
Welcome to the second installment of our Kubernetes API Server deep dive series. Last time we, Stefan and Michael, had a look at what the API Server is, introduced the terminology, and discussed how the request flow works. This time around we’ll focus on a topic we only mentioned in passing: Where and how the state of Kubernetes objects is managed in a reliable and persistent way. As you might remember, the API Server itself is stateless and the only component that directly talks with the distributed storage component: etcd.
A Quick etcd Intro
From your *nix operating system you know that /etc is used to store config data and, in fact, the name etcd is inspired by this, adding the "d" for distributed. Any distributed system will likely need something like etcd to store data about the state of the system, enabling it to retrieve the state in a consistent and reliable fashion. To coordinate the data access in a distributed setup, etcd uses the Raft protocol. Conceptually, the data model etcd supports is that of key-value store. In etcd2 the keys formed a hierarchy and with the introduction of etcd3 this has turned into a flat model, while maintaining backwards compatibility concerning hierarchical keys:
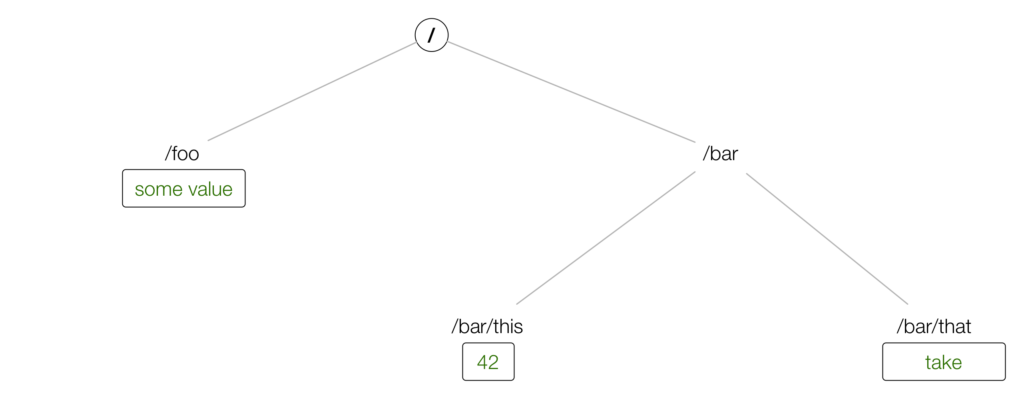
Using a containerized version of etcd, we can create the above tree and then retrieve it as follows:
$ docker run --rm -d -p 2379:2379 \
--name test-etcd3 quay.io/coreos/etcd:v3.1.0 /usr/local/bin/etcd \
--advertise-client-urls http://0.0.0.0:2379 --listen-client-urls http://0.0.0.0:2379
$ curl localhost:2379/v2/keys/foo -XPUT -d value="some value"
$ curl localhost:2379/v2/keys/bar/this -XPUT -d value=42
$ curl localhost:2379/v2/keys/bar/that -XPUT -d value=take
$ http localhost:2379/v2/keys/?recursive=true
HTTP/1.1 200 OK
Content-Length: 327
Content-Type: application/json
Date: Tue, 06 Jun 2017 12:28:28 GMT
X-Etcd-Cluster-Id: 10e5e39849dab251
X-Etcd-Index: 6
X-Raft-Index: 7
X-Raft-Term: 2
{ "action": "get", "node": { "dir": true, "nodes": [ { "createdIndex": 4, "key": "/foo", "modifiedIndex": 4, "value": "some value" }, { "createdIndex": 5, "dir": true, "key": "/bar", "modifiedIndex": 5, "nodes": [ { "createdIndex": 5, "key": "/bar/this", "modifiedIndex": 5, "value": "42" }, { "createdIndex": 6, "key": "/bar/that", "modifiedIndex": 6, "value": "take" } ] } ] } }
Now that we’ve established how etcd works in principle, let’s move on to the subject of how etcd is used in Kubernetes.
Cluster state in etcd
In Kubernetes, etcd is an independent component of the control plane. Up to Kubernetes 1.5.2, we used etcd2 and from then on switched to etcd3. Note that in Kubernetes 1.5.x etcd3 is still used in v2 API mode and going forward this is changing to the v3 API, including the data model used. From a developer’s point of view this doesn’t have direct implications, because the API Server takes care of abstracting the interactions away—compare the storage backend implementation for v2 vs. v3. However, from a cluster admin’s perspective, it’s relevant to know which etcd version is used, as maintenance tasks such as backup and restore need to be handled differently.
You can influence the way the API Server is using etcd via a number of options at start-up time; also, note that the output below was edited to highlight the most important bits:
$ kube-apiserver -h
...
--etcd-cafile string SSL Certificate Authority file used to secure etcd communication.
--etcd-certfile string SSL certification file used to secure etcd communication.
--etcd-keyfile string SSL key file used to secure etcd communication.
...
--etcd-quorum-read If true, enable quorum read.
--etcd-servers List of etcd servers to connect with (scheme://ip:port) …
...
Kubernetes stores its objects in etcd either as a JSON string or in Protocol Buffers ("protobuf" for short) format. Let’s have a look at a concrete example: We launch a pod webserver in namespace apiserver-sandbox using an OpenShift v3.5.0 cluster. Then, using the etcdctl tool, we inspect etcd (which is in version 3.1.0, in our environment):
$ cat pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: webserver
spec:
containers:
- name: nginx
image: tomaskral/nonroot-nginx
ports:
- containerPort: 80
$ kubectl create -f pod.yaml
$ etcdctl ls /
/kubernetes.io
/openshift.io
$ etcdctl get /kubernetes.io/pods/apiserver-sandbox/webserver { "kind": "Pod", "apiVersion": "v1", "metadata": { "name": "webserver", ...
So, how does the object payload end up in etcd, starting from kubectl create -f pod.yaml?
The following diagram depicts the overview flow:
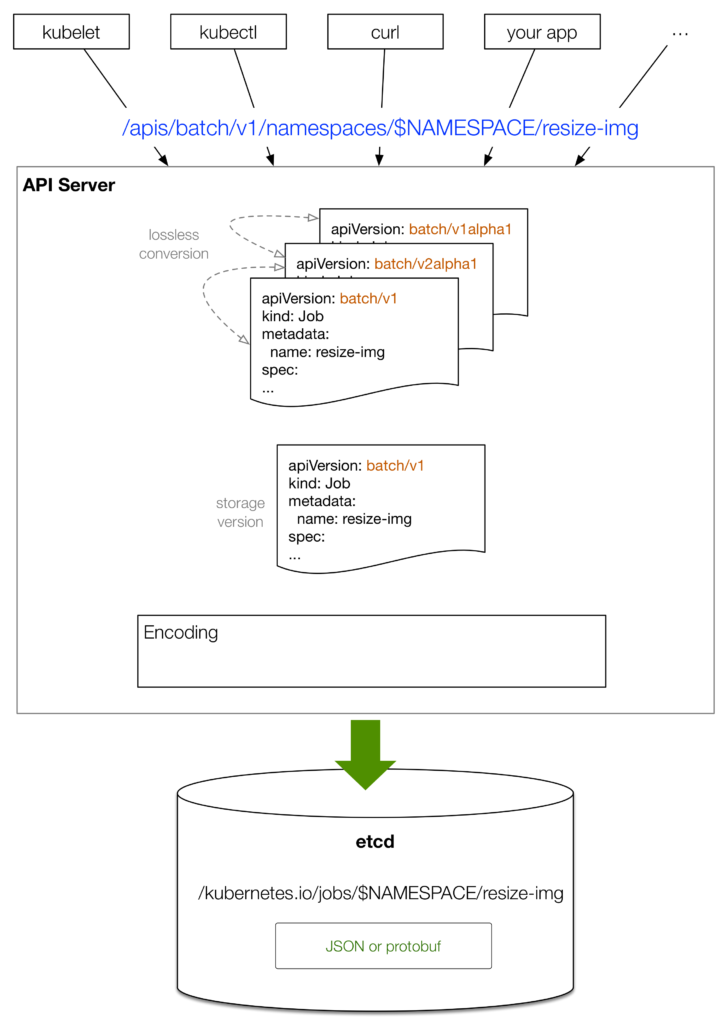
- A client such as
kubectlprovides an desired object state, for example, YAML in versionv1. kubectlconverts the YAML into JSON to send it over the wire.- Between different versions of the same
kind, the API server can perform a lossless conversion leveraging annotations to store information that cannot be expressed in older API versions. - The API Server turns the input object state into a canonical storage version, depending on the API Server version itself, usually the newest stable one, for example, v1.
- Last but not least comes actual storage process in etcd, at a certain key, into a value with the encoding to JSON or protobuf.
You can configure the kube-apiserver with the preferred serialization using --storage-media-type option which defaults to application/vnd.kubernetes.protobuf as well as on a per-group basis the default storage version with the --storage-versions option.
Let’s now have a look how the lossless conversion works in practice. We will use a Kubernetes object of type Horizontal Pod Autoscaling (HPA), which as the name suggests, has a controller attached to it that is supervising and updating a ReplicationController, depending on utilization metrics.
We start with proxying the Kubernetes API (so that we can later directly access it from the local machine), launch a ReplicationController, and an HPA along with it:
$ kubectl proxy --port=8080 &
$ kubectl create -f https://raw.githubusercontent.com/mhausenblas/kbe/master/specs/rcs/rc.yaml
kubectl autoscale rc rcex --min=2 --max=5 --cpu-percent=80
kubectl get hpa/rcex -o yaml
Now, using httpie—but you can also use curl if you want—we ask the API server for the HPA object in the current stable version (autoscaling/v1) as well as in the previous one (extensions/v1beta1) and finally compare the two versions:
$ http localhost:8080/apis/extensions/v1beta1/namespaces/api-server-deepdive/horizontalpodautoscalers/rcex > hpa-v1beta1.json
$ http localhost:8080/apis/autoscaling/v1/namespaces/api-server-deepdive/horizontalpodautoscalers/rcex > hpa-v1.json
$ diff -u hpa-v1beta1.json hpa-v1.json
{
"kind": "HorizontalPodAutoscaler",
- "apiVersion": "extensions/v1beta1",
+ "apiVersion": "autoscaling/v1",
"metadata": {
"name": "rcex",
"namespace": "api-server-deepdive",
- "selfLink": "/apis/extensions/v1beta1/namespaces/api-server-deepdive/horizontalpodautoscalers/rcex",
+ "selfLink": "/apis/autoscaling/v1/namespaces/api-server-deepdive/horizontalpodautoscalers/rcex",
"uid": "ad7efe42-50ed-11e7-9882-5254009543f6",
"resourceVersion": "267762",
"creationTimestamp": "2017-06-14T10:39:00Z"
},
"spec": {
- "scaleRef": {
+ "scaleTargetRef": {
"kind": "ReplicationController",
"name": "rcex",
- "apiVersion": "v1",
- "subresource": "scale"
+ "apiVersion": "v1"
},
"minReplicas": 2,
"maxReplicas": 5,
- "cpuUtilization": {
- "targetPercentage": 80
- }
+ "targetCPUUtilizationPercentage": 80
You can see that the schema for a HorizontalPodAutoscaler changed from v1beta1 to v1. The API server is able to losslessly convert between those versions, independent of which version actually stored in etcd.
With the basics of the storage flow out of the way, we now focus on the details of how the API server encodes and decodes payload as well as stores it in either JSON or protobuf, also taking the etcd version used into account.
Serialization of State Flow in Detail
The API Server keeps all known Kubernetes object kinds in a Go type registry called Scheme. In this registry, each version of kinds are defined along with how they can be converted, how new objects can be created, and how objects can be encoded and decoded to JSON or protobuf.
When the API server receives an object, for example, from kubectl, it will know from the HTTP path which version to expect. It creates a matching empty object using the Scheme in the right version and converts the HTTP payload using a JSON or protobuf decoder. The decoder converts the binary payload into the created object.
The decoded object is now in one of the supported versions for the given type. For some types there are a handful of versions throughout its development. To avoid problems with that, the API server has to know how to convert between each pair of those versions (for example, v1 ⇔ v1alpha1, v1 ⇔ v1beta1, v1beta1 ⇔ v1alpha1), the API server uses one special “internal” version for each type. This internal version of a type is a kind of superset of all supported versions for the type with all their features. It converts the incoming object to this internal version first and then to the storage version:
v1beta1 ⇒ internal ⇒ v1
During the first step of this conversion it will also set defaults for certain fields if they have been omitted by the user. Imagine v1beta1 does not have a certain mandatory field which was added in v1. In this case, the user cannot even fill in a value for that field. Then the conversion step will set the default value for this field in order to create a valid internal object.
Validation and Admission
There are two more important steps next to conversion. The actual flow looks like this:
v1beta1 ⇒ internal ⇒ | ⇒ | ⇒ v1 ⇒ json/yaml ⇒ etcd
admission validation
The admission and validation steps are gating creation and updates of objects before they are written to etcd. Here are their roles:
- Admission checks that an object can be created or updated by verifying cluster global constraints and might set defaults depending on the cluster configuration.
There are a number of them in Kubernetes, and many more in a multi-tenant capable Kubernetes like OpenShift. Some of them are:NamespaceLifecycle– rejects all incoming requests in a namespace context if the namespace does not exist.LimitRanger– enforces usage limits on a per resource basis in the namespace.ServiceAccount– creates a service account for a pod.DefaultStorageClass– sets the default value of aPersistentVolumeClaims storage class, in case the user did not provide a value.ResourceQuota– enforces quota constraints for the current user on the cluster and might reject requests if the quota is not enough.
- Validation checks that an incoming object (during creation and updates) is well-formed in the sense that it only has valid values, for example:
- It checks that all mandatory fields are set.
- It checks that all strings have a valid format (for example, only include lowercase characters).
- It checks that no contradicting fields are set (for example, two containers with the same name).
Validation does not look at other instances of the type or even of other types. In other words, validation is local, static checks for each object, independent from any API server configuration.
Admission plugins can be enabled/disabled using the --admission-control=<plugins> flags. Most of them can also be configured by the cluster admin. Moreover, in Kubernetes 1.7 there is a webhook mechanism to extend the admission mechanism and an initializer concept to implement custom admission for new objects using a controller.
Migration of Storage Objects
A final note on the migration of storage objects: When upgrading Kubernetes to a newer version it is increasingly important to back up your cluster state and to follow the documented migration steps for each release. This stems from the move from etcd2 to etcd3 and also the continuous development of the Kubernetes kinds and their versions.
In etcd each object is stored in the preferred storage version for its kind. But, as this changes over time it might be that you have objects in your etcd storage in a very old version. If this version is deprecated and eventually removed from the API server, you won’t be able to decode its protobuf or JSON anymore. For that reason, migration procedures exist to rewrite those objects before the cluster is upgraded.
The following resources can help you to tackle this challenge:
- See the Kubernetes Cluster Management Guide for Version 1.6 as well as the Upgrading to a different API version section in the cluster management docs.
- In the OpenShift docs, see the Performing Manual In-place Cluster Upgrades.
- If you want a tool—as CLI tool or Web app—to assist you with the process, check out ReShifter, which is capable of backup/restore and migration for both vanilla Kubernetes clusters as well as OpenShift clusters.
Next time, in the third installment of the API Server series, we will discuss how you can extend the Kubernetes API, using Custom Resource Definitions and User API Servers.
Also, we’d like to give Sergiusz Urbaniak kudos for etcd-related support.
About the authors
More like this
Why Red Hat partners are the ultimate telco business asset
Reclaiming infrastructure autonomy: The 180-day mandate for virtualization service providers
Crack the Cloud_Open | Command Line Heroes
Edge computing covered and diced | Technically Speaking
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds