
Introduction
When multiple OpenShift clusters are distributed in different data centers and possibly different geographies, one needs a method for directing traffic towards each instance.
For this scenario, a global load balancer provides a good solution.
A global load balancer is a DNS server that makes load balancing decisions based on a number of factors. As we know, DNS servers resolve a Fully Qualified Domain Name (FQDN) to one or more IP addresses that represent the location for the service. If the service exists in multiple locations, normally a DNS request will return a list of IPs leaving the choice of which IP address to use up to the client. A global load balancer differs from a standard DNS server as it makes a load balancing decision by returning only one of the available IP addresses.
The IP which is returned depends on the load balancing policy. Examples of load balancing policies are:
- Round Robin: For each request, the next IP in the list is returned. When at the end of the list, restart from the beginning.
- Geoproximity: Based on the geographical location of the IP of the caller, the IP of the service that is geographically closest is returned. Geographical distance can be calculated using look-up tables between IP ranges and geographical locations. Geographical distance is a good proxy of latency because of the law of physics of how signals propagate. So, this load balancing policy aims at minimizing the latency between the consumer and the service.
- Lowest latency: Based on recorded sampled time for packers to travel between the requests in the same area of the IP of the caller and the areas where the service is deployed, the IP of the service with the lowest latency is returned. This policy also aims at minimizing the time it takes between the service consumer and the service provider, but this is calculated based on observed metrics. This affords the ability to adjust to local internet slowdowns or outages.
Another major feature of a mature global load balancer is the ability to perform health checks of the targets behind an FQDN. If the health check fails, the target should be removed from the pool of the available destinations while it is marked as unavailable. This capability allows the system to always route the traffic to healthy targets and can be used as an enabler of modern DR strategies where the Recovery Time Objective (RTO) needs to be close to zero.
In this article, we will illustrate how to configure a global load balancer in front of a fleet of OpenShift clusters with an operator-based approach.
Global Load Balancing over Multiple OpenShift Clusters
In a previous article, I described a couple possible approaches for setting up a global load balancer in front of several Openshift clusters. Over the years and based on the experience of a few implementations, the following approach emerged as the best practice.
In each cluster, we deploy the same application using the same namespace name. The application will expose a route not using the cluster default route domain, but using a global domain name (routes with the default route domain can also be created, but they are outside of the scope for this design). For this example, assume the global domain (subdomain) is .myglobal.domain.io and that the global FQDN (or global route) for this application is myapp.myglobal.domain.io.

In this example, the Global Load Balancer has a definition for myapp.myglobal.domain.io which maps to the two VIPs of the two Local Load Balancers (LLB, also known as Local Traffic Managers [LTM]) in front of the OpenShift cluster’s routers (a Local Load Balancer is normally implemented as a L4 load balancer).
When a service consumer connects to myapp.myglobal.domain.io, the client sends a DNS request that is eventually handled by the global load balancer. The global load balancer will respond with one of the VIPs depending on the load balancing policy. At this point, the client will establish a connection with that VIP (it’s important to note that the connection does not flow through the global load balancer). The LLB load balances the traffic to one of the routers, and this router, in turn, directs traffic to one of the pods of the application.
This pattern will work with any number of OpenShift clusters, potential geographically distributed.
The “Global Load Balancer to Local Load Balancer to pool of applications” pattern is nothing new, and in fact, most globally-distributed internet-facing applications use some variations of this pattern. With OpenShift, however, we have the additional characteristic that multiple applications share the VIP of the local load balancer.
This implies that if we configure the Global Load Balancer health check to check for the status of the VIP, all the applications that share that VIP will failover together. This is typically not desirable. In fact most customers have the requirement that applications be able to failover individually.
In order for applications to be able to individually failover, we need to configure a health check that will traverse the entire stack and hit the underlying application pods in each of the clusters.
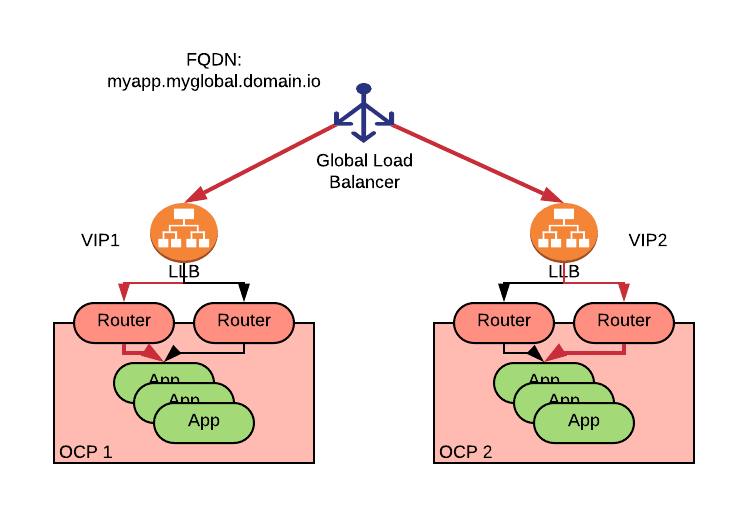
The above diagram depicts the path of the health check calls with a red line. The health checks must be HTTP(S) GETs requests (so they can propagate through the routers) and must be individually defined for each application.
The global load balancer must construct a HTTP payload with the global FQDN in the hostname header in order to traverse each of the Local Load Balancer VIPs.
Automating the Global Load Balancer Configuration with an Operator
It would be ideal, obviously, if the configuration that we have described previously could be automated. The trend with OpenShift 4.x is to create operators to seize automation opportunities. With this in mind, we have created the global-load-balancer-operator to automate the configuration of the DNS server that acts as a global load balancer.
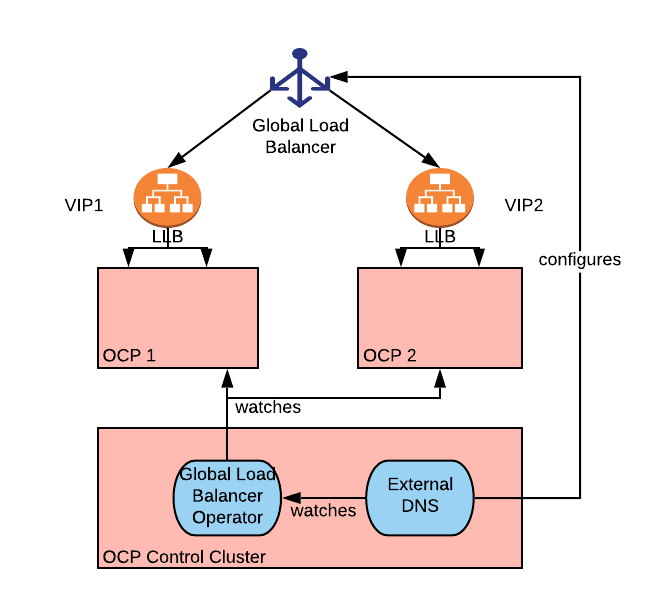
The global-load-balancer-operator is designed to be deployed in a control cluster independent of any of the clusters that need to be load balanced. This is the same architecture favored by Red Hat Advanced Cluster Management for Kubernetes (RHACM), which can be used to create and configure the load balanced clusters.
The diagram below captures the concept of control cluster.

The control cluster approach does become a single point of failure of the architecture, but ultimately does not pose a critical issue as the loss of the global-load-balancer-operator results in the inability to define new global DNS entries. Traffic will continue to flow normally to the applications.
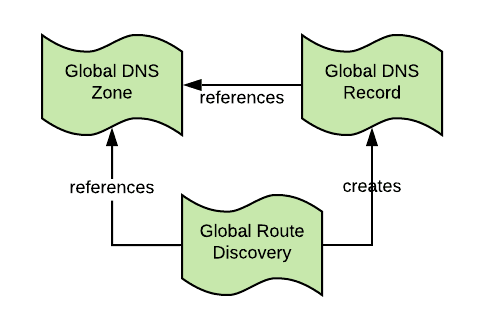
The global-load-balancer-operator features three main concepts, which translate to the following Cluster Resources (CRs):
- GlobalDNSZone: represents a DNS zone along with the provider.
- GlobalDNSRecord: represents a DNS record within a zone.
- GlobalRouteDiscovery: represents a strategy to auto discover GlobalDNSRecord based on routes found in the load balanced clusters.
The relationship between these Resources can be represented as follows:
Global DNS Zone
GlobalDNSZone represents a DNS zone (that is, a subdomain) that is to be used for the global FQDNs that will be defined. GlobalDNSZone also contains the connection information to the DNS service provider. At the moment, two providers are supported: ExternalDNS and Route53.
With External DNS, the global-load-balancer-operator prepares a DNSRecord CRs to be consumed by ExternalDNS which, in turn, is able to configure a wide array of DNS services.
With the Route53 provider, the global-load-balancer-operator talks directly to the Route53 APIs, enabling advanced features such as different load balancing policies and health checks. The table below summarizes the capabilities of the different providers:
|
Provider |
Supports Health Checks |
Supports Multivalue LB |
Supports Latency LB |
Supports Geoproximity LB |
|
External-dns |
no |
yes |
no |
no |
|
Route53 |
yes |
yes(*) |
yes(*) |
yes(*) |
(*) only if all managed clusters run on AWS.
More information on GlobalDNSZone can be found here.
Global DNS Record
GlobalDNSRecord represents a Record to be created in a GlobalDNSZone.
In order to create a record, we need to know the domain and the endpoints at which the service is reachable.
For now, the global-load-balancer-operator supports services exposed via routes. So, the endpoint at which these services are reachable are the VIPs of the LLBs that load balance the routers.
These are relatively straightforward to discover because in OCP 4.x, routers are implemented as ingress controllers, which, by default, create a LoadBalancer service. By looking up the external address of the LoadBalancer service, we can obtain the VIP.
The global-load-balancer-operator will watch for LoadBalancer services of the ingress controller and keep the GlobalDNSRecord up to date.
The GlobalDNSRecord is also where we can specify different load balancing policies and a health check, assuming those features are supported by the DNS service provider.
More information on the GlobalDNSRecord can be found here.
Global Route Discovery
GlobalRouteDiscovery represents a strategy to discover routes that are candidates to be represented in a GlobalDNSRecord. This is a convenience feature to allow users to not have to define GlobalDNSRecord for each application they expose manually.
The general idea is that if the same application is deployed in the same namespace across multiple clusters, and if that application exposes a route, the intention is to have the route be load balanced by a global load balancer.
The GlobalRouteDiscovery CR allows you to specify a route selector to identify the routes that are candidates. The global-load-balancer-operator then searches for these routes across the load balanced clusters and composes GlobalDNSRecords consistently with the discovered route definitions.
If the pods behind a route have readiness health checks of type HTTP GET, then the same health check will be reused in the created GlobalDNSRecord.
More information on the GlobalRouteDiscovery can be found here.
Installing Global Load Balancer Operator
In the project repository, you can find instructions on how to install the global-load-balancer-operator. As discussed throughout the course of this article, the operator requires a control cluster and one or more managed clusters. This setup can be complicated, so a scripted approach is available.
Conclusion
In this article, we illustrated an approach to global load balancing a set of OpenShift clusters and introduced an operator-based to automate the needed configuration. We used a programmable DNS service to create a global load balancer. It is worth noting that some companies use a Content Delivery Network (CDN) in front of their applications. CDNs function more like reverse proxy while also supporting the ability to load balance across multiple clusters. CDN services often expose an API, so the same concepts discussed for the DNS-based global load balancer can be applied to a CDN-based load balancer, including automation via an operator.
Finally, we discussed how the global-load-balancer-operator can be used as a way to automate the configuration of a DNS service. Currently, this operator supports advanced configurations, including sophisticated load balancing policies and health checks only for Route53. In the future, this operator may evolve to support advanced configurations for more DNS service providers. As with any community project, feedback and contributions are welcome. More information can be found in the project repository.
About the author
Raffaele is a full-stack enterprise architect with 20+ years of experience. Raffaele started his career in Italy as a Java Architect then gradually moved to Integration Architect and then Enterprise Architect. Later he moved to the United States to eventually become an OpenShift Architect for Red Hat consulting services, acquiring, in the process, knowledge of the infrastructure side of IT.
Currently Raffaele covers a consulting position of cross-portfolio application architect with a focus on OpenShift. Most of his career Raffaele worked with large financial institutions allowing him to acquire an understanding of enterprise processes and security and compliance requirements of large enterprise customers.
Raffaele has become part of the CNCF TAG Storage and contributed to the Cloud Native Disaster Recovery whitepaper.
Recently Raffaele has been focusing on how to improve the developer experience by implementing internal development platforms (IDP).
More like this
Reclaiming infrastructure autonomy: The 180-day mandate for virtualization service providers
Why Red Hat partners are the ultimate telco business asset
Crack the Cloud_Open | Command Line Heroes
Edge computing covered and diced | Technically Speaking
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds