
In today's increasingly distributed system landscape, ensuring comprehensive application observability has become a difficult task, especially when machines and clusters are geographically dispersed. In this blog post, I'll address the complexity of this challenge and outline possible solutions using Red Hat OpenShift Distributed Tracing Data Collection (Documentation) 2.8. Cost comparison between self-hosted and SaaS solutions is not discussed here because it depends on the team size, expected data, and other factors.
What is Red Hat OpenShift Distributed Tracing Data Collection?
Red Hat OpenShift distributed tracing includes a new product for trace and observability data collection. This product is currently available as a Technology Preview, which means users can already install and try it while it is being developed and tested. We are adding more functionality every day. In the current version, 2.8, we support collecting distributed tracing data; we are also adding the ability to collect OTLP metrics in the upcoming 2.9 release.
The product itself is based on the OpenTelemetry project and consists of a specification, provided SDKs, and various collector components, making it ideal for observability data collection in distributed systems.
Why based on OpenTelemetry?
OpenTelemetry, an incubating CNCF project since 2019, is a powerful open source observability framework that standardizes the collection, aggregation, and export of telemetry data from various sources, enabling comprehensive visibility into the health, performance, and behavior of distributed applications and systems. Due to the specification and modular structure of the OpenTelemetry collector and the adaptation of various vendors, OpenTelemetry is perfectly suited for the correlation of logs, metrics and traces, as well as collection of vendor-neutral data.
Why cross-cluster observability?
Creation of dedicated observability clusters to store and analyze telemetry data from multiple clusters offers several advantages and is often essential when operating many edge (especially far edge) clusters. However, opting for and running such a solution is affected by various factors.
When you store telemetry data in a single cluster, you get a comprehensive view of the health, performance, and behavior of your infrastructure. Especially when clusters are communicating with each other, this unified view enables the identification of patterns, correlations, and anomalies across clusters, allowing for effective troubleshooting and optimisation. Transferring this data to a central location using a vendor-neutral data collection suite not only makes the lives of administrators and developers easier, it also simplifies future migrations.
Storing telemetry data in a single cluster might have some disadvantages: Such a setup introduces a single point of failure. Data privacy and compliance requirements, multiplied by the volume of incoming data, might demand more complex traffic and access management. As the infrastructure grows, scaling a single observability cluster to handle the increased data load and resource demands might become challenging.
Since OpenTelemetry allows subsequent migration between its own observability cluster and various third-party providers, I'll focus on the OpenShift solution here.
If you prefer video content to learn more about OpenTelemetry and see examples of setting up an observability environment, check out the presentation Observability at the edge: Monitoring edge environments at scale from the Red Hat Summit 2023 conference.
How to configure a telemetry toolchain
In the following sections, I'll describe how to use Red Hat OpenShift Distributed Tracing Data Collection to send telemetry data from a remote cluster and receive it securely in the desired observability cluster. For simplicity, I'm focusing here on the transmission and storing of trace data.
The following graphic shows two clusters having a separate observability namespace. In the observability cluster, an OpenTelemetry collector is operated there as a receiver and made publicly available by OpenTelemetry Operator. In remote Cluster 1, an OpenTelemetry collector is operated in the gateway mode.
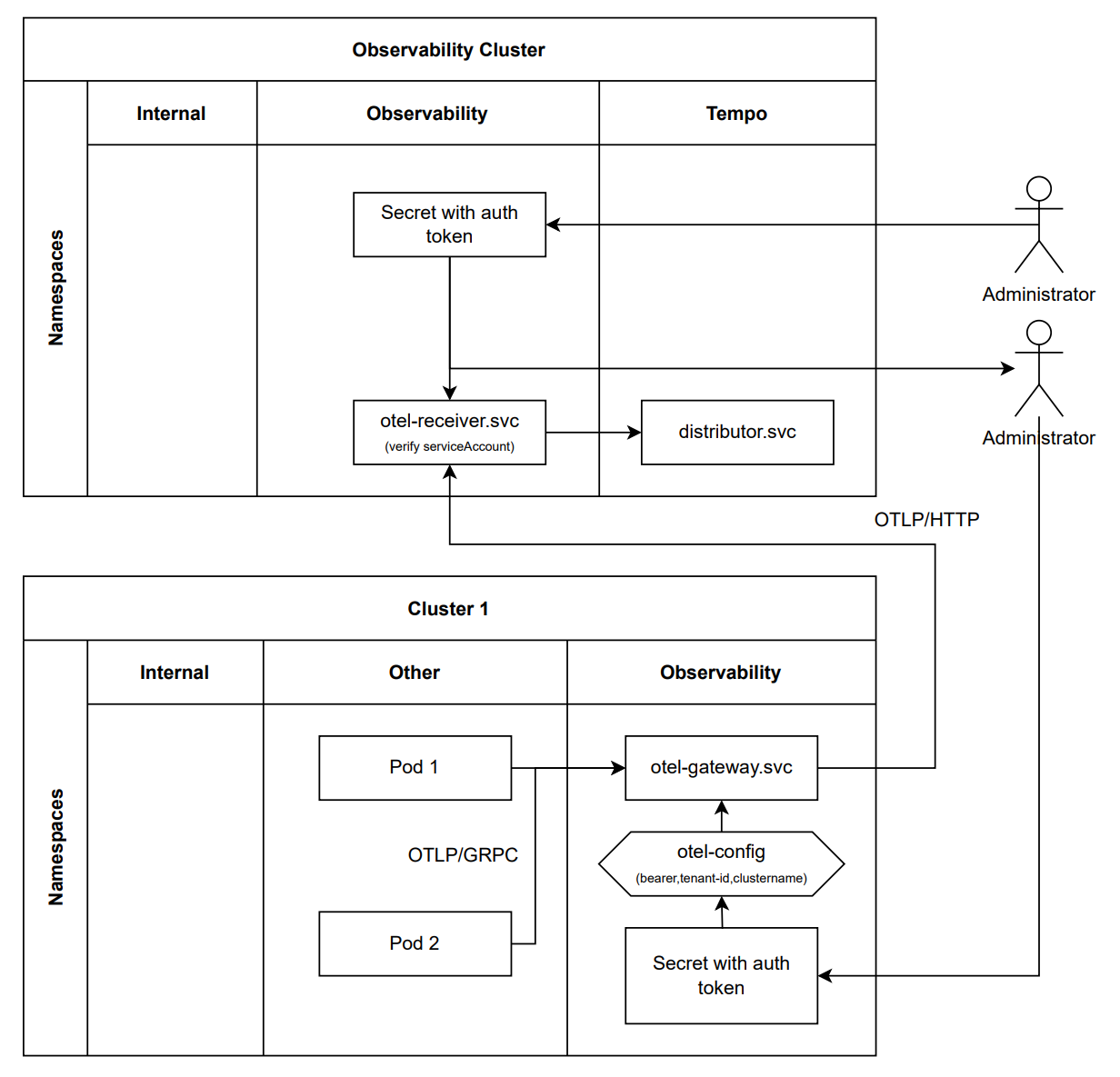
Data is sent between the two clusters via a connection established by the Open Telemetry collector on the remote Cluster 1 side. To check whether the remote collector is authorized to transmit data, you can choose between different options:
- A bearer token extension, which can be used in combination with a serviceAccount with the RHOSDT 2.9 release
- A Basic HTTP authentication extension that validates a username/password combination
- Built-in mTLS that verifies an incoming connection based on provided certificates
All the examples shown below are based on OpenShift using Basic HTTP authentication and TLS. If you are searching for a guide on how to expose the OpenTelemetry Collector on Kubernetes, read this.
Prerequisites
- Access to two OpenShift v4.10+ clusters
- A domain name pointing to an observability cluster
- Red Hat OpenShift Distributed Tracing Data Collection v2.8+ installed on both clusters
- Cert Manager Operator for OpenShift installed on the observability cluster
TIP: To be able to authenticate later, create a Secret with the username and password in both clusters:
apiVersion: v1
kind: Secret
metadata:
name: my-credentials
type: Opaque
data:
# username is ingest base64 encoded.
username: aW5nZXN0Cg==
# password is “c2VjZXJ0Cg==” (secret base64 encoded) base64 encoded
password: YzJWalpYSjBDZz09CG==
Optional
If you are using Red Hat OpenShift Distributed Tracing Data Collection in version 2.9 or higher, you can use the bearer token extension for authentication. The configuration is similar to the HTTP Basic Authentication extension.
extensions:
bearertokenauth:
token: "somerandomtoken"
filename: "file-containing.token"
bearertokenauth/withscheme:
scheme: "Bearer"
token: "randomtoken"
It works in a simple way: This extension compares the transmitted token with the one on the collecting site. In combination with a serviceAccount token, this allows you to manage the access on the Observability cluster site.
Note: OpenShift 4.11 serviceAccount tokens have an expiry date of 1h by default, unlike the exchanged basic authentication credentials. To learn more about Long-Lived and Time-Bound tokens, check Understanding service accounts and tokens in Kubernetes.
Collecting and sending telemetry data
Start by creating the OpenTelemetry collector on remote Cluster 1. The aim is to generate trace data with the help of telemetrygen and transmit it to the OpenTelemetry Collector, which serves as a gateway.

The gateway will then enrich the trace data with additional information, such as the original cluster name (in this case Cluster 1), and securely transmit the received data to the observability cluster.
The resourcedetection processor identifies the cluster in which the collector is running by connecting to the OpenShift infrastructure API. To allow this, a service account must first be created for the collector. The collector is then assigned a ClusterRole with the required permissions:
apiVersion: v1
kind: ServiceAccount
metadata:
name: otel-collector-gateway
namespace: observability
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: otel-collector-gateway
rules:
- apiGroups: ["config.openshift.io"]
resources: ["infrastructures"]
verbs: ["get", "watch", "list"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: otel-collector
subjects:
- kind: ServiceAccount
name: otel-collector-gateway
namespace: otel-collector-example
roleRef:
kind: ClusterRole
name: otel-collector
apiGroup: rbac.authorization.k8s.io
Next, create a gateway collector with the help of the OpenTelemetryCollector CR. Assign the previously created serviceAccount to this gateway collector to retrieve infrastructure information from the OpenShift API. Since this collector serves as a gateway for enriching data and handling authentication, use the daemonset mode here. Transmitted telemetry data can be exported directly from each node. The credentials are taken from the Secret that you created in the Prerequisites section. The main part of this CR consists of the collector configuration, which is stored as a string on the config entry. The available configurations can be found in the official OpenTelemetry Collector documentation.
apiVersion: opentelemetry.io/v1alpha1
kind: OpenTelemetryCollector
metadata:
name: otel-gateway
namespace: observability
spec:
mode: daemonset
serviceAccount: otel-collector-gateway
env:
- name: BASIC_AUTH_USERNAME
valueFrom:
secretKeyRef:
name: my-credentials
key: username
- name: BASIC_AUTH_PASSWORD
valueFrom:
secretKeyRef:
name: my-credentials
key: password
config: |
extensions:
basicauth/client:
client_auth:
username: ${env:BASIC_AUTH_USERNAME}
password: ${env:BASIC_AUTH_PASSWORD}
receivers:
opencensus:
otlp:
protocols:
grpc:
http:
zipkin:
processors:
batch:
k8sattributes:
memory_limiter:
check_interval: 1s
limit_percentage: 50
spike_limit_percentage: 30
resourcedetection:
detectors: [openshift]
exporters:
otlphttp:
endpoint: "https://observability-cluster.com:443"
tls:
insecure: false
ca_file: /etc/pki/ca-trust/source/service-ca/service-ca.crt
service:
extensions: [basicauth/client]
pipelines:
traces:
receivers: [opencensus, otlp, zipkin]
processors: [memory_limiter, k8sattributes, resourcedetection, batch]
exporters: [otlphttp]
To simulate generation of telemetry data, create a pod that generates data and transmits it to your gateway into the "traces" pipeline.
apiVersion: v1
kind: Pod
metadata:
name: telemetrygen
namespace: default
spec:
containers:
- name: telemetrygen-traces
image: ghcr.io/open-telemetry/opentelemetry-collector-contrib/telemetrygen:v0.80.0
args: [
"traces",
"--otlp-insecure",
"--rate=1",
"--otlp-endpoint=otel-collector-gateway.observability.svc.cluster.local"
]
Receiving telemetry data
Then switch to the observability cluster. To provide valid certificates for your specified domain, use cert-manager and the service of Let's Encrypt.
The cert-manager CRDs, which include the ClusterIssuer resource, are not available by default in OpenShift, so make sure that cert-manager is installed. Cert-manager allows you to request certificates from a Certificate Authority (CA) easily. To use those requested certificates, you only need to add the acme.cert-manager.io/http01-ingress-class: openshift-default annotation to your OpenTelemetryCollector CR.
apiVersion: cert-manager.io/v1
kind: ClusterIssuer
metadata:
name: letsencrypt-staging
namespace: observability
spec:
acme:
preferredChain: ""
privateKeySecretRef:
name: private-key-lets-encrypt
server: https://acme-staging-v02.api.letsencrypt.org/directory
solvers:
- http01:
ingress:
class: openshift-default
Next, create an OpenTelemetry collector on the receiver side. The Basic HTTP authentication credentials are again taken from the Secret that was created at the beginning. With the help of the ingress entry, you can make the configured OTLP/HTTP receiver available outside of the observability cluster.
apiVersion: opentelemetry.io/v1alpha1
kind: OpenTelemetryCollector
metadata:
name: otlp-receiver
namespace: observability
spec:
mode: "deployment"
ingress:
type: route
hostname: "observability-cluster.com"
annotations:
acme.cert-manager.io/http01-ingress-class: openshift-default
route:
# Value "edge" indicates that encryption should be terminated at the edge router.
# Alternative options are: "insecure", "passthrough" and "reencrypt".
termination: "edge"
config: |
receivers:
otlp:
protocols:
http:
exporters:
logging:
otlp: # NOTE: enabled for testing in the final step
endpoint: "jaeger.observability.svc.cluster.local:4317"
tls:
insecure: true
service:
pipelines:
traces:
receivers: [otlp]
processors: []
exporters: [logging]
Looking at the pipeline section of the OpenTelemetryCollector CR, note that only the logging exporter is used for termination. This makes it easier to check that traces are actually transmitted.
Distributing telemetry data
Finally, you can redirect transmitted telemetry data to a desired backend storage. Since we are focusing on transmission of traces in this example, an all-in-one Jaeger instance is created, which receives and visualizes all trace information.
apiVersion: v1
kind: Service
metadata:
name: jaeger
namespace: observability
spec:
ports:
- name: "16686"
port: 16686
targetPort: 16686
- name: "4317"
port: 4317
targetPort: 4317
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: jaeger
namespace: observability
spec:
template:
spec:
containers:
- env:
- name: COLLECTOR_OTLP_ENABLED
value: "true"
- name: LOG_LEVEL
value: debug
image: jaegertracing/all-in-one:v1.47.0
name: jaeger
ports:
- containerPort: 16686
hostPort: 16686
protocol: TCP
- containerPort: 4317
hostPort: 4317
protocol: TCP
Then, replace the logging exporter in the service section of the otlp-receiver CR with the already specified otlp exporter that points to jaeger.observability.svc.cluster.local:4317.
Afterwards, make the Jaeger-UI locally accessible by running oc port-foward and visiting 127.0.0.1:16686.
oc port-forward -n observability svc/jaeger 16686:16686
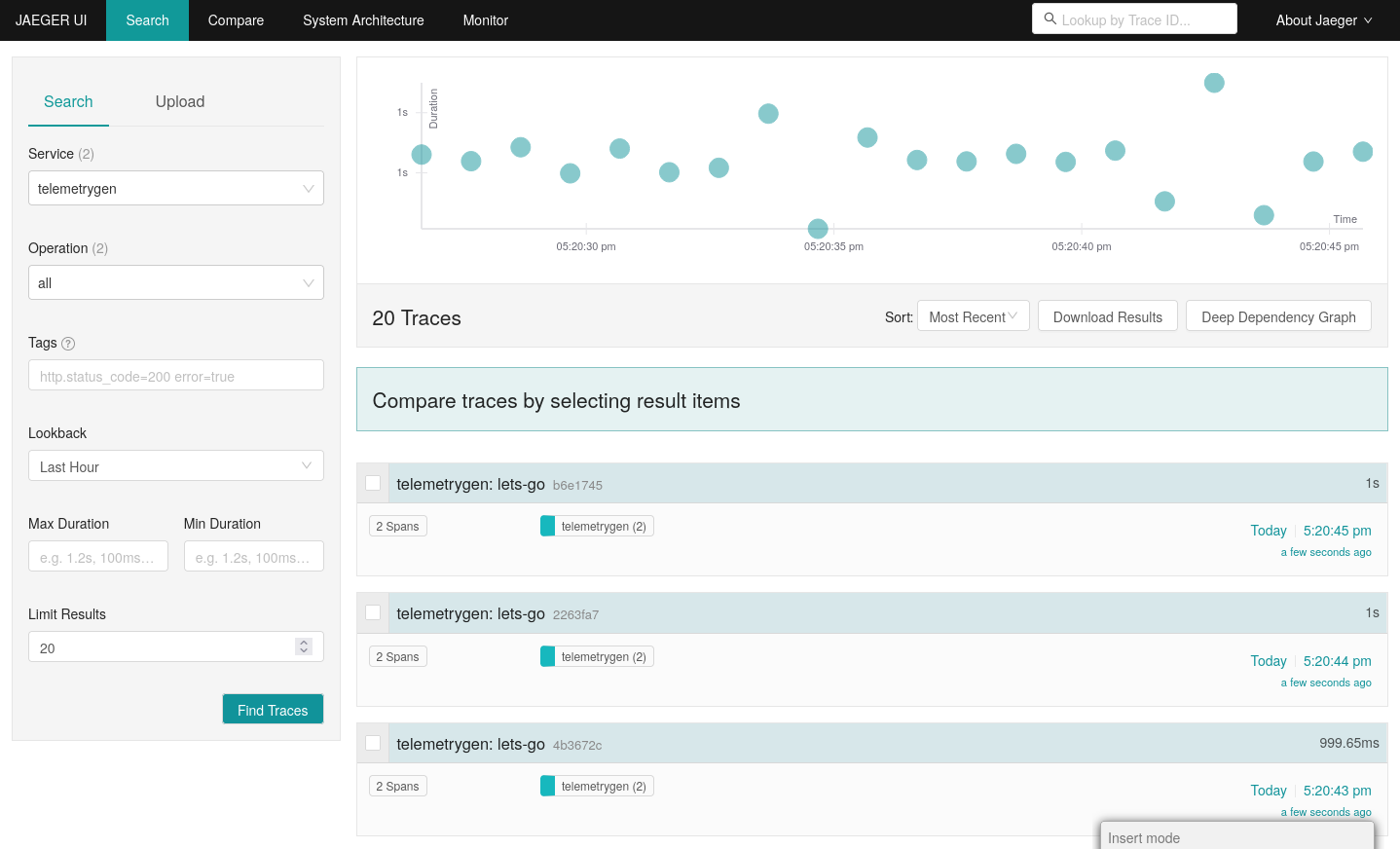
The result is a view similar to this:
Summary
In this blog post, I explored using the Red Hat OpenShift Distributed Tracing Data Collection beyond its own cluster boundary. With cross-cluster observability, you gain a comprehensive understanding of your distributed systems helping you to understand the big picture of your infrastructure. I provided an example on how to enrich the data on a remote cluster, transmit it in a secure way, and prepare it for analysis.
Furthermore, we are planning to team up with Red Hat Advanced Cluster Management for Kubernetes (ACM) to help you configure, maintain consistency and visualize distributed tracing data across a fleet of clusters from a single place. Stay tuned!
Note that the Jaeger all-in-one instance is a representative for any other trace backend that can receive data via OTLP/gRPC like Tempo.
About the author
More like this
Why Operational Resilience and Digital Sovereignty Top the CIO Agenda
How Red Hat OpenShift 4.22 impacts enterprise AI’s bottom line
Crack the Cloud_Open | Command Line Heroes
Edge computing covered and diced | Technically Speaking
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds