OpenShift virtualization, formerly Container-native Virtualization, has been introduced previously as a feature of OpenShift (and the upstream project for Kubernetes: KubeVirt part one and two) which implements the deployment and management of virtual machines utilizing Kubernetes constructs, such as PVCs and pods. Seamlessly integrating the world of virtualization and containers is no small engineering feat, however the implementation uses the same familiar and trusted Linux technology stack that has existed for many years, built on a foundation of Red Hat Enterprise Linux and KVM.
Let’s take a deeper look at the technology behind OpenShift virtualization and how it’s simplifying the integration of virtual machine-based and container-based application components into a single solution that works for both.
Compute
Containers use Linux Kernel technology, specifically namespaces and cgroups, to provide isolation and resource control to a process. Normally, we think of those processes as being something like Python, Java, or an application binary, but they can, in reality, be any process like bash or even system tools like Emacs or vim.
Virtual machines, when viewed from the perspective of the hypervisor, are also processes. Rather than being an application process, it’s a KVM process which is responsible for the virtual machine’s execution.

The container image brings with it all of the tools, libraries, and binaries needed for the KVM virtual machine. If we were to inspect the pod for a running virtual machine, we see the qemu-kvm processes and helpers. Additionally, we have access to KVM-centric tools for managing VMs like qemu-img, qemu-nbd, and virsh.


Since the virtual machine is a pod, it inherits all of the functionality of a pod from Kubernetes. Scheduling guidelines like taints, tolerations, affinity, anti-affinity, and benefits of pods like high availability all apply automatically just like with non-VM pods. However one difference is that pods are not migrated from host to host in the same way that we would usually expect a virtual machine. If a node is drained, we would expect the pods to be terminated and rescheduled to other nodes in the cluster. With a virtual machine it’s usually expected that a live migration happens.
To accommodate this, a live migration CRD was created with the specific task of initializing, monitoring, and managing live migrations of virtual machines between worker nodes.
apiVersion: kubevirt.io/v1alpha3
kind: VirtualMachineInstanceMigration
metadata:
name: migration-job
spec:
vmiName: fedora
When cordoning a node, virtual machines which have an eviction strategy of LiveMigration will automatically have migration tasks created for them. This also gives the application team the option of controlling the behavior of their virtual machines. Does it need live migration? Yes? Then great it’s there! Can I treat my VM like a container and have it be terminated and rescheduled? That works too!
Network
Every Kubernetes deployment uses a software-defined network (SDN) technology to provide connectivity between pods and nodes. OpenShift is no exception and has used OpenShiftSDN as the default since OpenShift 3. However, OpenShift 4 introduced a new feature, known as Multus, which allows multiple networks to be made available and for pods to be connected to multiple networks simultaneously.

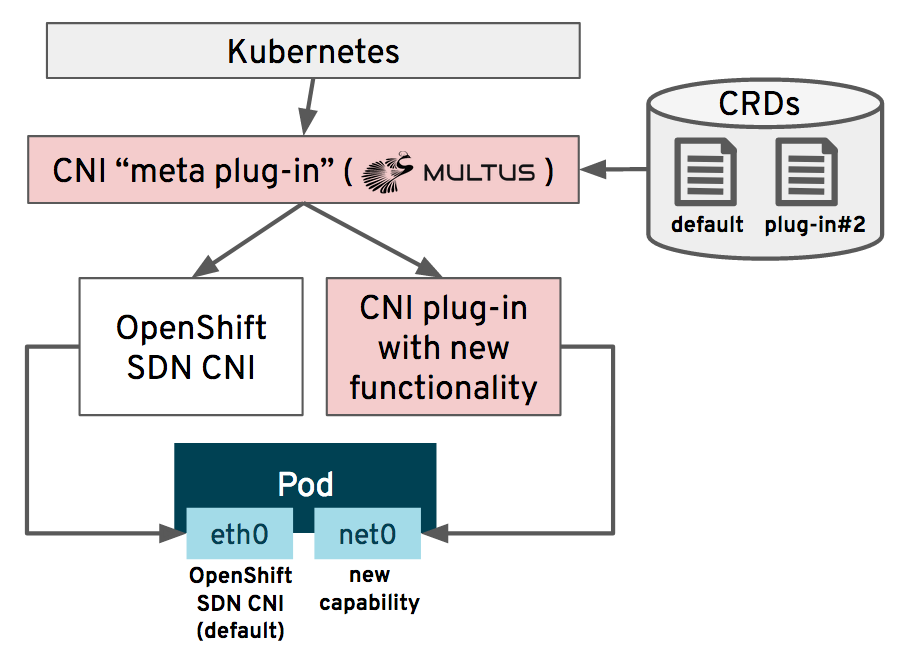
Administrators use Multus to define additional CNI networks, which are then deployed and configured to the cluster by the network operator. The pods then connect to one or more of those networks, typically the default OpenShiftSDN and an additional interface. SR-IOV devices, standard Linux host bridges, MACVLAN and IPVLAN devices are all possible, depending on the needs of your virtual machine. Below we see a Multus CNI definition for a bridge network using the eth1 interface:
apiVersion: operator.openshift.io/v1
kind: Network
metadata:
name: cluster
spec:
additionalNetworks:
- name: multus1
rawCNIConfig: '{ "cniVersion": "0.3.1", "type": "bridge", "master": "eth1", "ipam":
{ "type": "static", "addresses": [ { "address": "191.168.1.1/24" } ] } }'
type: Raw
For a OpenShift virtualization pod, this means that the VM can be directly connected to an external network without having to rely solely on the SDN for external connectivity. This is an important capability for virtual machines which have been migrated from another environment, such as Red Hat Virtualization or VMware vSphere, since it means that the connectivity doesn’t change so long as the layer 2 network is still accessible to the OpenShift worker nodes. It also means that virtual machines can have consistent connectivity for IP persistence, high throughput devices, and/or dedicated resources such as a guest initiated storage device without having to traverse the SDN’s ingress/egress path.
For more information on creating and connecting OpenShift virtualization VMs to networks, please see the documentation here. Additionally, the nmstate operator is deployed as a part of OpenShift virtualization, providing another familiar way of creating and managing network configuration on the physical workers being used for hypervisors.
Storage
OpenShift virtualization uses the native Kubernetes storage concepts of StorageClasses, PersistentVolumeClaims (PVC), and PersistentVolumes (PV), all connected using the standard storage protocols supported by Kubernetes, to attach and manage VM disks. This creates a consistent and familiar method for Kubernetes administrators and application teams to manage both containers and virtual machines. For virtualization administrators, this is a concept that many are already familiar with as it’s the same principle used by OpenStack and many cloud providers for managing the VM’s definition and storage separately.
Attaching drives to virtual machines is often more than simply creating the disk and attaching it though. Oftentimes it’s faster and easier than creating new and is a requirement when importing existing virtual machines to use an existing disk. Whether it’s a template KVM image or a disk from another hypervisor, it’s much faster than having to install the OS from nothing.
To simplify the process, OpenShift virtualization deploys the Containerized Data Importer (CDI) project, which makes importing disk images from multiple sources as easy as an annotation to the PVC.
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: "fedora-disk0"
labels:
app: containerized-data-importer
annotations:
cdi.kubevirt.io/storage.import.endpoint: "http://10.0.0.1/images/Fedora-Cloud-Base-31-1.9.x86_64.qcow2"
spec:
storageClassName: ocs-gold
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 20Gi
The annotation triggers CDI to take action, at which point we will see a series of actions happen, as seen below:

When CDI is done, the PVC contains the disk for the virtual machine and it’s ready to be used, including any format conversion that may have needed to happen.
OpenShift Container Storage (OCS), Red Hat’s Ceph-based solution for container persistence, also provides significant value when used with OpenShift virtualization. In addition to the standard PVC access methods of RWO (block) and RWX (file), OCS provides RWX raw block devices, which can be used to provide shared block access for performance sensitive applications. Additionally, OCS supports the emerging object bucket claim standard, allowing applications to request and use object storage directly.
VMs in containers
If you’re interested in testing and experimenting with integrating your applications hosted in virtual machines with OpenShift virtualization, it is available as a tech preview in OpenShift 3.11 or later. If you are a current OpenShift customer you have access to it as part of your current subscription, there is no additional cost or entitlement needed. OpenShift 4.4 and OpenShift virtualization 2.3 are the most current versions as of this writing, if you’re using something earlier you should consider upgrading to get the newest functionality. The fully supported, generally available version of OpenShift virtualization is targeted for the second half of calendar year 2020.
For more information, be sure to visit the OpenShift documentation for installation instructions, including how to configure Multus for external networking. If you have any questions, please leave a comment below!
About the author

More like this
The virtualization pivot and why enterprise IT’s next move will determine the next decade
Strengthening the enterprise foundation: Red Hat and Oracle’s expanding collaboration
Crack the Cloud_Open | Command Line Heroes
Edge computing covered and diced | Technically Speaking
Browse by channel

Automation
The latest on IT automation for tech, teams, and environments

Artificial intelligence
Updates on the platforms that free customers to run AI workloads anywhere

Open hybrid cloud
Explore how we build a more flexible future with hybrid cloud

Security
The latest on how we reduce risks across environments and technologies

Edge computing
Updates on the platforms that simplify operations at the edge

Infrastructure
The latest on the world’s leading enterprise Linux platform

Applications
Inside our solutions to the toughest application challenges
Virtualization
The future of enterprise virtualization for your workloads on-premise or across clouds