
There will always be a time where computing environments will encounter a failure. This could be a power outage or networking failure. In the extreme, it could be water or fire that causes the failure.
Failures can be minimized with planning. But even with the best planning, failures still occur. Using a clustered environment like Red Hat OpenShift is a great way to help minimize potential issues and their impacts. Running workloads as virtual machines or containers allows them to run across multiple servers or even sites, spreading the workloads out in this way can help minimize the impact caused by a failure.
However, even with all the planning to help prevent failures, they still occur. Even a single node failing in a cluster has an impact. The workloads running on the node will fail and new workloads cannot be started on the node.
Monitoring the environments can help notify someone of the failure so they can fix it. But all this takes time even with an automated notification system. The notification system needs to recognize there is an issue, then it needs to notify someone. After someone, either an individual or a group, is notified - they must fix the issue and restart the workloads. All of this takes valuable time, time that the VM could be processing data or providing its service.
Luckily, there are two operators in OpenShift that can help resolve issues without any user intervention, thus saving valuable time. These are the Node Health Check and the Self Node Remediation operators. These operators work together to try and fix issues with the nodes in the cluster and move the workloads that were on the node to different nodes. This helps minimize the downtime of the workloads and cluster node. And as they say, time is money.
Let me point out that the remediation is not the same as a live migration. Live migrations are done on running VMs and interruption to the workload is minimized. Live migrations are used to move VMs to different nodes in a healthy environment. The VMs continue running and are not stopped or restarted. Most times an interruption is not noticed.
Remediation is different. The remediation performed using these operators is done when a failure occurs on nodes in the environment. The operators attempt to automatically remediate the failures on the nodes to limit the time a node is in a degraded state. Remediation does not guarantee 100% uptime of the workload. By the time a remediation occurs, the workload is either down or inaccessible. The degrade node reboots during a remediation and any workloads on the node are stopped, or will be stopped, by the reboot process. New instances of the workloads are then started on different nodes.
This Environment
The environment being used consists of six physical servers. Three servers run as control plane nodes and three servers run as worker nodes. All the nodes are running OpenShift 4.11.
The installation and configuration of the Operators was performed using a cluster account with cluster admin privileges. The following Operators are installed and configured:

The OpenShift Data Foundation (ODF) operator is installed and a Storage System is configured to use a second hard disk installed in the nodes as shared Ceph storage. The ocs-storagecluster-ceph-rbd StorageClass is configured as the default StorageClass by adding the "storageclass.kubernetes.io/is-default-class: true" annotation to it.
The ODF operator requires the Local Storage operator when using local storage for the ODF cluster. The ODF operator prompts to install this if needed. No further configuration of the Local Storage operator is needed.
The OpenShift Virtualization operator is installed and an OpenShift Virtualization Deployment is configured using default values.
The NMState operator is installed and an NMState instance created. NMState is used to create a bridged interface called internal on the ens5f1 interface on all the nodes. This bridge is used for VM traffic to an internal network and was created using the following YAML:
apiVersion: nmstate.io/v1
kind: NodeNetworkConfigurationPolicy
metadata:
name: internal-br-ens5f1
spec:
desiredState:
interfaces:
- name: internal
description: Internal Network Bridge
type: linux-bridge
state: up
ipv4:
enabled: false
bridge:
options:
stp:
enabled: false
port:
- name: ens5f1
After the NodeNetworkConfigurationPolicy (NNCP) is applied, a NetworkAttachmentDefinition (NAD) is created in the nhc-snr-blog project namespace. This NAD is called internal-traffic and connects to the internal bridge created with the NNCP.
There are four VMs running in the cluster. Two are running Microsoft Windows 11 and two are running Red Hat Enterprise Linux 9 (RHEL9). All the VMs connect to the default POD network in the cluster. One Microsoft Windows 11 VM and one RHEL9 VM have a second interface attached to the internal NAD. Services are created for the Microsoft Windows 11 and RHEL9 VMs that are not connected to the NAD. The Service for the Microsoft Windows 11 VM exposes the Remote Desktop Protocol (RDP) port of the VM outside the cluster. The Service for the RHEL9 VM exposes the SSH port of the VM outside the cluster.
These connections are created to show that the remediation affects the VMs of both types of networking the same whether they are RHEL VMs or Microsoft Windows VMs.
Configuring Remediation
Let's install the Node Health Check (NHC) operator and the Self Node Remediation (SNR) operator.
The NHC operator watches the nodes state for an indication a failure occurred. It then creates a remediation. When the SNR operator sees the created remediation, it tries to resolve the failures with the node. The SNR Operator is also responsible for notifying the scheduler to relocate any workloads running on the node onto a different node.
The operators are available through the OperatorHub. They are installed by navigating to Operators -> OperatorHub. Please note that there are two Node Health Check operators available, one is provided by Red Hat and the other is a Community Edition. The operator provided by Red Hat is the one we will use.
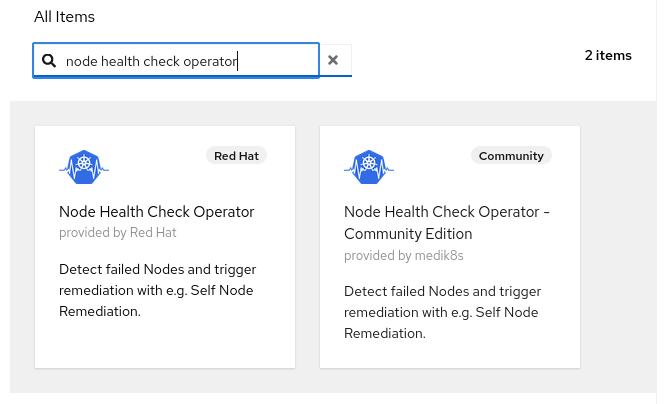
Installing the NHC operator also installs the Self Node Remediation operator.

Once the operators are installed, they will remediate issues with the worker nodes without further configuration. However, the configuration of each operator can be changed to fine tune when a remediation is performed.
NHC Operator Configuration
The configuration for the NHC operator is done in its YAML. This can be accessed from the UI by navigating to Operators -> Installed Operators -> Node Health Check Operator -> Node Health Check and selecting the nhc-worker-default NodeHealthCheck.
It can also be accessed using the CLI with the command:
oc get -n openshift-operators nhc nhc-worker-default -o yaml
The YAML file should appear similar to the following. Note that the UI will show some extra metadata that can be ignored.
apiVersion: remediation.medik8s.io/v1alpha1
kind: NodeHealthCheck
metadata:
name: nhc-worker-default
spec:
minHealthy: 51%
remediationTemplate:
apiVersion: self-node-remediation.medik8s.io/v1alpha1
kind: SelfNodeRemediationTemplate
name: self-node-remediation-resource-deletion-template
namespace: openshift-operators
selector:
matchExpressions:
- key: node-role.kubernetes.io/worker
operator: Exists
unhealthyConditions:
- duration: 300s
status: 'False'
type: Ready
- duration: 300s
status: Unknown
type: Ready
status:
conditions:
- lastTransitionTime: '2022-11-10T17:53:58Z'
message: 'No issues found, NodeHealthCheck is enabled.'
reason: NodeHealthCheckEnabled
status: 'False'
type: Disabled
healthyNodes: 3
observedNodes: 3
phase: Enabled
reason: 'NHC is enabled, no ongoing remediation'
The following configuration lines are worth noting for configuration and status. Please see the NodeHealthCheck Operator Documentation for further information.
-
metadata.name
This is the name for the NodeHealthCheck.
-
spec.minHealthy
This specifies the minimum number of nodes needed to allow remediation to occur. The default value is 51%.
-
spec.remediationTemplate
This specifies the template to use for remediation. This is the template provided by the SNR Operator. As of the writing of this blog post, only the self-node-remediation-resource-deletion-template is supported. The self-node-remediation-node-deletion-template will be obsoleted in a future release.
-
spec.selector
This specifies the nodes that the Operator will remediate. As of the writing of this blog, the Operator only remediates worker nodes. Future releases of the operator should support the remediation of Control Plane nodes as well.
-
spec.unhealthyConditions
This specifies the node conditions that will trigger a remediation event. The default configuration above will trigger a remediation when the type status.condition of a node is in an unknown or False state for 300 seconds (5 minutes).
-
status
This shows the state of the Operator, how many healthyNodes are available, how many observedNodes are being watched by the operator and if a remediation is currently in progress.
This cluster's environment is pretty stable. Let's change the the default values for the unhealthyConditions from 300s to 60s. This will make a remediation occur four minutes earlier, meaning our VMs will become available again four minutes earlier.
The following patch makes the changes. The UI could also be used to edit the YAML.
oc patch -n openshift-operators nhc nhc-worker-default --type json -p '[
{"op": "replace", "path": "/spec/unhealthyConditions/0/duration", "value": "60s"},
{"op": "replace", "path": "/spec/unhealthyConditions/1/duration", "value": "60s"}
]'
SNR Operator Configuration
Once a Remediation is created, the SNR Operator is responsible for notifying the scheduler to reschedule the workloads onto different nodes.
Let's look at the SNR operator's configuration. This can be seen in the UI by navigating to Operators -> Installed Operators -> Self Node Remediation Operator -> Self Node Remediation Config. It can also be accessed from the command line using the command:
oc get -n openshift-operators snrc self-node-remediation-config -o yaml
The following is the configuration for the SNR Operator.
apiVersion: self-node-remediation.medik8s.io/v1alpha1
kind: SelfNodeRemediationConfig
metadata:
name: self-node-remediation-config
namespace: openshift-operators
spec:
apiServerTimeout: 5s
peerApiServerTimeout: 5s
isSoftwareRebootEnabled: true
watchdogFilePath: /dev/watchdog
peerDialTimeout: 5s
peerUpdateInterval: 15m
apiCheckInterval: 15s
peerRequestTimeout: 5s
safeTimeToAssumeNodeRebootedSeconds: 180
maxApiErrorThreshold: 3
Configuring the SNR operator takes a little more thought and consideration of the cluster's environment.
Lets start with the safeTimeToAssumeNodeRebootedSeconds configuration option because it requires a little explanation.
The SNR Operator will try to determine a minimum value for safeTimeToAssumeNodeRebootedSeconds using a formula written in the code. The formula uses the values of apiCheckInterval, apiServerTimeout, peerDialTimeout, and peerRequestTimeout to calculate the minimum value.
The formula also uses the timeout value of the watchdog device in its calculations. This value can be viewed by looking at the watchdog devices setting under /sys. My environment has the timeout value stored in /sys/class/watchdog/watchdog0/timeout
$ oc debug node/wwk-1
sh-4.4# chroot /host
sh-4.4# cat /sys/class/watchdog/watchdog0/timeout
60
The formula from the code equates to the following.
( (apiCheckInterval + apiServerTimeout) * maxApiErrorThreshold )
+ ( (10 + 1) * (peerDialTimeout + peerRequestTimeout) )
+ watchdogTimeout
+ 15 * 1
Which equates to the following with this environments watchdog timeout of 60 seconds:
( (15 + 5) * 3 ) + ( 11 * (5 + 5) ) + 60 + 15 = 245 seconds
The safeTimeToAssumeNodeRebootedSeconds configuration option can be used to override the value that is automatically calculated. However, the option overrides the value only if it is greater than the automatically calculated value. So in this environment, the value of safeTimeToAssumeNodeRebootedSeconds is ignored.
Even with the default settings, the value of safeTimeToAssumeNodeRebootedSeconds will be ignored. This is because if the calculations are done with a value of zero for the watchdog timer, a minimal calculated value using the formula with all default values is 185 seconds. Since the default value of safeTimeToAssumeNodeRebootedSeconds is 180 seconds, and is less than the value calculated by the formula, it will be ignored.
The values for the options and the timeout for the watchdog device can be changed to get a lower calculated value. If you decide to make changes, you should take care that the changed values do not create an unstable cluster due to environment issues such as a slow or burdened network.
See the documentation on Remediating nodes with the Self Node Remediation Operator for information on all the configuration settings for the SNR Operator.
Testing Remediation
In this environment, once a Worker node enters a NotReady state we can expect VMs to be rescheduled onto a different node when either safeTimeToAssumeNodeRebootedSeconds passes or the remediated node becomes ready again. Remember, the value used for safeTimeToAssumeNodeRebootedSeconds is either calculated by the Operator or the setting in the configuration YAML is used -- whichever has the greatest value.
Please note that waiting for safeTimeToAssumeNodeRebootedSeconds to pass or for the remediating node to become Ready is done to help prevent two instances of a VM from running at the same time. Multiple instances of the same VM running can potentially have both VMs access the same storage PVC and cause data corruption.
To test remediation and its effects on VMs, we need at least one VM. As mentioned above, there are currently four VMs running in the cluster.
Let's simulate a failure by stopping the Kubelet service on the worker node running the VMs. All the VMs were Live Migrated to the wwk-1 worker node.
$ oc debug node/wwk-1
Starting pod/wwk-1-debug ...
To use host binaries, run `chroot /host`
Pod IP: 10.19.3.91
If you don't see a command prompt, try pressing enter.
sh-4.4# chroot /host
sh-4.4# systemctl stop kubelet
Removing debug pod ...
$
Watching the output of the oc get nodes command shows that the node enters a NotReady state. After about a minute, the time specified for spec.unhealthyConditions in the NHC operators configuration, the nodes status changes to SchedulingDisabled. This indicates a remediation has been created by the NHC operator and the node reboots.
$ oc get nodes wwk-1 -w | ts
[2023-01-03 15:10:27] NAME STATUS ROLES AGE VERSION
[2023-01-03 15:10:27] wwk-1 Ready worker 32d v1.24.6+5157800
[2023-01-03 15:11:02] wwk-1 NotReady worker 32d v1.24.6+5157800
[2023-01-03 15:11:02] wwk-1 NotReady worker 32d v1.24.6+5157800
[2023-01-03 15:11:07] wwk-1 NotReady worker 32d v1.24.6+5157800
[2023-01-03 15:11:14] wwk-1 NotReady worker 32d v1.24.6+5157800
[2023-01-03 15:12:03] wwk-1 NotReady worker 32d v1.24.6+5157800
[2023-01-03 15:12:03] wwk-1 NotReady,SchedulingDisabled worker 32d v1.24.6+5157800
[2023-01-03 15:12:04] wwk-1 NotReady,SchedulingDisabled worker 32d v1.24.6+5157800
[2023-01-03 15:15:25] wwk-1 NotReady,SchedulingDisabled worker 32d v1.24.6+5157800
[2023-01-03 15:16:10] wwk-1 Ready,SchedulingDisabled worker 32d v1.24.6+5157800
[2023-01-03 15:16:10] wwk-1 Ready,SchedulingDisabled worker 32d v1.24.6+5157800
[2023-01-03 15:16:12] wwk-1 Ready,SchedulingDisabled worker 32d v1.24.6+5157800
[2023-01-03 15:16:20] wwk-1 Ready,SchedulingDisabled worker 32d v1.24.6+5157800
[2023-01-03 15:16:20] wwk-1 Ready,SchedulingDisabled worker 32d v1.24.6+5157800
[2023-01-03 15:16:20] wwk-1 Ready,SchedulingDisabled worker 32d v1.24.6+5157800
[2023-01-03 15:16:30] wwk-1 Ready,SchedulingDisabled worker 32d v1.24.6+5157800
[2023-01-03 15:16:36] wwk-1 Ready worker 32d v1.24.6+5157800
After the node reboots, we can see the VMs get rescheduled to a different node. The following only shows one VM for brevity.
$ oc -n nhc-snr-blog get vmi -w | ts
[2023-01-03 15:10:28] NAME AGE PHASE IP NODENAME READY
[2023-01-03 15:10:28] rhel9-internal-network 27d Running 10.129.3.41 wwk-1 True
[2023-01-03 15:11:02] rhel9-internal-network 27d Running 10.129.3.41 wwk-1 False
[2023-01-03 15:12:03] rhel9-internal-network 27d Running 10.129.3.41 wwk-1 False
[2023-01-03 15:12:05] rhel9-internal-network 27d Running 10.129.3.41 wwk-1 False
[2023-01-03 15:15:11] rhel9-internal-network 27d Running 10.129.3.41 wwk-1 False
[2023-01-03 15:16:21] rhel9-internal-network 27d Failed 10.129.3.41 wwk-1 False
[2023-01-03 15:16:21] rhel9-internal-network 27d Failed 10.129.3.41 wwk-1 False
[2023-01-03 15:16:21] rhel9-internal-network 27d Failed 10.129.3.41 wwk-1 False
[2023-01-03 15:16:22] rhel9-internal-network 27d Failed 10.129.3.41 wwk-1 False
[2023-01-03 15:16:22] rhel9-internal-network 0s Pending
[2023-01-03 15:16:23] rhel9-internal-network 0s Pending
[2023-01-03 15:16:24] rhel9-internal-network 2s Pending False
[2023-01-03 15:16:25] rhel9-internal-network 3s Scheduling False
[2023-01-03 15:16:26] rhel9-internal-network 3s Scheduling False
[2023-01-03 15:17:01] rhel9-internal-network 38s Scheduled wwk-2 False
[2023-01-03 15:17:01] rhel9-internal-network 38s Scheduled wwk-2 False
[2023-01-03 15:17:03] rhel9-internal-network 40s Running 10.128.2.225 wwk-2 False
[2023-01-03 15:17:03] rhel9-internal-network 40s Running 10.128.2.225 wwk-2 True
During the remediation process, the VMs stop running and become unavailable. After the remediation is completed, a new instance of the VM is started on a different worker node.
The process does not show well in a blog post, so I have created a video that demonstrates the effects of a remediation on a VM. It also shows the difference between a Live Migration and Remediation. The video, Keeping Virtual Machines Running, can be found on the OpenShift YouTube channel.
Final Thoughts
As you can see, the Node Health Check and Self Node Remediation operators work together to help keep a cluster healthy. And although they do not guarantee 100% uptime of the workloads, they do allow workloads to restart quicker than most manual interventions would. This pairing of operators provides a great solution to help prevent workloads from being down for an excessive period of time while issues are addressed.
About the author

More like this
Context-aware advisor recommendations in Red Hat Lightspeed
A decade of open innovation: Red Hat continues to scale the open hybrid cloud with Microsoft
Crack the Cloud_Open | Command Line Heroes
Edge computing covered and diced | Technically Speaking
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds