
In the first two installments of this series we reviewed the general flow in the API server and how state is managed using etcd. Now we’re moving to the topic of how to extend the core API.
Initially, the only way to extend the API Server was to fork and patch the kube-apiserver source code and integrate your own resources. Alternatively, one could try and lobby to get the new types upstream into the core set of objects. This, however, leads to an issue: The core API would grow over time, leading to a potentially bloated API. Rather than letting the core get too unwieldy, the project came up with two ways to extend the core:
- Using Custom Resource Definition (CRDs) which formerly were called Third Party Resources (TPRs). With these CRDs you have a simple, yet flexible way to define your own object kinds and let the API Server handle the entire lifecycle.
- Using User API Servers (UAS) that run in parallel to the main API Server. These are more involved in terms of development and require you to invest more up-front: however, they give you much more fine-grained control over what is going on with the objects.
Also, in the context of extensions, we will discuss the object lifecycle (from initialization to admission to finalizers). We'll cover the topic of CRDs in two posts as it is rather elaborate and we’re dealing with a few moving targets in the 1.7 to 1.8 transition. In this post, we focus on CRDs and in the second part we will show you how to write a custom controller for it, including code generation with kube-gen.
Declaration and Creation of CRDs
As we discussed in part 1, resources are grouped by API groups and have corresponding HTTP paths per version. Now if you were to implement a CRD, the first task is to name a new API group that can not overlap with an existing core group. Inside your own API group you can have as many resources as you like and they can have the same names as may exist in other groups. Let’s have a look at a concrete example:

We differentiate between the CRD, which is like a class definition in object-oriented programming and the actual custom resource (CR) that you can view as a sort of instance. First we have a look at the class-level definition: In line 1 above you see the CRD apiVersion you must use; every kube-apiserver 1.7 and higher supports this. In line 5 and below you use the spec fields to define:
- In line 6: The CRD API group (a good practice is to use a fully qualified domain name of your organization,
example.comin our case. - In line 7: The version of your CRD object. There is only one version per resource, but there can be multiple resources with different versions in your API group.
The spec.names field has two mandatory children:
- In line 9: The
kind, which is the upper-case singular by convention (Database) - In line 10: The
plural, which is the lowercase plural by convention (databaseshere). You define the resource/HTTP path using the interestingly named fieldplural, which leads in our example tohttps://<server/apis/example.com/v1/namespaces/default/databases. There is also the optionalsingularfield that defaults to the lowercase kind value and can be used in the context of kubectl.
In addition spec.names has a number of optional fields which are derived and filled in automatically by the API Server.
Remember from part 1 that the kind describes the type of the object, while the resource corresponds to the HTTP path. Most of the times, those two match; but in certain situations, the API server might return different kinds on the same API http path (example: Status error object which are another kind, obviously).
Note that the resource name (databases in our example) and the group (example.com) must match the metadata field name (see line 4, above).
Now we’re in a position to actually create the CRD based on the above YAML spec:
$ kubectl create -f databases-crd.yaml
customresourcedefinition "databases.example.com" created
Note that this creation process is an asynchronous one, meaning you have to check the CRD status to show that the specified names are accepted (that is, there are no name conflicts with other resources) and the API server has established the API handlers to serve the new resource. In a script or in code polling is a good way to wait for this to happen.
Eventually, we get this:
$ kubectl get crd databases.example.com -o yaml
apiVersion: apiextensions.k8s.io/v1beta1
kind: CustomResourceDefinition
metadata:
creationTimestamp: 2017-08-09T09:21:43Z
name: databases.example.com
resourceVersion: "792"
selfLink: /apis/apiextensions.k8s.io/v1beta1/customresourcedefinitions/databases.example.com
uid: 28c94a05-7ce4-11e7-888c-42010a9a0fd5
spec:
group: example.com
names:
kind: Database
listKind: DatabaseList
plural: databases
singular: database
scope: Namespaced
version: v1
status:
acceptedNames:
kind: Database
listKind: DatabaseList
plural: databases
singular: database
conditions:
- lastTransitionTime: null
message: no conflicts found
reason: NoConflicts
status: "True"
type: NamesAccepted
- lastTransitionTime: 2017-08-09T09:21:43Z
message: the initial names have been accepted
reason: InitialNamesAccepted
status: "True"
type: Established
Above, you can see that kubectl has picked up the CRD we defined earlier and is able to provide status information about it; all names are accepted without a conflict and that the CRD is established, that is, the API Server serves it now.
Discovering and Using CRDs
After proxying the Kubernetes API locally using kubectl proxy we can discover the database CRD we defined in the previous step like so:
$ http 127.0.0.1:8001/apis/example.com
HTTP/1.1 200 OK
Content-Length: 223
Content-Type: application/json
Date: Wed, 09 Aug 2017 09:25:44 GMT
{
"apiVersion": "v1",
"kind": "APIGroup",
"name": "example.com",
"preferredVersion": {
"groupVersion": "example.com/v1",
"version": "v1"
},
"serverAddressByClientCIDRs": null,
"versions": [
{
"groupVersion": "example.com/v1",
"version": "v1"
}
]
}
Note that kubectl caches discovery content by default for 10 minutes, using the ~/.kube/cache/discovery directory. Also, it can take up to 10 minutes for kubectl to see a new resource, such as the CRD we defined about. However, on a cache miss—that is, when kubectl can not identify the resource name in a command—it will immediately re-discover it.
Next, we want to use an instance of the CRD:
$ cat wordpress-database.yaml
apiVersion: example.com/v1
kind: Database
metadata:
name: wordpress
spec:
user: wp
password: secret
encoding: unicode
$ kubectl create -f wordpress-databases.yaml
database "wordpress" created
$ kubectl get databases.example.com NAME KIND wordpress Database.v1.example.com
To monitor the resource creation and updates directly via the API, you can use a watch on a certain resourceVersion (as discussed in part 2. First, we’ll discover the resourceVersion of the database CRD we defined and then use curl to watch changes to the resource, in a separate shell session:
$ http 127.0.0.1:8001/apis/example.com/v1/namespaces/default/databases
HTTP/1.1 200 OK
Content-Length: 593
Content-Type: application/json
Date: Wed, 09 Aug 2017 09:38:49 GMT
{ "apiVersion": "example.com/v1", "items": [ { "apiVersion": "example.com/v1", "kind": "Database", "metadata": { "clusterName": "", "creationTimestamp": "2017-08-09T09:38:30Z", "deletionGracePeriodSeconds": null, "deletionTimestamp": null, "name": "wordpress", "namespace": "default", "resourceVersion": "2154", "selfLink": "/apis/example.com/v1/namespaces/default/databases/wordpress", "uid": "8101a7af-7ce6-11e7-888c-42010a9a0fd5" }, "spec": { "encoding": "unicode", "password": "secret", "user": "wp" } } ], "kind": "DatabaseList", "metadata": { "resourceVersion": "2179", "selfLink": "/apis/example.com/v1/namespaces/default/databases" } }
So here we find that our CRD resource /apis/example.com/v1/namespaces/default/databases/wordpres is in fact in "resourceVersion": "2154" currently and this is what we will use for the watch with curl:
$ curl -f 127.0.0.1:8001/apis/example.com/v1/namespaces/default/databases?watch=true&resourceVersion=2154
Now we open a new shell session and delete the wordpress CRD resource; we can see the notification from the watch then in the original session:
$ kubectl delete databases.example.com/wordpress
Note: We could have also used kubectl delete database wordpress because there is no pre-defined database resource in Kubernetes. Moreover, the singular word database is the spec.name.singular field in our CRD, automatically derived following the English grammar.
In the original session—where you launched the curl watch command—you can now see a live update from the API server:
{"type":"DELETED","object":{"apiVersion":"example.com/v1","kind":"Database","metadata":{"clusterName":"","creationTimestamp":"2017-0[0/515]
:38:30Z","deletionGracePeriodSeconds":null,"deletionTimestamp":null,"name":"wordpress","namespace":"default","resourceVersion":"2154","selfLink":"/apis/example.com/v1/namespaces/
default/databases/wordpress","uid":"8101a7af-7ce6-11e7-888c-42010a9a0fd5"},"spec":{"encoding":"unicode","password":"secret","user":"wp"}}}
Taken together, using three shell sessions (an additional one for the initial kube proxy command at the bottom) the above commands and respective outputs look as follows:
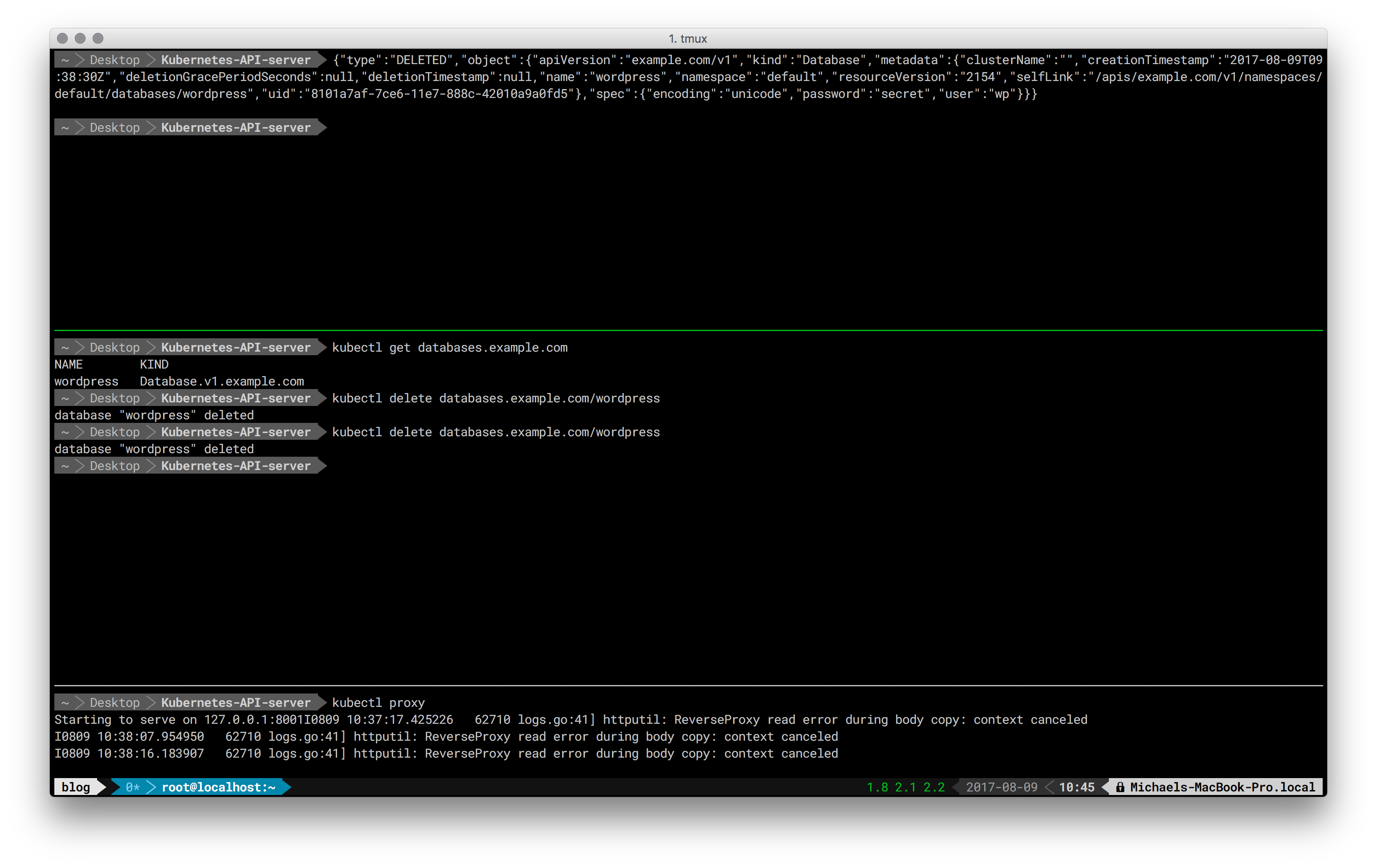
Finally, let’s have a look how the respective data of the database CRD is stored in etcd. In the following we’re accessing etcd, on the master node, directly via its HTTP API:
$ curl -s localhost:2379/v2/keys/registry/example.com/databases/default | jq .
{
"action": "get",
"node": {
"key": "/registry/example.com/databases/default",
"dir": true,
"nodes": [
{
"key": "/registry/example.com/databases/default/wordpress",
"value": "{\"apiVersion\":\"example.com/v1\",\"kind\":\"Database\",\"metadata\":{\"clusterName\":\"\",\"creationTimestamp\":\"2017-08-09T14:53:40Z\",\"deletionGracePeriodSeconds\":null,\"deletionTimestamp\":null,\"name\":\"wordpress\",\"namespace\":\"default\",\"selfLink\":\"\",\"uid\":\"8837f788-7d12-11e7-9d28-080027390640\"},\"spec\":{\"encoding\":\"unicode\",\"password\":\"secret\",\"user\":\"wp\"}}\n",
"modifiedIndex": 670,
"createdIndex": 670
}
],
"modifiedIndex": 670,
"createdIndex": 670
}
}
As you can see from the etcd resource dump above, the CRD data is essentially an uninterpreted blob.
Note that when deleting the CRD, all instances will be deleted as well, that is, it is a cascading delete operation.
Current State, Limitations, and Future of CRDs
At the moment, we have Kubernetes 1.7 as the stable release version and are expecting 1.8 landing by the beginning of October 2017. In this context, the state of CRDs is as follows:
- CRDs started to replace
ThirdPartyResources(TPRs) in Kubernetes 1.7 and TPRs will be removed for good in Kubernetes 1.8. - A simple migration path for TPRs to CRDs exists.
- A single version per CRD is supported, however, multiple versions per group are possible.
- CRDs present a consistent API and are basically indistinguishable from native resources from the user point of view.
- CRDs are a stable basis for more features coming in the following versions, for example:
- For validation with JSON-Schema, you can check out the CRD validation proposal
- Garbage collection in 1.8
Now that you’ve seen how to use CRDs, let’s discuss their limitations:
- They do not provide the capability for version conversion, that is, only one version is possible per CRD (it is not expected to see conversion support near- or mid-term).
- There is no validation currently but might land in 1.8, see this Google Summer of Code project. and limited validation expressiveness with upcoming JSON Schema (not Turing complete).
- No fast, in-process admission possible (but initializers and admission webhooks are supported)
- You can not define sub-resources, for example,
scaleorstatus, however there's a proposal for it on the way. - Last but not least, CRDs currently do not support defaulting, that is, assigning default values to certain fields (this might come in one of the following versions).
In order to address the above issues and have a more flexible way to extend Kubernetes, you can use User API Servers (UAS), running in parallel to the main API Server. We will go into detail on writing UASs in one of the next installments of this blog post series. Next time around we will complete the CRD by writing a custom controller for it.
About the authors
More like this
Why Operational Resilience and Digital Sovereignty Top the CIO Agenda
How Red Hat OpenShift 4.22 impacts enterprise AI’s bottom line
Crack the Cloud_Open | Command Line Heroes
Edge computing covered and diced | Technically Speaking
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds