Insights Advisor for OpenShift is an application included with Red Hat OpenShift subscriptions, integrated into the Hybrid Cloud Console and offering OpenShift users a set of recommendations to identify and prevent potential issues before your cluster is impacted. Even better, the tool offers a set of remediation steps to prevent the issue, or in the worst case, mitigate it when already present on the cluster. The recommendations have different criticality levels. Those that are labeled as “critical” directly impact your clusters performance and availability and have to be resolved immediately, while those labeled as “important” have high potential for similar impact, and we strongly recommend resolving them as soon as possible. Recommendations labeled as “moderate” require you to reconsider your configuration, and “low” are more informative, suggesting optimizations for your setup.
To be able to quickly act on these important and critical recommendations, one needs first to be aware that a recommendation of such criticality is present in your cluster. In this blog post, we will describe two ways to get instantly notified about Insights Advisor important and critical events. Information about all Insights events are integrated into OpenShift WebConsole (4.8+), Advanced Cluster Management (2.3+), and OpenShift Cluster Manager.
For more details about the integrations and how recommendations are created, see blogs on OpenShift Insights for OpenShift Cluster Manager or Your OpenShift Cluster, Health Checks, Insights, and You.
Hybrid Cloud Console Notifications
All the tools mentioned have different notification mechanisms, and you can pick and choose the one that suits your use case. Let’s start with OpenShift Cluster manager. The Hybrid Cloud Console comes with features that are available to all services. Notifications is one of them. In the notifications settings, the notifications admin can set different ways for how users within the organization will be notified. Each user can decide if her or she wants to receive those notifications by enabling them in the User Preferences.
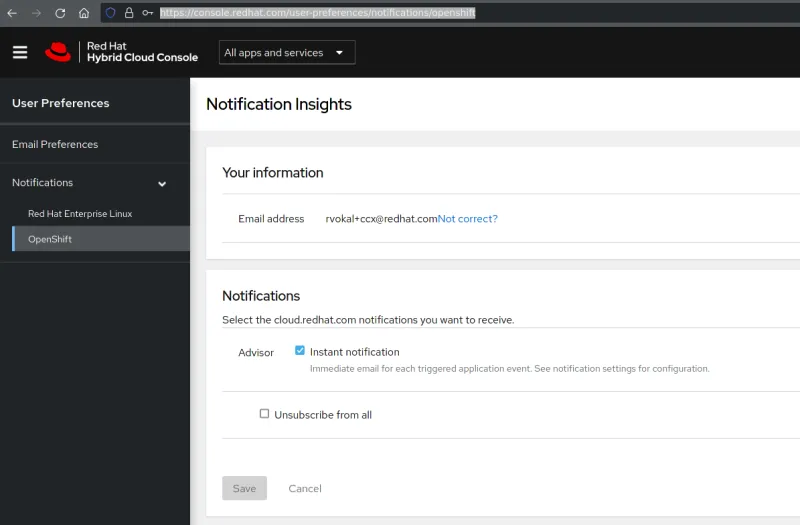
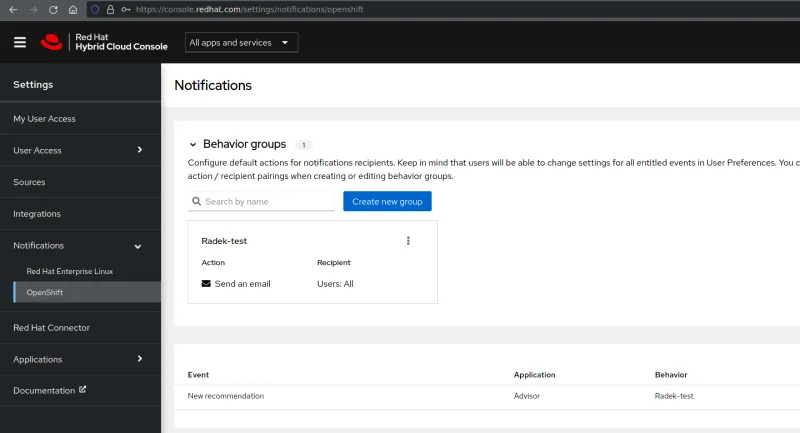
The notifications administrators can create a default action for each application, which the Hybrid Cloud Console calls a “behavior group.” They can create a new Behavior by selecting the Settings icon in the Hybrid Cloud Console, then Notifications, and then OpenShift. This allows them to specify whether email notifications will be sent or whether they can configure a webhook for a third-party tool, ticketing system, or instant messaging. The example below shows creation of a test group used to send emails when a new OpenShift Advisor Recommendation is found.
Now that the notification is set, the important or critical recommendations hitting any clusters in your account will send a one-time email similar to the one below to all the users that enabled the instant notifications in their User preferences.

The notification indicates a new recommendation available, provides its name and criticality, and links to OpenShift Cluster Manager where the user can find more details about the recommendation as well as remediation steps to resolve it. That was quick, easy, and the problem is gone.
Find more information about the Notifications service, and read about its integration with Insights Drift Service for RHEL here.
Alerts
The second option to get notified about Insights events is to watch metrics from the insights-operator on your OpenShift cluster. Insights-operator collects data required for Advisor analysis and also has metrics that give us the number of currently available recommendations for each risk severity. This approach does not give as much detailed information about each recommendation as the Advisor service, and the user still has to go to OpenShift Cluster manager to find all the details and remediations. The advantage here is that you can use your existing AlertManager configuration to process this alert.
First, you have to define the alert and store it as a .yaml file. In the example below, we created an alert for a “critical” Insights alert, but you can replace “critical” with “important,”“moderate,” or “low” based on your needs.:
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
name: insights-alert-critical
namespace: openshift-insights
spec:
groups:
- name: health_statuses_insights
rules:
- alert: CriticalInsightsAlert
expr: health_statuses_insights{metric="critical"} > 0
labels:
severity: critical
annotations:
summary: Critical Insights alert found
Next, you need to apply this new alert on your cluster:
$> oc apply -f ./alert.yaml
Additionally, you can go directly to OpenShift WebConsole -> Monitoring and run this promql query:
increase(health_statuses_insights{metric="moderate"}[10m]) > 0
This query will start triggering an alert for 10 minutes after the new Insights rule appears, and then the alert should go away. Learn more about defining and managing alerts in OpenShift in the Managing Alerts section of the documentation.
We highly recommend setting up one of these notifications for your cluster to prevent potential problems that might impact your cluster and application performance, availability, and security. Insights Advisor recommendations are updated frequently by our subject matter experts, based on input from our product and support engineers and also field people. Insights Advisor is a way we share our experience with running OpenShift internally or for our customers with everyone. We would love to hear about your experience with Insights Advisor, notifications, or alerts and other features we offer. Please reach out by sending email to insights@redhat.com or by joining customer discussions on access.redhat.com portal.
About the author

Radek Vokal started with Red Hat in 2004 as a software engineer, later lead team responsible for core Red Hat Enteprirse Linux components and core Kubernetes teams. Currently he is the Senior Manager of Product Management for Insights OpenShift services and is based in Brno, Czech Republic.
More like this
Looking ahead to 2026: Red Hat’s view across the hybrid cloud
Red Hat to acquire Chatterbox Labs: Frequently Asked Questions
Data Security 101 | Compiler
AI Is Changing The Threat Landscape | Compiler
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds