
Performance and Scalability have never been more important to ensure the best user experience. Whether for e-commerce, AI/ML jobs or business critical information gathering, no one likes it when an application has a poor response time. Performance and Scalability makes or breaks deals.
While we know how important performance and scale are, how can we engineer for it when chaos becomes common in complex systems? What role does Chaos/Resiliency testing play during Performance and Scalability evaluation? Let’s look at the methodology that we need to embrace to mimic a real world production environment to find the bottlenecks and fix them before it impacts the users and customers.
You may think that performance and scale can only be tested in stable, disruption-free environments. While control is needed to make sure the data is comparable to previous benchmark tests, chaos is still important. In fact, it is necessary to create chaos and failures to get close to real world conditions.
When running applications on a distributed system, there are various failures that might occur. For example: the network can go down, the application might restart because of issues due to load, the disk might run out of IOPS leading to IO saturation and if we talk about Kubernetes/OpenShift, the control plane might not perform well when masters and control plane components encounter failures at load. If the system does not recover gracefully, the problems need to be investigated and fixed ASAP. This is exactly why organizations have SLA’s (Service Level Agreements) in place with 97-99% as the uptime for example instead of 100% to take failures into account.
SLAs also mean that downtime must be minimized, so we need to make sure the system/application is resilient enough to handle the failures. Performance, Scalability and Chaos/Reliability may seem to be different fields, but in reality they go hand-in-hand. Let’s take a look at how we handle these problems when testing OpenShift.
Release the Kraken!
We, the Performance and Scalability team at Red Hat, are working on a tool called Kraken to inject deliberate failures and create chaos in an OpenShift environment. It leverages its built-in recovery checking features and Cerberus to determine whether OpenShift was able to handle the failures. An excellent blog by my colleagues Paige Rubendall and Yashashree Suresh walks through Kraken and the supported scenarios. It also includes a demo on its functionality.
What’s the goal of Kraken? How different is it from other chaos tools?
The goal behind building Kraken is to make sure the Kubernetes/OpenShift components under chaos not only recover but do not degrade in terms of performance and scale during and after failure injection. Being the team having access to large and dense OpenShift clusters, we find ourselves dealing with the Performance and Scalability analysis and debugging of various components starting with control plane to networking, kubelet, router, storage, cluster maximums, etc. We have a large number of data points, tunings and an in-depth understanding of the bottlenecks. There are many tools out there that can help with creating chaos but do not take Performance and Scalability into consideration for determining the pass/fail. To bridge that gap, we are leveraging and reusing them as much as possible with an “upstream first approach” in mind and adding the performance and scale knowledge to it in addition to the scenarios that are specific to OpenShift.
Performance and Scalability Monitoring With Kraken
Kraken supports deploying cluster monitoring by installing mutable Grafana on top of OpenShift with custom dashboards that we use for analyzing large and dense clusters at scale. It leverages Performance-dashboards under the hood that we heavily rely on during the Performance and Scale testing of Kubernetes/OpenShift. We can use this feature in Kraken to monitor the state of the cluster and find out the bottlenecks.
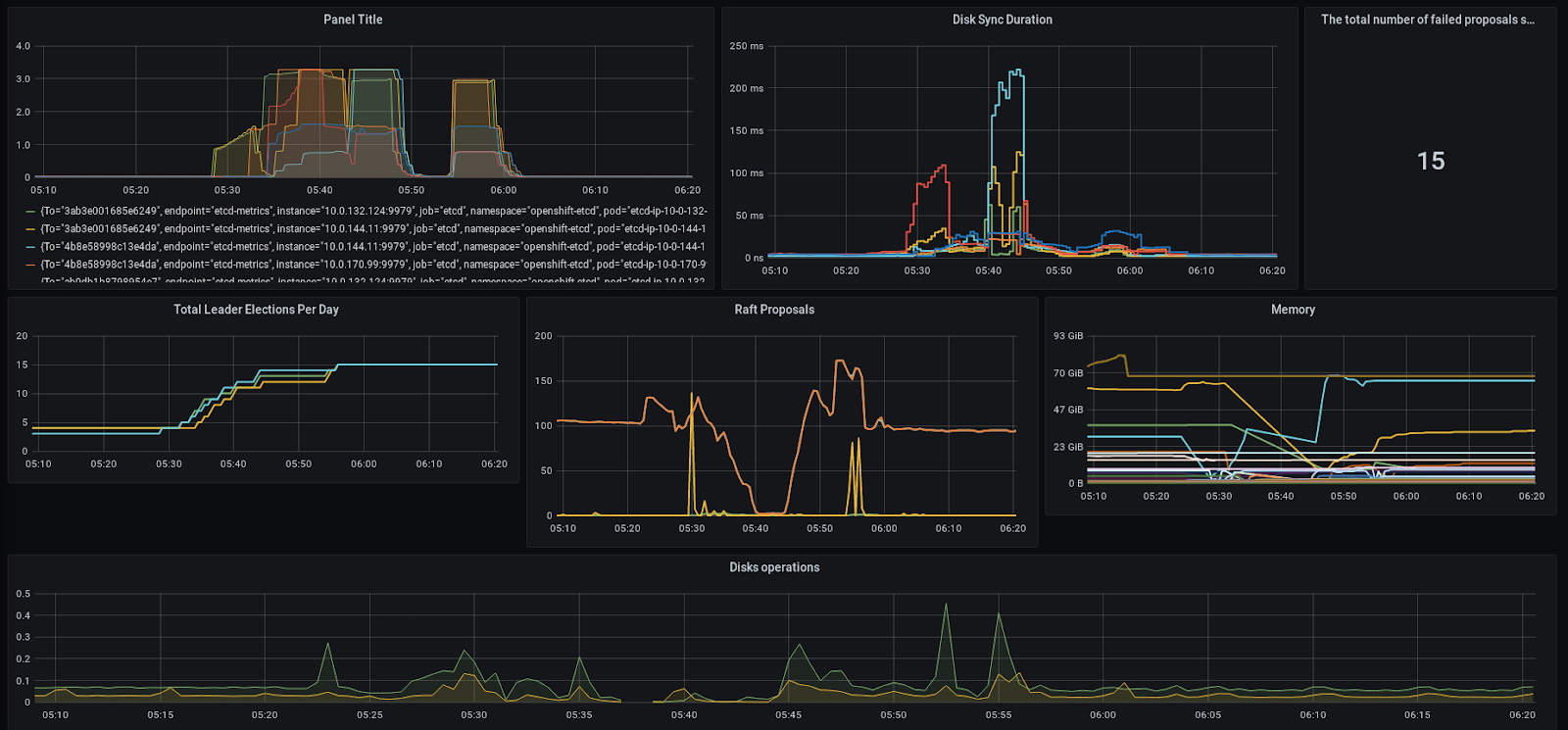
Kraken provides dashboards for API, Etcd performance and overall cluster state. Here are a couple of things we can check for in the dashboards during the chaos:
- Tracking the Etcd state during disk and network saturation.
- Checking for memory leaks during crashes and restarts.
- Making sure the control plane is stable when creating failures around master nodes/components by checking if there’s no disruption in processing the requests from the client.
- Checking if the API differentiates and throttles the requests from a rogue application while still prioritizing system requests for cluster stability.
- Making sure resource intensive applications like Prometheus and Elasticsearch can handle forced crashes and restarts well without taking down the node and many more!
These are just a couple of examples related to the Kubernetes/OpenShift platform performance and reliability. Similar things can be done with respect to user applications to make sure they are ready for running in a production environment where failures are bound to happen.
What’s next?
We are planning to add support in Kraken to be able to query the cluster monitoring system - Prometheus given a metrics profile i.e a file with a list of metrics that will evaluate the performance, state of the component/cluster and pass/fail the run based on them. This is inspired from one of the tools - Kube-burner that we heavily rely on in our scale test runs to load a cluster given a configuration. The plan is to ship profiles which encapsulate the Performance and Scalability knowledge gained by our team from years of experience to help achieve the goal.
In summary, we looked at the methodology and how we can leverage Kraken to ensure that the Kubernetes/OpenShift is reliable, performant and scalable. We do this by providing the ability to inject failures, check on the progress of recovery, and monitoring the state and performance of the cluster/component. Do give Kraken a try and feel free to open issues and enhancement ideas on github. Any feedback or contributions are most welcome and appreciated. We would love to hear from you.
Embrace chaos and make it part of your environment!
About the author
Naga Ravi Chaitanya Elluri leads the Chaos Engineering efforts at Red Hat with a focus on improving the resilience, performance and scalability of Kubernetes and making sure the platform and the applications running on it perform well under turbulent conditions. His interest lies in the cloud and distributed computing space and he has contributed to various open source projects.
More like this
The agentic paradox and the case for hybrid AI
Context-aware advisor recommendations in Red Hat Lightspeed
Crack the Cloud_Open | Command Line Heroes
Edge computing covered and diced | Technically Speaking
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds