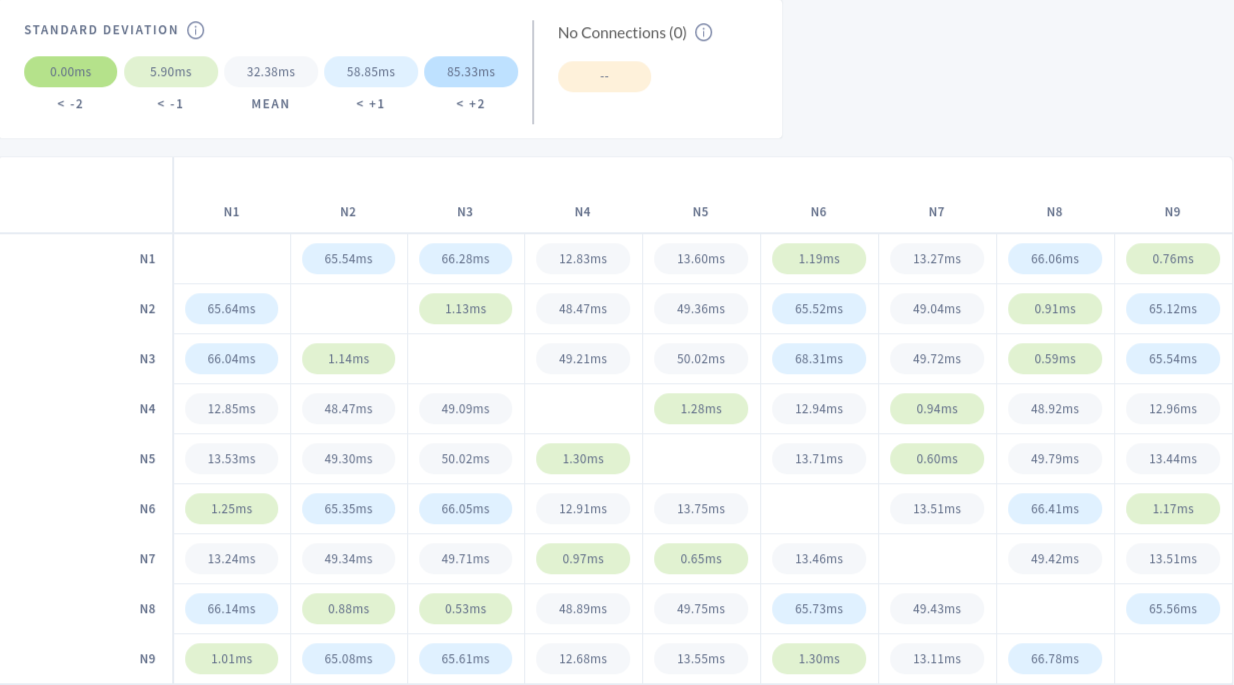
In the table above, cells with the light blue background identify two nodes between which the latency is higher than the average. This can be expected as one node is on the east coast of the United States and the other on the west coast. As described in the AWS region latency matrix, the observed metrics line up with the baseline indicating that the network tunnel that we established between the cluster is not introducing a significant amount of latency.
Step 2: Load and Stability Test
To validate the stability and performance of the CockroachDB cluster deployment described above, we ran the TPC-C benchmark. The TPC-C benchmark is a standard database performance test aimed at simulating an Online Transaction Processing (OLTP) environment of a fictional product/service company with a database in which orders are processed.
This test is designed to measure database software efficiency. It does so by simulating several fictional warehouse databases and end users (10 per warehouse) inputting a mix of OLTP transactions. Because user thinking time is incorporated by the test, and given a number of warehouses, there is a theoretical upper bound to the number of transactions per second achievable.
We ran the TPC-C 1000 test with three clients, generating load in parallel for one hour. The diagram below depicts the architecture of the test scenario:

With this version of the test, the aggregated clients generate load on one thousand warehouses (companies) by simulating approximately 10 employees for each warehouse inputting orders with a mix of different transaction types (writes, reads, complex joins, etc.). Running the test for 60 minutes ensures that both outlier figures average out, and that the system can sustain heavy load for a long period of time without stability issues.
In terms of the hardware used for this test, we ran each CockroachDB instance on a c5d.4xlarge (a medium-sized compute-optimized VM) AWS instance type. These OpenShift nodes were fully dedicated to CockroachDB and no other workloads were running on them. Also, a m5n.xlarge (a network-optimized small-sized VM) instance type to the Submariner gateway. Finally, AWS io1 volumes with 5000 guaranteed IOPS were used for the CockroachDB database volumes.
The steps to replicate this test can be found here.
The following are the results of one of the runs:
Client1
_elapsed_______tpmC____efc__avg(ms)__p50(ms)__p90(ms)__p95(ms)__p99(ms)_pMax(ms)
3600.0s 4138.0 32.2% 268.7 130.0 704.6 805.3 1040.2 3087.0
Client 2
_elapsed_______tpmC____efc__avg(ms)__p50(ms)__p90(ms)__p95(ms)__p99(ms)_pMax(ms)
3600.0s 4151.3 32.3% 218.4 130.0 536.9 671.1 838.9 3221.2
Client 3
_elapsed_______tpmC____efc__avg(ms)__p50(ms)__p90(ms)__p95(ms)__p99(ms)_pMax(ms)
3600.0s 4141.1 32.2% 337.7 234.9 704.6 771.8 906.0 2818.6
The tpmC column stands for the number “new order” transactions per minute (while the rest of the transaction mix is also being executed). These are “business transactions” that may incorporate a number of different database transactions. In this test, summing the clients, we achieved 12430 aggregated tpmC (12860 tpmC is the theoretical limit for 1000 warehouses). Because each client was running a third of the test, the efficiency ratio can be summed across the client. Doing so yields an efficiency ratio of 96.7%. Anything above 86% is considered a pass.
The other columns report the average latency for the transaction by a few percentiles. While examining this number, keep in mind that these are aggregated latency for different types of business transactions that may vary from a combination of very fast writes to very complex and long to execute queries.
Step 3: Disaster Recovery Test
If you recall, we set off on this journey with the objective of creating a system with nearly zero RTO and RPO during a disaster, or in other words, a zero-downtime and always-consistent system even during a disaster. To validate that we have actually created such a system, we ran a disaster recovery test.
To simulate a disaster, we isolated from the network one of the AWS VPCs in which the OpenShift clusters run. This partitioned the CockroachDB database. The expectation is that the partition with the quorum keeps functioning normally and that the partition without the quorum simply stops accepting transactions. Also, we expect that when the VPC connectivity is restored, the CockroachDB instances that were isolated rejoin the cluster and catch up with transactions they missed, recovering to a correct state.
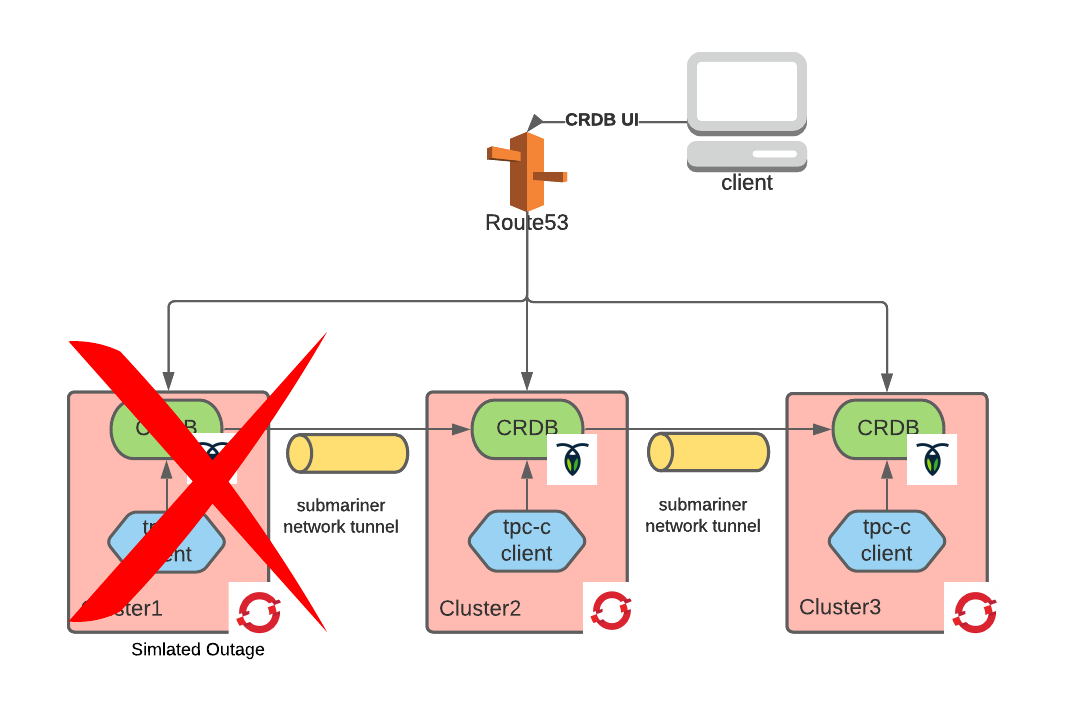
We ran this test while executing the TPC-C load test previously described. This simulates a scenario in which a globally-load-balanced, external-facing application receives requests and submits queries to the database locally. This is expected to be the most common scenario as it is unlikely the database will be exposed externally. Here is what we observed:
As soon as one of the VPCs was network-isolated and with it the entire OpenShift cluster running in it, we could not receive logs of the client in that OpenShift cluster.
The other two clients continued until the test completed. However, some errors were reported. We configured the test to retry the errored-out transactions as this would be a common configuration in most applications. As we can see from the results below, there were 10 errors in total.
Client 1
_elapsed___errors_____ops(total)___ops/sec(cum)__avg(ms)__p50(ms)__p95(ms)__p99(ms)_pMax(ms)__result
3600.0s 3 575365 159.8 91.1 62.9 100.7 285.2 19327.4
...
_elapsed_______tpmC____efc__avg(ms)__p50(ms)__p90(ms)__p95(ms)__p99(ms)_pMax(ms)
3600.0s 4162.0 32.4% 120.4 71.3 92.3 117.4 453.0 19327.4
Client 2
_elapsed___errors_____ops(total)___ops/sec(cum)__avg(ms)__p50(ms)__p95(ms)__p99(ms)_pMax(ms)__result
3600.0s 7 575015 159.7 70.6 65.0 109.1 142.6 19327.4
...
_elapsed_______tpmC____efc__avg(ms)__p50(ms)__p90(ms)__p95(ms)__p99(ms)_pMax(ms)
3600.0s 4161.8 32.4% 82.5 75.5 104.9 113.2 142.6 7247.8
The errors we concentrated at the time of the failure and are due to the database readjusting itself to the new condition in which some nodes were unavailable. During the failure, the database status page looked like this:
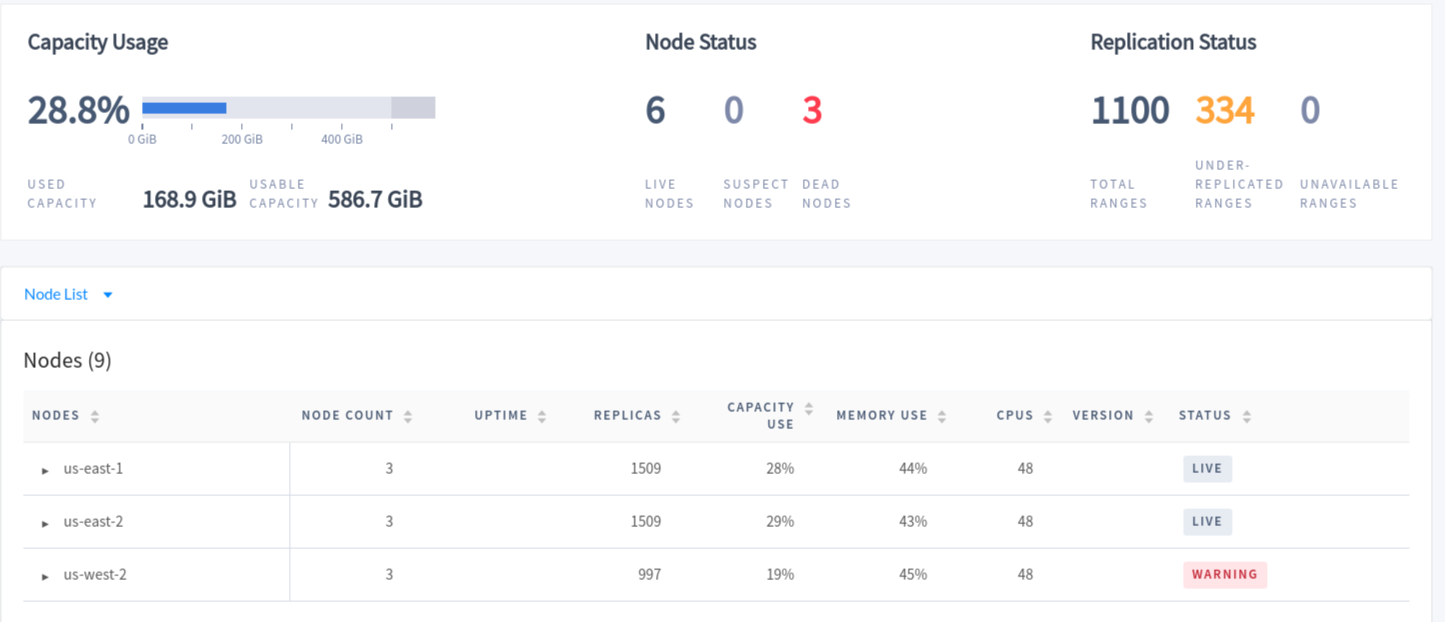
As you can see, the entire us-west-2 set of nodes were failing, causing some of the indexes to be under-replicated. After we restored the connectivity, the network tunnel was re-established automatically, and the database healed itself automatically. No human intervention was needed before, during, or after the disaster, which speaks to the resiliency of CockroachDB’s architecture.
Conclusions
In this article, we described a deployment of CockroachDB on OpenShift across multiple geographies. We validated the deployment with a load test confirming that it is suitable for enterprise workloads. Finally, we demonstrated through the use of a simulated disaster that with this architecture we achieve zero RPO and zero RTO. As the deployment steps were entirely scripted, they can be relatively easily reproduced by anyone.
The combination of cloud computing capabilities for easy access to geographical regions, Kubernetes platform for easy and declarative deployment of complex infrastructures and a new generation of stateful applications, such as CockroachDB, which can be deployed with geo-replication in an active/active highly-available fashion, allows for the democratization of zero RPO and zero RTO.
This type of setup can greatly help enterprise customers in their journey to modernize their infrastructure while improving service availability.
About the author
Raffaele is a full-stack enterprise architect with 20+ years of experience. Raffaele started his career in Italy as a Java Architect then gradually moved to Integration Architect and then Enterprise Architect. Later he moved to the United States to eventually become an OpenShift Architect for Red Hat consulting services, acquiring, in the process, knowledge of the infrastructure side of IT.
Currently Raffaele covers a consulting position of cross-portfolio application architect with a focus on OpenShift. Most of his career Raffaele worked with large financial institutions allowing him to acquire an understanding of enterprise processes and security and compliance requirements of large enterprise customers.
Raffaele has become part of the CNCF TAG Storage and contributed to the Cloud Native Disaster Recovery whitepaper.
Recently Raffaele has been focusing on how to improve the developer experience by implementing internal development platforms (IDP).
More like this
Reclaiming infrastructure autonomy: The 180-day mandate for virtualization service providers
Why Red Hat partners are the ultimate telco business asset
You Can’t Automate Collaboration | Code Comments
You Can’t Automate The Difficult Decisions | Code Comments
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds