With the release of OpenShift 4.6, we are adding support for a new deployment topology at the Edge: Remote Worker Nodes (or RWN, because we all love acronyms). This topology, combined with the three nodes clusters, which we described in a previous blog post, is the second of three that we believe are needed for OpenShift to be the platform on which you can ubiquitously run dynamic workloads regardless of where the edge is or use case.
But what are remote worker nodes and where can they be used? The remote worker node topology is comprised of both control (or supervisor) nodes and worker nodes; however, they are physically separate from each other with supervisory nodes located in often larger sites (like a regional or central data center) and worker nodes distributed across smaller edge sites. What this creates is an architecture where the supervisor nodes can manage up to thousands of edge locations as a single environment, sharing those cores to maximize the workloads running at the edge.
The remote work node topology enables a more efficient use of resources as worker nodes can be used in their entirety for workloads. A preview of this functionality has been available in OpenShift for more than a year now, but before making it fully supported, we wanted to make sure that we had extensively tested and documented their use at the edge to ensure that they delivered expected results as a highly scalable architecture with centralized management, which is exactly what you need in edge use cases. These tests are now done, and the documentation is complete, providing you with a full picture of the benefits and caveats of the topology. However, here is a quick summary of some things to note (but please do read the documentation carefully for additional details):
- First, we recommend that the connectivity between the edge site and the control plane is stable to ensure management of the worker nodes. However, if you were to lose connectivity temporarily, it is no big deal as the active workloads on the worker nodes will just keep on running for the duration of the connectivity break. But if the worker node server was to be rebooted during this outage, workloads will not be restored unless you implement some additional work-arounds, which are listed in the documentation. Obviously, during the outage, it will not be possible to launch any additional workload there either.
- Second, as Kubernetes only currently supports one machine operator type per cluster, the control plane and the worker nodes must be deployed in the same way. You cannot, for example, have some worker nodes running on bare metal and others on a virtualization platform, unless you deploy all of them by bypassing the machine operator mechanism using bare-metal User Provided Infrastructure (UPI).
- Third, latency spikes or temporary reduction in throughput between supervisor and worker nodes can negatively impact your cluster. Lower bandwidth will increase the time it takes to perform certain operations that require exchanges with the control planes, such as downloading a new version of a container. We recommend that the latency between the control plane and the edge site be under 200 ms; however, we have not determined a minimal bandwidth requirement between supervisor and worker nodes, but we recommend you be aware of your available bandwidth and make sure it aligns with your specific requirements.
Apart from the above, a remote worker and a standard worker node are absolutely equivalent in terms of functionality. This includes running OpenShift Virtualization workloads if you deployed RWN on a physical server. The memory and core usage are also completely identical, and you do not need any additional tools to manage workloads running on RWN than you would use in a normal cluster. You can also easily add more than one node to a site if you need to.
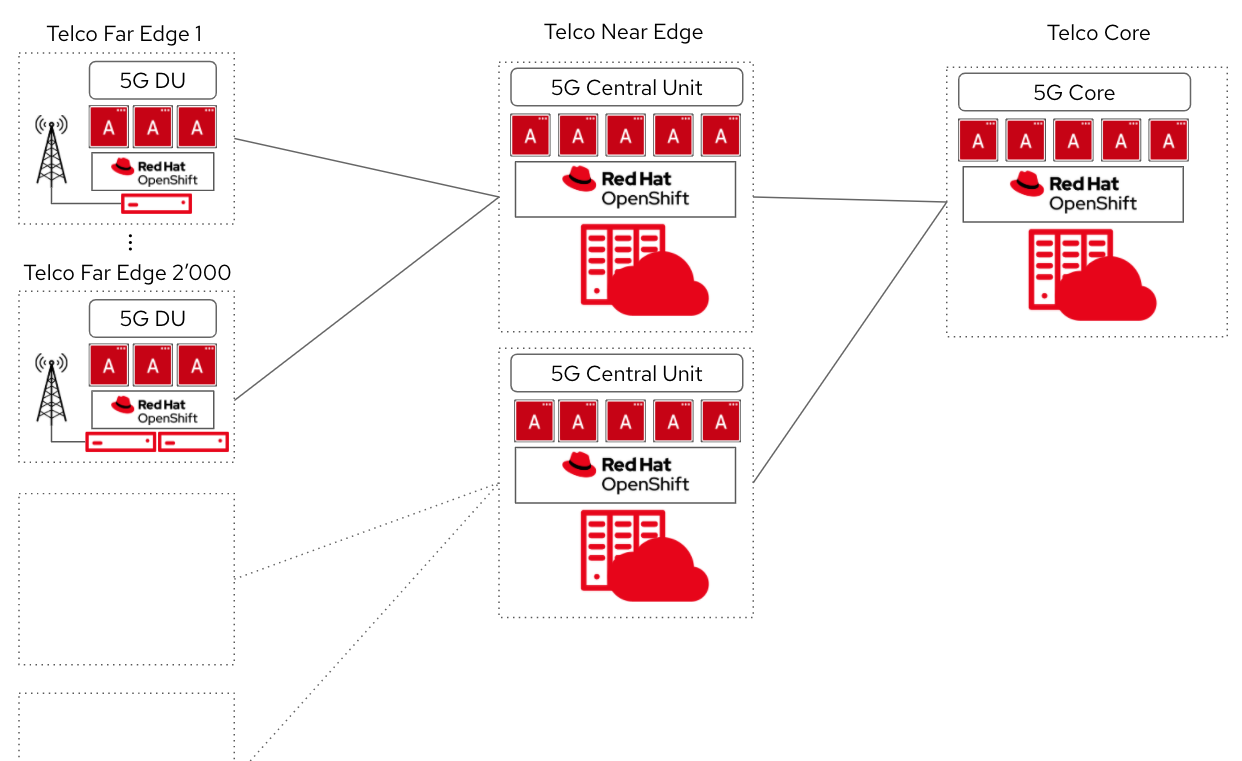
A typical use case for remote worker nodes is a telco 5G network in a dense area. The 5G RAN deployment generally calls for Central Units (CU) to control up to a couple thousands Distributed Units (DU). In dense areas, the connectivity between the CU and DU is generally redundant and abundant, and operators want to maximise the numbers of cores deployed for their payloads. Avoiding the mobilization of multiple cores on each site for running a local control plane, when multiplied by a thousands, is very cost effective and still meets their strict service standards.
What is next? Now that this is done, our engineering is hard at work putting together a robust solution that will provide for those use cases where you have to run workloads on a single server in sites where connectivity is an issue. This is the third topology we alluded to at the beginning of this blog. Because of its ability to continue to operate when disconnected from a central site, it will come with the overhead of having to run a control plane on each one of these servers. However, we believe that their built-in continuity will be great in many use cases.
So now that you have a better understanding of how remote worker nodes works, we want to share with you a table to help you identify which topology is best suited for your environment:
| 3+ Nodes | Remote Worker Node | Single Node | |
| I have a critical workload; I need a highly available solution | X | (x)1 | |
| I need to have full control of my workloads while disconnected | X | X | |
| I need to maximize my number of cores used for my workload | X | X | |
| I need to easy grow my number of nodes in the same cluster | X | X | |
| Each of my sites has a different type of deployment | X | X | |
| I have strong physical space constraints | X | X |
[1] Requires at least two remote worker nodes on the same site.
To learn more, please visit www.openshift.com/edge. And check out our other Edge announcement, today: Red Hat Enterprise Linux 8.3 is ready for the edge.
More like this
Closing the gap: Bringing AI and Kubernetes to the source of the data
AI in telco – the catalyst for scaling digital business
What Can Video Games Teach Us About Edge Computing? | Compiler
How Do Roads Become Smarter? | Compiler
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds